
Today, we’re introducing a powerful new way to bring AI directly to your mobile apps: Foundry Local on Android. Starting now, you can build Android applications that run AI on-device—no cloud round trips required. Sign up for the gated preview here: https://aka.ms/foundrylocal-androidprp
Most of us now carry a computer in our pocket. These devices are now powerful enough to run AI models locally, unlocking speed, privacy, and flexibility. With Foundry Local, you can easily deploy optimized open-source models from Microsoft Foundry directly on mobile devices.
Why on-device AI matters:
- Adds an extra layer of privacy for sensitive scenarios like healthcare or financial data
- Minimizes costs by reducing cloud calls
- Enables offline or low connectivity operations
- Avoids unnecessary round trips over the internet
Foundry Local on Android opens up massive reach for developers, making AI even more accessible to everyone. We’ve been working closely with select customers in preview, including PhonePe, who have integrated Foundry Local into their mobile app—serving more than 618 million users—to power an upcoming AI-driven experience inside their digital payments platform.
“The [Foundry Local] SDK allows us to leverage models on device without having to go to the server or the internet” — Gautham Krishnamurthy, Head of Product, Consumer Platform, PhonePe
On-Device Speech-to-Text (Powered by Whisper)
We’re announcing a new Speech API in Foundry Local. Apps can transcribe and understand speech with low latency and no audio leaves the device by default.
We’re excited about this powerful new capability because it unlocks so many customer scenarios—where voice prompting in offline environments is critical for a seamless, intuitive UX. Imagine filling out forms or capturing notes – instantly and assisted by AI – with voice, even when connectivity is poor or intermittent.
Here’s a quick snippet showing how to acquire a Whisper model from the Foundry Catalog, load it into memory, and transcribe audio:
var model = await catalog.GetModelAsync("whisper-tiny")
// Download the model (the method skips download if already cached)
await model.DownloadAsync(progress =>
{
Console.Write($"\rDownloading model: {progress:F2}%");
if (progress >= 100f)
{
Console.WriteLine();
}
});
// Load the model
await model.LoadAsync();
// Get an audio client
var audioClient = await model.GetAudioClientAsync();
// Get a transcription with streaming outputs
var response = audioClient.TranscribeAudioStreamingAsync("Recording.mp3", ct);
await foreach (var chunk in response)
{
Console.Write(chunk.Text);
Console.Out.Flush();
}
Console.WriteLine();
Try speech-to-text on Foundry Local by following our documentation: https://aka.ms/foundrylocal-audiodocs
The new Foundry Local SDK
The new Foundry SDK delivers:
- Self-contained packaging mechanism – no need to install separate executables for model serving.
- Smaller package and runtime footprint.
- Simple API – just a few lines to download and load models.
- APIs for chat completions and audio transcription that follow OpenAI request/response
- Optional OpenAI compliant web server to integrate other tools and frameworks (for example, LangChain, OpenAI SDK, Web UI).
- Integration with Windows ML for smart device detection.
These are exactly what our preview customers asked for and more.
