

Foundry Local is a high-performance local AI runtime stack that brings Azure AI Foundry’s power to client devices. Foundry Local lets you build and ship cross-platform AI apps that run models with acceleration on a wide range of hardware.
The Evolution of AI Acceleration
On-device AI has progressed rapidly. Early workloads ran on CPUs, but performance and power limits made real-time inference difficult. GPUs improved things with parallelism, faster inference. The latest breakthrough is NPUs (Neural Processing Units), designed specifically for neural networks. NPUs deliver far greater efficiency and throughput, making advanced models practical on desktop and mobile applications. This shift enables AI that is faster, more energy-efficient, and privacy-preserving — without constant reliance on the cloud.
What’s New
With the release of Foundry Local v0.7, we are pleased to announce expanded NPU support, now including Intel and AMD NPUs on Windows 11. We are also continuing to make Foundry Local improvements for NVIDIA and Qualcomm silicon, in partnership with our silicon partners. Furthermore, leveraging Windows ML, Foundry Local automatically detects users’ silicon across NPU, GPU, and CPU and downloads the appropriate execution providers, removing the necessity for these to be bundled with Foundry Local.
Get Started
On Windows
- Open Windows Terminal
- Install Foundry Local using winget
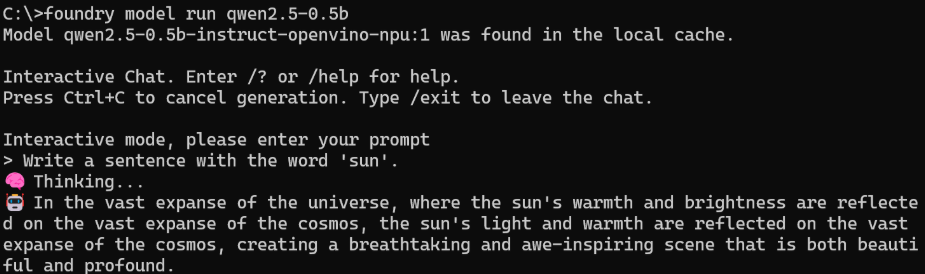
winget install Microsoft.FoundryLocal - Run a model
foundry model run qwen2.5-0.5b
On MacOS
- Open Terminal
- Install Foundry Local
brew tap microsoft/foundrylocal brew install foundrylocal - Run a model
foundry model run qwen2.5-0.5b
For more information, check out Foundry Local documentation and samples here.
For developers interested in bringing their own models to Windows, check out Windows ML now available in general availability.
0 comments