


After I wrote my last post on how .NET builds and ships, I was cautiously optimistic that I wouldn’t be writing another one. Or at least not another one about how we build and ship. That problem was done and dusted. .NET had done it! We’d struck a balance between distributed repository development and the ability to quickly compose a product for shipping. Congratulations everyone, now the infrastructure teams could focus on other things. Security, cross-company standardization, support for building new product features. All the good stuff.
…A year and a half later…
We’re asking how much it will cost to build 3-4 major versions with a dozen .NET SDK bands between them each month. And keep their engineering systems up to date. And hey, there’s this late breaking fix we want to get into next week’s release, so can I check it in today and have the team validate tonight? It can’t be that hard, right? And I have this new cross-stack feature that I want to do some prototyping on…how can I build it?
The answers were mostly frustrating:
“It’ll cost a lot, and get worse over time.“
“I don’t think we have enough time for that fix, I can only guess how long the build will take, but it’s at least 36 hours before we can handoff to validation. Maybe more?“
“I’m sure we can keep that much infrastructure alive, but we’ll slowly drown under the cost of keeping it up to date.“
“How critical is it that you have a full stack to work with? It’ll take a while to set that up.“
These are not the answers we want to be giving. And so, we went back to the drawing board, looking for solutions.
This blog post is about the Unified Build project: .NET’s effort to resolve many of these issues by moving product construction into a ‘virtual monolithic’ repository, consolidating the build into a series of ‘vertical builds’, while still enabling contributors to work outside the monolith. I’ll briefly tell the story of our product construction journey over the life of .NET. I’ll draw attention to the lessons we’ve learned about applying a distributed product construction model to a single product, particularly its drawbacks in overhead and complexity. Finally, I’ll dig into the details of Unified Build and its foundational technology, Linux distro Source Build. We’ll look at the new method of product construction and the results we’re seeing.
How did we get here? This is not my beautiful build infrastructure
.NET was born out of the closed source infrastructure of the .NET Framework and Silverlight in 2015-2016. It was made open source incrementally as we readied its components for external consumption, and as was the fashion at the time, we split it into multiple repositories. CoreCLR represented the base runtime, CoreFX the libraries, Core-Setup the packaging and installation. Along came ASP.NET Core and EntityFramework Core, and an SDK with a CLI. A few releases saw major revamps of the product in the form of shared frameworks, with WindowsDesktop joining the fold. More repositories and more complexity.
What is important to understand is that .NET is a product that is developed in separate inter-dependent repositories but needs to be composed together in a relatively short period of time to ship. On paper, the ‘graph’ of the product looks much like any open source ecosystem. A repository produces some software component, publishes it to public registries, and downstream consumers take a dependency on the new component, and publish their own updates. It’s a producer-consumer model where changes ripple through the ‘global’ dependency graph via a series of pull->build->publish operations. This model is highly distributed and effective, but it is not necessarily efficient in a time sense. It enables software vendors and repository owners to have significant autonomy over their process and schedules. However, attempting to apply this methodology to a product like .NET, which represents its components using separate, but inter-dependent repositories, has major drawbacks.
Let’s call this a “distributed product construction methodology”. To get a sense of why it can be a difficult methodology to use, let’s take a look at the process to produce a security release.
Example: Security Servicing
Consider shipping a security patch. A security vulnerability is discovered somewhere in the .NET Runtime libraries. Because .NET is descended from .NET Framework, let’s say this security vulnerability is also present in .NET Framework 4.7.2. It becomes absolutely vital that .NET’s security update goes out in tandem with the .NET Framework update, or one will zero-day the other. .NET has numerous Microsoft-managed release paths. Microsoft Update, our CDN, Linux and container package registries, nuget.org, Visual Studio, Azure Marketplace, and on and on. That puts some restrictions on timeline. We need to be able to be predictable.
