

On January 28, 2026, Hugging Face announced that they have upstreamed the Post-Training Toolkit into TRL as a first-party integration, making these diagnostics directly usable in production RL and agent post-training pipelines. This enables closed-loop monitoring and control patterns that are increasingly necessary for long-running and continuously adapted agent systems. Documentation @ https://huggingface.co/docs/trl/main/en/ptt_integration.
Overview
In production-scale agent reinforcement learning systems, training runs increasingly operate over long horizons, incorporate external tools, and adapt continuously rather than via episodic retraining. In this regime, late-phase instability is rarely a single catastrophic event. Instead, failures often emerge gradually, compound quietly, and surface only after recovery options are limited.
This work identifies a mechanism behind such late-phase instability that is specific to tool-using agents trained with on-policy methods. We show that variance amplification can localize to tool-conditioned contexts and manifest as gradual tail growth in importance-weighted updates, while aggregate metrics such as loss, reward, entropy, and global KL remain stable. The contribution here is not a new optimizer or learning rule, but a set of targeted diagnostics that make this failure mode observable early enough to matter in production settings.
Production context. We observed this failure mode in long-running, distributed on-policy post-training with tool-augmented rollouts. The core problem is that the metrics we normally monitor (loss, reward, mean KL) are aggregates that can remain stable while rare-but-catastrophic behavior grows in the tail. To make the system debuggable, we compute diagnostics in-stream, slice them by interaction mode (pre-tool vs post-tool), and aggregate them across workers so we can catch instabilities before they turn into divergence. We keep overhead low by tracking lightweight statistics (rolling windows, percentiles) on a fixed cadence, so the approach stays compatible with large-scale training and rapid iteration.
What’s new here
Prior work has identified variance, distribution shift, and late-phase instability as persistent challenges in reinforcement-learning-trained language models and long-horizon agents. These failures are often attributed to entropy collapse, optimizer dynamics, or insufficient global variance control. This work identifies a distinct mechanism, not reducible to global entropy collapse or optimizer dynamics alone: Variance amplification driven by exposure to tool-conditioned states that lie in low-support regions of the reference policy.
Crucially, this mechanism can remain invisible to aggregate entropy, reward, and global KL metrics while compounding over long horizons.
Intuition: Why tools change the failure surface
Tool calls expand the reachable state space through external transitions, not through exploration within the policy’s own action space. As training progresses, exposure to tool-conditioned contexts grows relative to early text-only interactions. Empirically, these post-tool contexts often lie in regions where the reference policy assigns substantially lower probability mass. A useful abstraction is to write the training state distribution as a mixture:
d(s) = (1−α)·d_text(s) + α·d_tool(s)
As α increases over training, a growing fraction of updates are drawn from regions where importance-weighted objectives become dominated by denominator effects. Even modest policy updates in these regions induce disproportionate variance.
Minimal reproduction
The qualitative pattern was reproduced in a constrained but non-trivial setting using an instruction-tuned open-weight language model trained with on-policy reinforcement learning in a long-horizon, tool-using loop. These experiments were intentionally small-scale and optimized for diagnostic clarity rather than statistical power. Even in this simplified regime, tail emergence appeared first in post-tool contexts while aggregate metrics remained stable over the same period. Notably, constraining tool outputs suppressed tail growth.
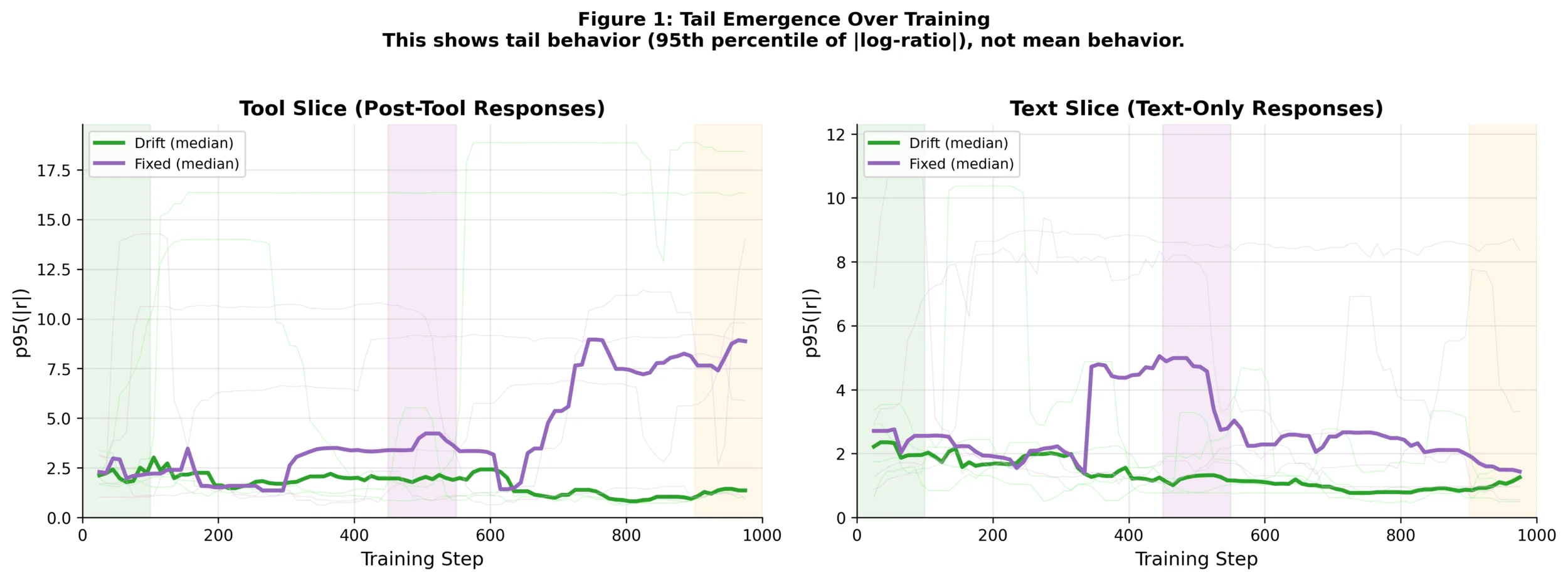
Figure 1: Tail emergence over training
Figure 1 shows the evolution of tail behavior over training, measured as the 95th percentile of the absolute per-token log-ratio (|r|), computed separately for text-only and post-tool slices. This figure is intentionally not a mean metric. It tracks tail growth, not average behavior. Key observations:
- In text-only contexts, tail magnitudes remain relatively stable or decrease over training
- In post-tool contexts under fixed-policy baselines, tail magnitudes grow steadily over long horizons
- Drift-aware setups substantially suppress this tail growth
Importantly, this tail emergence occurs without corresponding spikes in aggregate loss, reward, or entropy, explaining why instability often appears late.