Getting started is easy – see the sample snippet of code below that demonstrates how to acquire a Qwen model from the Foundry Catalog, load the model into memory and do chat completions. The Foundry Local SDK will automatically select the most performant model for the device hardware and ensure that all the hardware runtime and drivers are installed on the device. See Foundry Local in action in this episode of Microsoft Mechanics: https://aka.ms/FL_IGNITE_MSMechanics
// Get a model using an alias
var model = await catalog.GetModelAsync("qwen2.5-0.5b");
// Download the model (the method skips download if already cached)
await model.DownloadAsync(progress =>
{
Console.Write($"\rDownloading model: {progress:F2}%");
if (progress >= 100f)
{
Console.WriteLine();
}
});
// Load the model
await model.LoadAsync();
// Get a chat client
var chatClient = await model.GetChatClientAsync();
// Create a chat message
List<ChatMessage> messages = new()
{
new ChatMessage { Role = "user", Content = "Why is the sky blue?" }
};
var streamingResponse = chatClient.CompleteChatStreamingAsync(messages, ct);
await foreach (var chunk in streamingResponse)
{
Console.Write(chunk.Choices[0].Message.Content);
Console.Out.Flush();
}
Console.WriteLine();
// Tidy up - unload the model
await model.UnloadAsync();
Get started here: https://aka.ms/foundrylocalSDK
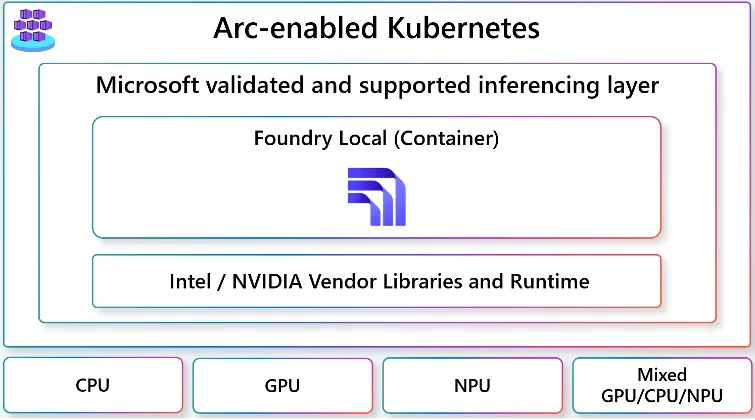
Foundry Local with Arc-enabled Kubernetes
On-device AI isn’t limited to personal computing devices. Many of our customers need to run AI in containers on-premises, often in environments with limited connectivity or specialized hardware.
Today, we’re excited to share a sneak peek of Foundry Local for edge, hybrid, sovereign, and disconnected scenarios, powered by Azure Arc.
This capability extends the Foundry Local experience beyond dev/test machines, enabling customers to seamlessly deploy what they’ve validated to edge environments, such as manufacturing rigs or industrial machinery operating with intermittent connectivity. It is delivered by making Foundry Local available in a container orchestrated by Arc-enabled Kubernetes and running on Azure Local, providing a fully managed Microsoft stack for edge, hybrid, sovereign, and disconnected environments.
Ready to try it out? Join our gated preview list to get notified when it’s available: https://aka.ms/FL-K8s-Preview-Signup
What’s next
On-device AI is an exciting and rapidly evolving space. Partners like NimbleEdge and early customers like PhonePe, Morgan Stanley, Dell, and Anything LLM have been instrumental in helping us deliver what we announced today. Our goal is to make Foundry Local the simplest, most trustworthy, and most powerful local AI platform for state-of-the-art models. We expect to continue to co-create with you all in delivering a robust experience for on-device AI. We have an ambitious roadmap ahead: bringing Foundry Local to General Availability, strengthening Android support, and continuing to advance Windows AI Foundry. We’re also investing in richer capabilities like tool calling, support for Linux, multi-modality, and expanded support for on-prem servers.
“Our partnership with Microsoft on Foundry Local and the Dell AI Factory with ecosystem enablers for AI PCs gives developers broader model access and greater choice, with an expanded portfolio of AI models tailored to specific business needs and the flexibility to choose the right tools for specific goals across the Dell AI PC portfolio.” – Marc Hammons, Dell Senior Director, CSG CTO
“AnythingLLM, powered by Foundry Local, allows us to run lightning-fast models such as Deepseek, Mistral, Phi and Qwen on CPU, GPU, and NPU without needing to build our own local LLM engine. This allows us to focus on building the features and integrations enterprises use us for to leverage state-of-the-art models entirely on-device in the most powerful ways possible.” – Timothy Carambat, CEO at AnythingLLM
Hear from some of our customers below.
Come with us on this journey:
- Try Foundry Local today: https://aka.ms/foundrylocal
- Join us at Ignite: From cloud to edge: Building and shipping Edge AI apps with Foundry
- See Foundry Local in action: https://aka.ms/FL_IGNITE_MSMechanics
0 comments