.NET’s development structure looks a lot like a typical open source ecosystem. The .NET Runtime, the .NET SDK, ASP.NET Core and the WindowsDesktop shared framework are developed by different teams, though with a huge amount of cross-collaboration. They are developed, at times, like independent products. The .NET Runtime forms the base of the product. ASP.NET Core and WindowsDesktop are built on top of that. A huge quantity of the dev tooling (C#, F#, MSBuild) is built on top of the surface area of the .NET Runtime and some auxiliary libraries. The SDK gathers up and builds a CLI, along with tasks, targets and tooling. Much of the shared framework and tooling content is redistributed in-box.
To build and ship this security patch, we need coordination between the many teams that contribute to the .NET product as a whole. We need the lowest levels of the .NET graph (see below) to build their assets, then feed them downstream to consumers. They need take the update, build, and feed downstream. This will happen continually until the product is “coherent”; no new changes are being fed into the graph and everyone agrees on a single version of each component in the product. Coherency ensures that a component with changes is ingested everywhere that redistributes the component, or information about it. Then, we want to do our validation, take all the shippable assets from the closure of all those unreleased components, and then release them all at once to the world.
This is a lot of moving parts that need to work well together in a short period of time.
Advantages and Disadvantages of Distributes Ecosystems
It’s important to note that this distributed ecosystem style of development does have a lot of advantages:
- Layering – Repository boundaries tend to encourage layering and less tightly bound products. During the major version development lifecycle, the individual components of the stack generally remain roughly compatible, even as changes flow quickly and unevenly through the graph.
- Communities – Repository boundaries tend to encourage good, focused communities. The WPF and Winforms communities, for instance, are often distinct. Small repos are also generally more approachable.,
- Incrementality – Distributed development often allows for incremental changes. For instance, we can make breaking changes to the System.CommandLine surface area, then ingest those in the consumers over time. This doesn’t work all the time (e.g. let’s say the SDK is attempting to ship just one copy of System.Text.Json for all of the tooling to use, but not every consumer agrees on that surface area. Boom?!), but it’s reasonably reliable.
- Tight Inner Loops – Smaller, focused repositories tend to have better inner-loop experiences. Even something as simple as
git cloneorgit pullis faster in a small repository. The repository boundary tends to give the (possibly illusory) sense that for your change, you only need to worry about the code and tests you can see. - Asynchronous development – Incrementality helps development be more asynchronous. If my component flows to three downstream consumers who work in three different time zones, those teams can make progress on their own components in their own time, rather than needing to coordinate.
- Low-Cost Sharding/Incremental Builds – Distributed development allows for ‘optimizing’ away builds of components that don’t change every often and are at the fringes of a dependency graph. For instance, a leaf node that builds some static test assets doesn’t need to be rebuilt every time there is a change to the sdk. The last built assets are just fine.
If you squint and peer between the lines here though, a lot of the advantages of the distributed model are its significant weaknesses when we need to build and ship software that requires changes in a significant portion of the graph to be completed in a short period of time. Changes at scale across large graphs are often slow and unpredictable. But why? Is there something inherently wrong with this model? Not really. In typical OSS ecosystems (e.g. NuGet or NodeJS package ecosystems), these aspects are often not a problem. These ecosystems do not optimize for speed or predictability. Instead, they value the autonomy of each node. Each node needs only to concern itself with what it needs to produce and what it needs to consume and the changes required to meet those needs. However, when we attempt to apply the distributed model to shipping software quickly, we often struggle because it increases the prevalence of two key concepts, which I’m calling Product Construction Complexity and Product Construction Overhead. Together these combine to slow us down and make us less predictable.