Figure 2: Distributional shift, not threshold crossing
While tail percentiles are useful summaries, they do not capture the full distributional change. Figure 2 shows the empirical CDF of (|r|) in early, mid, and late training windows.
The key signal is not a single threshold crossing, but a shape change in the right tail:
- Tool-conditioned distributions flatten and stretch over training
- Probability mass migrates toward higher-magnitude updates
- This shift is muted or reversed under drift-aware baselines
This confirms that the effect is distributional, not an artifact of a particular percentile choice. Mechanism: Tool-conditioned support mismatch For on-policy methods using ratio-based objectives, the dominant variance term scales with the second moment of the probability ratio:
Var[ĝ] ∝ E[(π_θ(a|s) / π_ref(a|s))²]
As training increasingly samples from tool-conditioned states where π_ref(a|s) is small, gradient contributions concentrate in the tail. Larger batches and better baselines reduce estimator noise, but do not address collapsing support in these regions. In practice, entropy dynamics, optimizer behavior, and tool-conditioned variance amplification may interact; the contribution here is to isolate a failure mode that can arise even when global entropy and optimizer statistics appear well behaved. Because tool calls inject external transitions without corresponding visitation guarantees, this variance accumulates in a way that standard global variance reduction techniques are poorly suited to detect.

Figure 3: Effective sample size as a diagnostic signal
Figure 3 shows the effective sample size (ESS) computed over sliding windows as a supporting diagnostic. ESS degradation indicates increasing weight concentration and complements the tail-based metrics. This signal is included qualitatively:
- ESS is sensitive to window size and batch structure
- Absolute values should not be over-interpreted
- Trends are consistent with observed tail growth in post-tool slices
For this reason, ESS is treated as a supporting signal, not primary evidence.
Failure signature and common misattribution
This failure mode is both asymmetric and delayed in its presentation. Divergence emerges first in tool-conditioned contexts, while aggregate metrics can remain stable for extended periods. By the time global metrics begin to shift, variance has already compounded substantially. As a result, late-phase instability is often misattributed to optimizer instability or insufficient global variance control. Interventions along those axes can delay failure, but do not reliably prevent it.
Tool-conditioned variance amplification is less likely to dominate under certain conditions. When tool outputs are tightly schema-constrained and distributionally narrow, when policies are effectively frozen after tool calls, or when interaction diversity plateaus early, this mechanism plays a reduced role. In these regimes, late-phase instability is more often driven by classical failure modes such as reward hacking or mode collapse.
When this mechanism dominates, several practical considerations follow. Aggregate metrics lag the onset of instability, necessitating monitoring that specifically targets tool-conditioned slices. Guardrails such as KL caps and rollback policies become load-bearing components of the training infrastructure, and failure-aware curricula can reduce late-phase oscillation.
The primary empirical claim is not precise threshold ordering or universal quantitative effects. The consistent signal is the emergence of heavy-tailed importance-weight distributions in tool-conditioned contexts, and their suppression under constrained tool outputs. The experiments presented here are short-horizon and limited in scale, but the mechanism aligns with patterns observed in longer-running systems.
Implementation: The Post-Training Toolkit
This failure mode is one example of the class of issues that show up in modern post-training: signals that emerge late, localize to specific slices of behavior, and remain invisible in aggregate dashboards. To make these problems observable by default, we built the Post-Training Toolkit — an open-source diagnostics layer that plugs into SFT, preference optimization, and RL-style post-training workflows and surfaces training pathologies early enough to act on: https://github.com/microsoft/post-training-toolkit. Concretely, it provides:
- Training diagnostics: live warnings, automatic failure detection, and artifacts with one callback integration
- Distributed-aware monitoring: metric aggregation across ranks, straggler detection, and memory balance checks in multi-GPU training
- Agent trace analysis: turning agent logs into diagnostics and exporting preference datasets for post-training
- CLI tooling: one-command diagnosis and reporting for both training runs and agent traces
The diagnostics in this post (slice-aware post-tool monitoring and tail growth detection) are implemented as part of that broader framework: a pattern for catching failures that are localized, distributional, and delayed.
Closing
This work contributes not a new optimization technique, but visibility into a failure mode that historically remained hidden until recovery options were limited. As agent training moves toward continuous, online, and self-modifying systems, failure modes invisible to aggregate metrics represent a fundamental reliability risk. Making dominant instability mechanisms measurable is a necessary step toward building robust tool-using agents.
0 comments
Be the first to start the discussion.