
Give your agents the power to remember
Imagine your agent never asks the same question twice. Until now, most agents have been stateless. Each conversation resets to zero, forgetting what users said just minutes ago or weeks ago. Developers tried to bridge this gap with homegrown solutions — storing embeddings in databases, manually retrieving prior messages, or stuffing entire chat histories into prompts. These workarounds add latency, cost, and complexity, and still fall short of delivering truly personal, context-aware interactions.
At Ignite 2025, we introduced the public preview of memory in Foundry Agent Service — a fully managed, long-term memory store natively integrated with our agent service. Memory empowers developers to seamlessly store, retrieve, and manage chat summaries, user preferences and critical context across sessions, devices, and workflows. With secure, high-quality memory, agents can deliver richer, more personalized experiences out-of-the-box. This unlocks more natural interactions and sustained engagement across your applications.
Developer-first: fast prototyping to enterprise scale
Start fast, scale seamlessly: Build a prototype in minutes with out-of-the-box configuration, then scale easily to support millions of users and memories as your needs grow.
State-of-the-art quality: Memory in Foundry Agent Service delivers outstanding performance from day one. We continually develop and apply the latest state-of-the-art techniques, so your agents benefit from the latest advances in memory retrieval, relevance, and personalization.
Unified API, flexible backends: Use a unified interface to access your Foundry’s managed service or bring your own storage in the future. You get advanced retrieval, memory extraction, and consolidation — without added complexity.
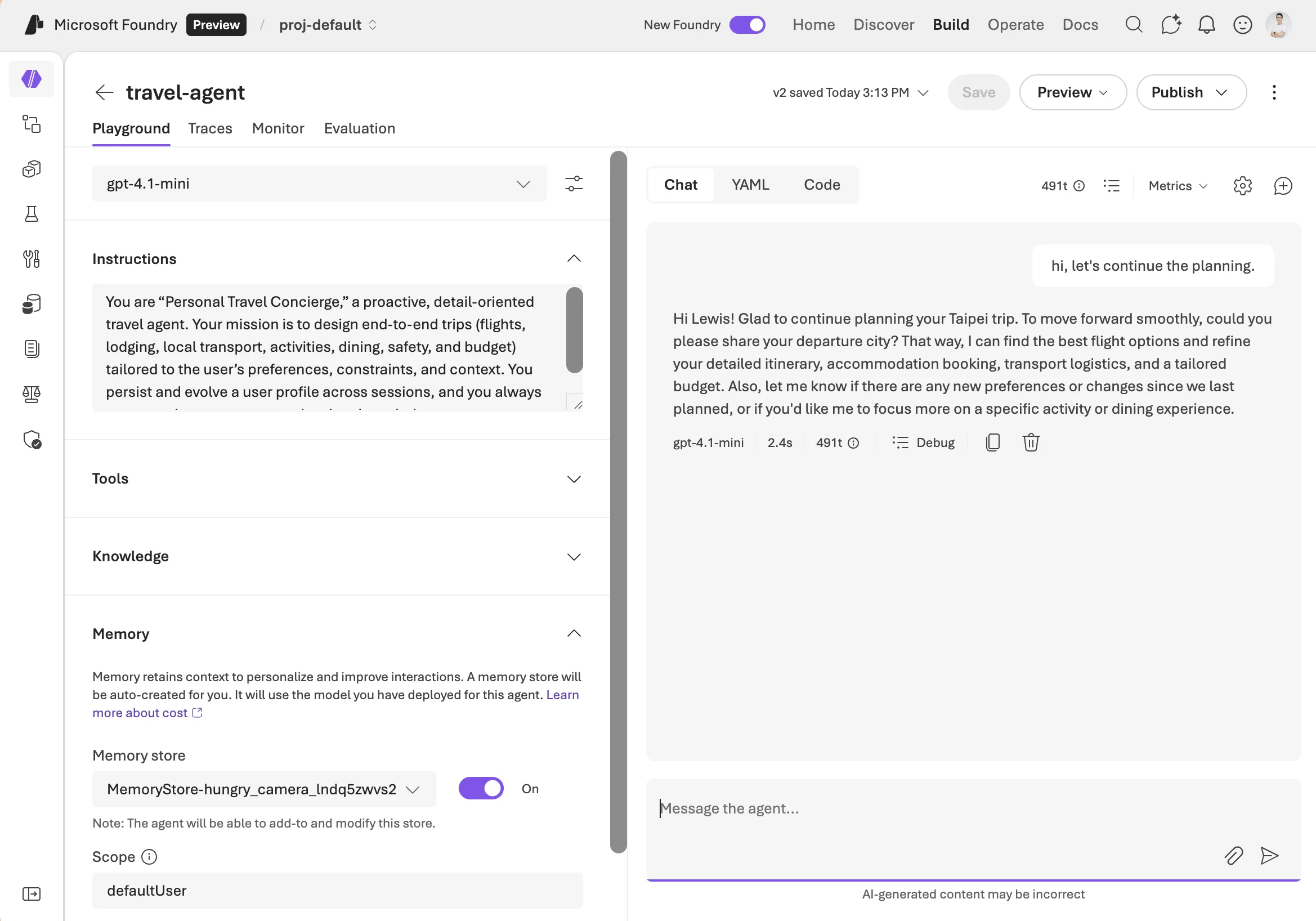
In the Foundry portal, you can enable the memory feature with a single click. A memory store will be automatically created and configured for your agent. For advanced configurations or customizations, you can leverage our APIs and SDKs to get started.