Product Construction Complexity
In the context of product construction, ‘complexity’ refers to the quantity of steps that are required for a change to go from a developer’s machine to that change being delivered to customers in all the ways that it needs to be delivered. I recognize that this is a fairly abstract definition. “Step” could mean different things depending on what level of granularity you want to look at. For now, let’s focus on conceptual product construction steps, as shown in the example graph below:
 A simple multi-repository product construction workflow. MyLibrary and MyApp are built from separate codebases. MyApp deploys to two customer endpoints
A simple multi-repository product construction workflow. MyLibrary and MyApp are built from separate codebases. MyApp deploys to two customer endpoints
.NET began with a relatively simple product dependency graph and matching tools to manage that graph. As it grew, new repositories were added to the graph and additional dependency flow was required to construct the product. The graph grew more complex. We invented new tools (Maestro, our dependency flow system) to manage it. It was now easier than ever to add new dependencies. A developer or team looking to add new functionality to the product could often just create a new repository and build and set up the inputs and outputs. They only needed to know how that component fit within a small subsection of the larger product construction graph in order to add a new node. However, .NET doesn’t ship each individual unit independently. The product must become “coherent”, where everyone agrees on the versions of their dependencies, in order to ship. Dependencies or metadata about them are redistributed. You have to “visit” all of the edges. Note: While we do not need to rev every component in the graph, there is a significant portion that changes on every release, either due to fixes or dependency flow. Then you take the outputs of each individual node, combine them all together, and out the door you go.
More complex graphs have significant downsides:
- The more edges and nodes, the longer it tends to take to achieve coherency.
- Teams are more likely to make a mistake. There are more coordination points, and more points in the workflow where a human can influence an outcome. Tools can help, but they only go so far.
- Complexity can also encourage variance in build environment and requirements. It’s hard to keep everyone aligned on the same processes as teams move and upgrade at different rates. Reproducing that full set of environments can be expensive, and that cost tends to increase over time as infrastructure “rots”.
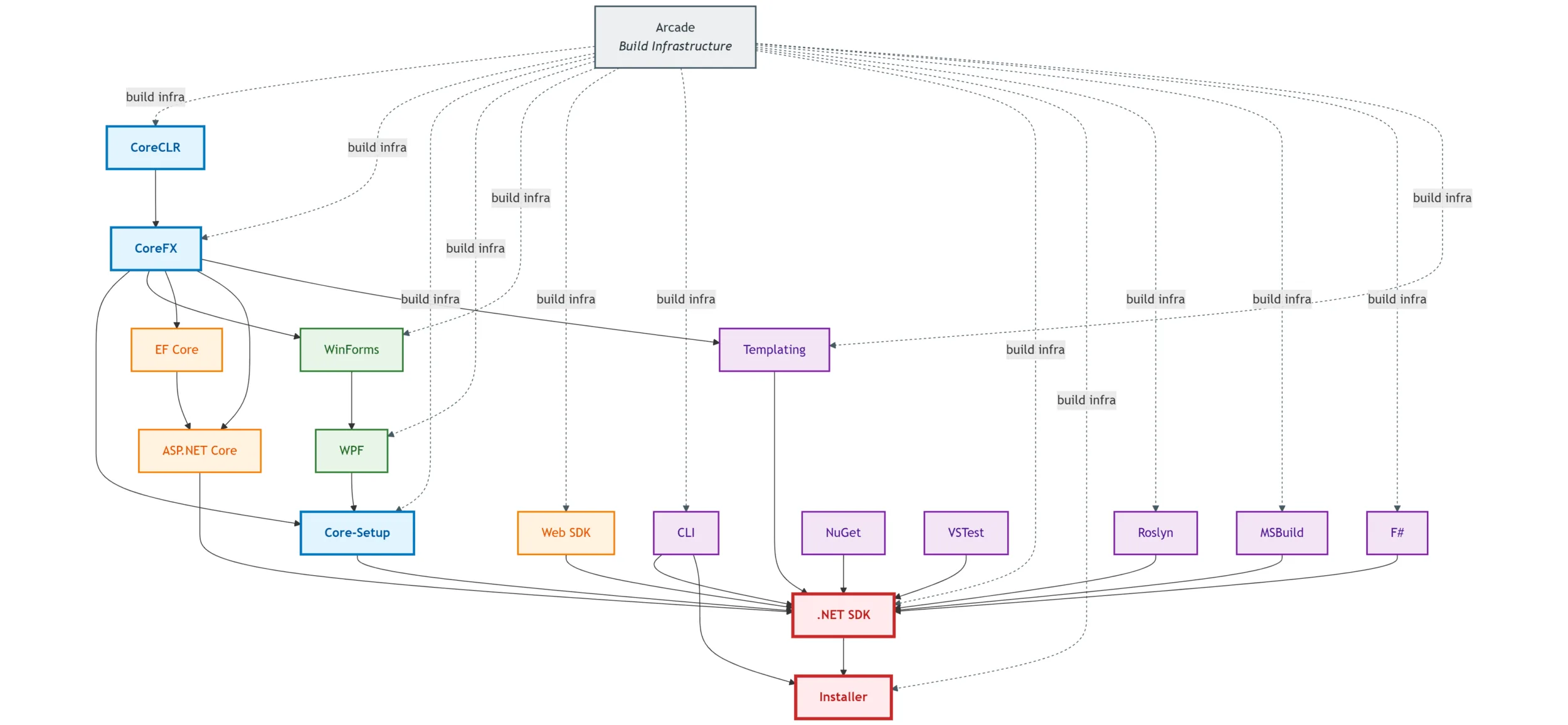 Small but critical subsection of the .NET product construction graph, circa .NET Core 3.1. Arcade provides shared build infrastructure (dotted lines), while solid lines show component dependencies. Changes ripple through multiple repositories before reaching the final SDK and installer.
Small but critical subsection of the .NET product construction graph, circa .NET Core 3.1. Arcade provides shared build infrastructure (dotted lines), while solid lines show component dependencies. Changes ripple through multiple repositories before reaching the final SDK and installer.
Product Construction Overhead
We define overhead as “the amount of time spent not actively producing artifacts that we can ship to customers“. Like complexity, it can be evaluated on a different level of granularity depending on how detailed you want to get. Let’s take a look at two quick examples, and then at the overhead in one of .NET’s older builds.
A simple multi-repo product construction process might look like the following:
 Illustration of overhead in a simple multi-repo product-construction workflow. Dot-outlined nodes represent overhead.
Illustration of overhead in a simple multi-repo product-construction workflow. Dot-outlined nodes represent overhead.