# Python sample
# Create a memory store
memory_store_name = "my_memory_store"
definition = MemoryStoreDefaultDefinition(
chat_model="gpt-4.1",
embedding_model="text-embedding-3-small",
options=MemoryStoreDefaultOptions(
user_profile_enabled=True,
user_profile_details="Food preferences for a meal planning agent",
chat_summary_enabled=True
),
)
memory_store = project_client.memory_stores.create(
name=memory_store_name,
description="Example memory store for conversations",
definition=definition,
)
# Add memories to the memory store
scope = "user123"
user_message = ResponsesUserMessageItemParam(
content="I prefer dark roast coffee and usually drink it in the morning"
)
update_poller = project_client.memory_stores.begin_update_memories(
name=memory_store.name,
scope=scope,
items=[user_message],
update_delay=0,
)
update_result = update_poller.result()
# Retrieve memories from the memory store
query_message = ResponsesUserMessageItemParam(content="What are my coffee preferences?")
search_response = project_client.memory_stores.search_memories(
name=memory_store.name,
scope=scope,
items=[query_message],
options=MemorySearchOptions(max_memories=5),
)
# Retrieve user profiles, typically you only need to call this once
search_response = project_client.memory_stores.search_memories(
name=memory_store.name,
scope=scope
) Memory behind the scenes
The memory in Foundry Agent Service enables agents to deliver seamless, context-rich experiences by managing memory in several phases for optimal performance:
- Extract what matters: When a user interacts with an agent, the system actively extracts key information such as user preferences, facts, and relevant context from the conversation. For example, preferences like “allergic to dairy” and facts about recent activities are identified and stored.
- Consolidate to keep things clean: Extracted memories are consolidated to keep the memory store efficient and relevant. We use LLMs to merge similar or duplicate topics, so the agent doesn’t store redundant information. Conflicting facts are detected (e.g., a new allergy) are resolved to maintain a single, accurate memory.
- Retrieve where needed: When the agent needs to recall information, it uses hybrid search techniques to find the most relevant memories. This allows the agent to quickly surface the right context, making conversations feel natural and informed. Core memories (like allergies, favorite products, or recurring requests) are retrieved at the beginning of a conversation, so the agent is immediately aware of the user’s core needs.
- Customize the memory for your use case: Developers can guide the memory store using the user_profile_details parameter to specify important topics. The system translates these cues into instructions for the underlying model, shaping how memory extraction, consolidation, and retrieval are performed. This flexibility ensures agents to focus on what matters most for your application.
Here is an example of how memory can improve and personalize integration between a recipe agent and a user who expressed a food allergy in the past.

Our approach to quality
When building memory in the Foundry Agent Service, we use rigorous techniques to deliver the best quality and performance. We rely on precise evaluation frameworks and iterative refinement to ensure that memory persistence and retrieval meet the highest standards. While we recognize that many existing public benchmark datasets have limitations, we address these by curating datasets that test different aspects of memory, from semantic fact recall to user preferences, and applying the resulting knowledge about the user to new situations.
Our memory systematically extracts both user profile information and chat summaries from conversation histories. This approach preserves key information and details from past conversations, striving for faithfulness to the original contexts.
At its core, memory personalizes and streamlines interactions with agents, making conversations more natural and effective. Our evaluations measure the end-to-end quality of agents equipped with memory compared to those without — focusing on real-world scenarios. In recent tests, agents with memory in Foundry Agent Service achieved state-of-the-art and competitive performance on common memory benchmarks.
The memory space is evolving rapidly, and we are committed to pushing the boundary. We continuously invest in research, experimentation, and feedback-driven improvements.
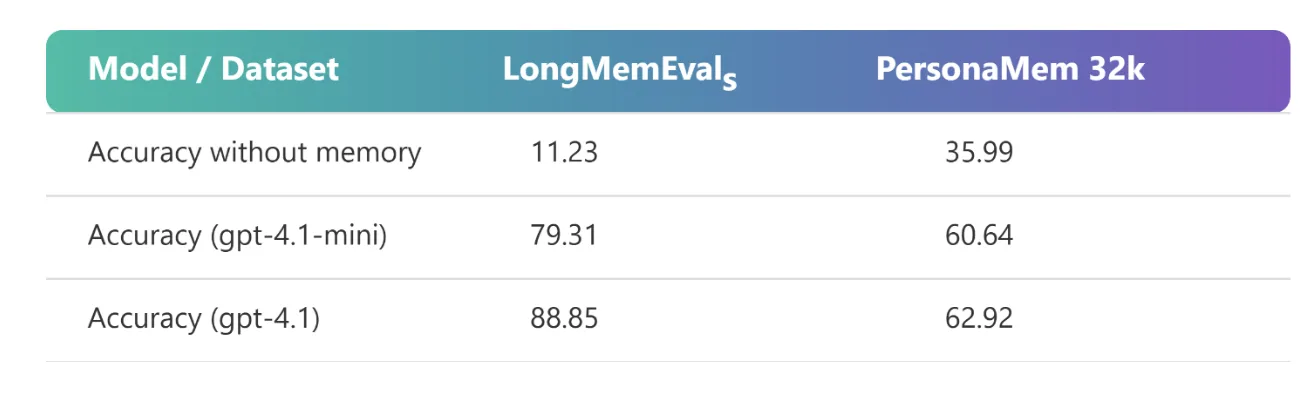
* Accuracies are macro-averages
* All results reported using text-embedding-3-small
Get Started
Memory in Foundry Agent Service is now in public preview. Whether you’re building your first agent or scaling to thousands, you can start prototyping today.
If you’re watching Microsoft Ignite 2025 on-demand content later, be sure to check out these sessions:
0 comments