In the above graph, the overhead nodes (dotted nodes) do not actively contribute to the production of the packages in D. The time it takes the dependency flow service to create the PR is overhead. Waiting for a dev to notice and review the PR is overhead. Waiting for approval for package push is overhead. That’s not to say that these steps aren’t necessary, just that they are places where we say we’re not actively creating outputs for customers.
How about builds? If we zoom into a repository build process, we can often see quite a lot of overhead. Consider this very simple build:
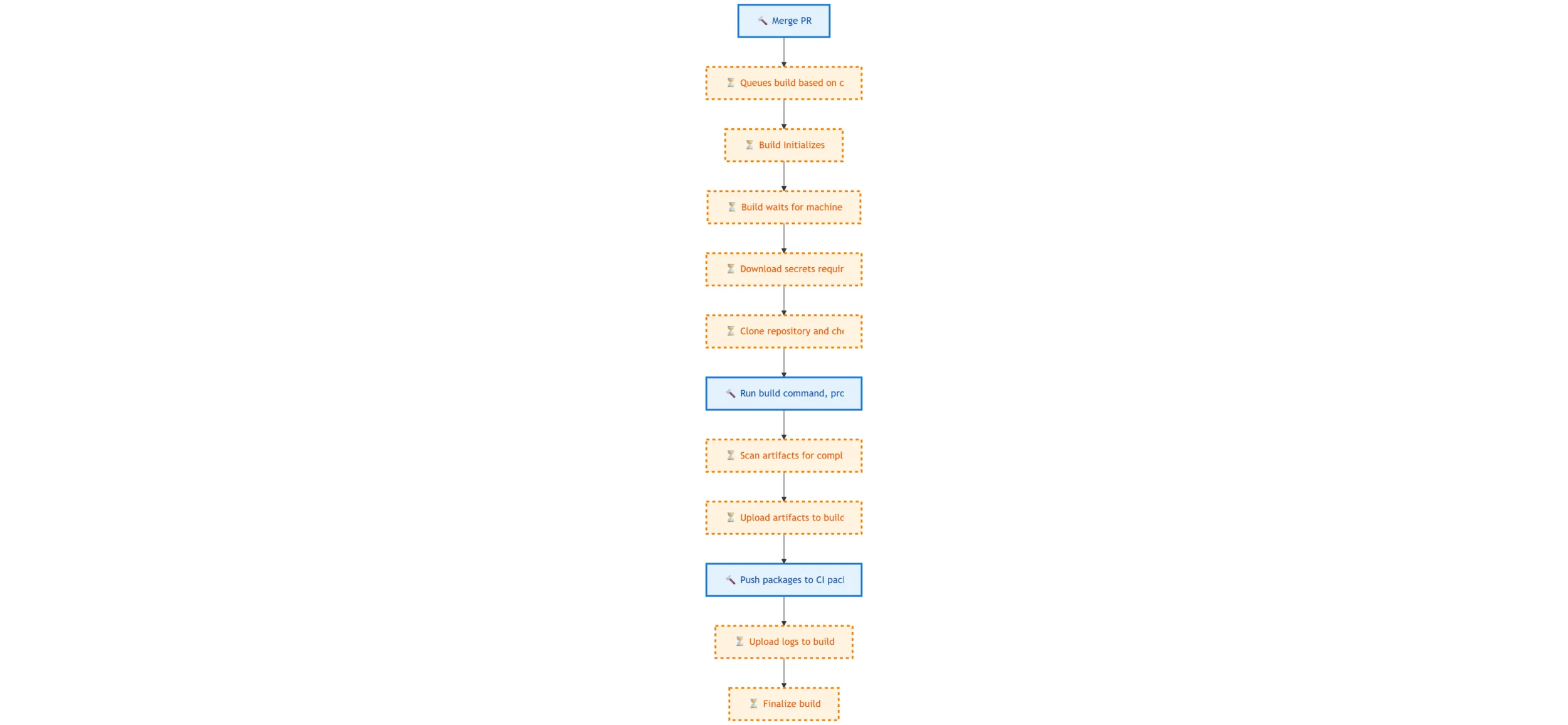 Illustration of overhead in a simple pipeline. Dot-outlined nodes represent overhead. Again, there are a number of steps here that aren’t actively producing or shipping bits to customers. They may be necessary, but they’re still overhead.
Illustration of overhead in a simple pipeline. Dot-outlined nodes represent overhead. Again, there are a number of steps here that aren’t actively producing or shipping bits to customers. They may be necessary, but they’re still overhead.
There are a few interesting measures of overhead in a system. We can measure it a % of overall time. Add up the time spent in each step based on its classification, then divide the total overhead by the total time. This gives a nice measure of overall resource efficiency. However, from a wall clock perspective, overall overhead doesn’t tell us much. To understand overhead’s effect on the end-to-end time, we find the longest path by time through our product construction graph, then compute the total overhead in steps that contribute to that path as compared to the total time in the path.
To understand what that overhead might look like in a single .NET build, let’s take a look at an 8.0 build of runtime. This data was generated using a custom tool that can evaluate an Azure DevOps build based on a set of patterns that classify each step.
| Metric | Time | Percentage of overall build time |
|---|---|---|
| All Steps (w/ Queueing) | 2 days 02:18:10.9 | 100% |
| Overhead (w/ Queueing) | 19:23:22.9 | 38.5% |
| Overhead (w/o Queueing) | 12:33:36.6 | 25.0% |
| Queueing | 06:49:46.3 | 13.6% |
| Work | 1 day 06:42:10.7 | 61.0% |
| Unknown | 00:12:37.3 | 0.4% |
| ———– | ———- | —– |
| Longest Path Time | 05:40:05.2 | N/A |
| Average Path Time | 04:03:11.3 | N/A |
Here are the three longest paths from that build:
| Path | Total Time | Overhead Time (w/ Queue) | Queue Time | Work Time | Unknown Time |
|---|---|---|---|---|---|
| (Stage) Build->Mono browser AOT offsets->windows-x64 release CrossAOT_Mono crossaot->Build Workloads->(Stage) Prepare for Publish->Prepare Signed Artifacts->Publish Assets | 05:40:05.2 | 02:46:49.8 (49.1%) | 00:40:29.8 (11.9%) | 02:51:39.0 (50.5%) | 00:01:36.3 (0.5%) |
| (Stage) Build->windows-arm64 release CoreCLR ->Build Workloads->(Stage) Prepare for Publish->Prepare Signed Artifacts->Publish Assets | 05:37:32.0 | 02:28:58.1 (44.1%) | 00:31:32.2 (9.3%) | 03:07:05.6 (55.4%) | 00:01:28.2 (0.4%) |
| (Stage) Build->Mono android AOT offsets->windows-x64 release CrossAOT_Mono crossaot->Build Workloads->(Stage) Prepare for Publish->Prepare Signed Artifacts->Publish Assets | 05:37:00.9 | 02:47:19.1 (49.6%) | 00:40:51.8 (12.1%) | 02:48:05.0 (49.9%) | 00:01:36.8 (0.5%) |
Overhead + Complexity = Time
Overhead is unavoidable. There is some level inherent in every product construction process. However, when we add complexity to our product construction processes, especially complexity in the graph, the overhead tends to begin to dominate the process. It sort of multiplies. Rather than paying the machine queue time cost one time, you might pay it 10 times over within a single path through the graph. After those machines are allocated, you then clone the repo each time. The efficiency scaling of these steps tends to also be worse because there is some fixed cost associated with each one. For instance, if it takes 10 seconds to scan 10MB of artifacts, and 1 second to prepare for the scan, collate and upload the results, it takes longer to do that step 10 times in a row than it does to scan the full 100MB at once. 110 vs. 101 seconds.
What is also insidious is that this cost tends to hide and increase over time. It’s not always obvious. A local repository build for a developer is typically fast. The developer does not see any overhead of the overall CI system in that build. Zooming out, building the repository in a job in a pipeline can be similarly quick, but starts to incur some overhead. You have the quick build of that repository, but extra overhead steps around it. You’re still reasonably efficient though. Then let’s say you zoom out a little and you have some additional jobs in that pipeline, doing other things. Maybe reusing artifacts from other parts of the build, building containers, etc. Overhead will start to become a larger overall % of the long path time. Now, zoom out again, and you’re looking at the place of that pipeline and associated repositories in context of your larger product construction. You add in time for dev PR approvals, dependency flow systems to do their work, more cloning, more building, more compliance, more more more.
In a distributed product construction system, decisions that affect complexity, and therefore overhead, can be made at a level that does not see the overall overhead in the system. A new node is added. In isolation, it’s fine. In context, it costs.
While no graph of complexity was ever made for the .NET 8 timeframe that could show the complexity of each individual component build in context of the whole product construction graph, consider what the job graph for the runtime build alone looked like. Each bubble below represents a separate machine.
 Complexity in a .NET 8 build. Each node represents an individual machine. Edges represent dependencies.
Complexity in a .NET 8 build. Each node represents an individual machine. Edges represent dependencies.
The roots of Unified Build in Source Build
.NET Source Build is a way that Linux distributions can build .NET in an isolated environment from a single, unified source layout. Microsoft started working on it around .NET Core 1.1. The spiritual roots of Unified Build grew from hallway conversations between the team working on .NET Source Build and the team responsible for the Microsoft distribution. I won’t say it wasn’t in jealousy that the infrastructure teams often looked at how long it took to build the .NET product within the Source Build infrastructure. 50 minutes! Shorter than it took to build just the runtime repository from scratch in its official CI build. Now granted, it wasn’t exactly an apples-to-apples comparison. After all, Source Build:
- Only builds one platform.
- Doesn’t build any of the Windows-only assets (e.g. WindowsDesktop shared framework)/
- Doesn’t build .NET workloads.
- Doesn’t do any installer packaging.
- Doesn’t build the tests by default
All very reasonable caveats. But enough caveats to add up to 10s of hours in differences in build time? Unlikely. Much more likely is that the Source Build methodology is low complexity and low overhead. More than just time, there were other obvious benefits. Unified toolsets, easier cross-stack development, and perhaps most importantly, hard guarantees of what was being built and its build-time dependencies.
Back to those hallway conversations. Source Build’s obvious benefits led to occasional probing questions from various members of the .NET team. Most of the form: So…why doesn’t Microsoft build its distribution that way? Answer: It’s hard.
Why is it hard? A detour into the land of Source Build
Microsoft began efforts to make Source Build a ‘real’ piece of machinery around the .NET 3.1 timeframe. Prior to this point, the Source Build distribution tended to look more like a one-off effort for each .NET major release. It was too difficult to keep working all the time, so the team worked, starting in the spring as the new product took shape, to bring the new .NET version into line with Linux distro maintainer requirements. To understand why it’s so hard to fit Microsoft’s distribution of .NET into this model as part of the Unified Build project, let’s look back into why it was so hard to get the Source Build project into a turn crank state in the first place.
To allow our distro partners to distribute .NET we needed to produce an infrastructure system that produced a .NET SDK within the following constraints:
- Single implementation! – Only one implementation per component
- Single platform – Only build for one platform (the one that distro partners are trying to ship)
- Single build – Only build on one machine. We can’t require a complex orchestration infrastructure.
Linux Distro Build Requirements
Linux distros generally have stricter rules and less flexibility when building software that will go into their package feeds. The build is usually completed offline (disconnected from the internet). It may only use as inputs artifacts that have been previously created in that build system. Checked-in binaries are not allowed (though they can be eliminated at build time). Any source in the repository must meet strict licensing requirements. See license information for information on .NET licensing and Fedora licensing approval for sample distro requirements. At a conceptual level, a Linux distro partner wants to be able to trace every artifact they ship to a set of sources and processes that they can reasonably edit. All future software should be built from previously Source Build produced artifacts. Note: There is a bootstrap process, as you might imagine might be required..
Single Build – A repo and orchestration framework to stitch the stack together
As you’ve learned earlier, the .NET build, like many products, is actually comprised of the Azure DevOps builds of various components, stitched together with dependency updates. This means that the information and mechanics required to construct the product is distributed between the repositories (build logic within the build system and associated scripting, as well as YAML files processed by Azure DevOps) and the dependency flow information held by our ‘Maestro’ system (producer-consumer information). This isn’t usable for our Linux distro partners. They need to be able to build the product without access to these Microsoft resources. And they need to be able to do so in a way that is practical for their environments. Manually stitching together a product from a build graph isn’t reasonable. We need an orchestrator that encapsulates that information.
The Source Build layout and orchestrator
The orchestrator replaces the tasks that Azure DevOps and Maestro perform for .NET’s distributed build with ones that can be run from a single source layout, disconnected from the internet. You can see the modern, updated layout and orchestrator over at dotnet/dotnet.
-
Single source layout – A single source layout with a copy of all components required to build the product. Submodules are flattened, if they exist (typically for external OSS components). The contents of the source layout are determined by identifying an annotated dependency for each component within the product graph, rooted at dotnet/sdk. The sha for that annotated dependency determines what content will populate the layout. Note: dependencies like compilers and OS libs are provided by the build environment.
-
Information on how each component should be built, and its dependencies – For each of the components within the single source layout, a basic project is provided which identifies how the component is built. In addition, the component level dependencies are also identified. i.e. the .NET Runtime needs to be built before ASP.NET Core can start.
<ItemGroup> <RepositoryReference Include="arcade" /> <RepositoryReference Include="runtime" /> <RepositoryReference Include="xdt" /> </ItemGroup> -
Build orchestrator logic – The build orchestrator logic is responsible for launching each build in the graph when it is ready (any dependencies have been successfully built), as well as inputs and outputs of each component. After a component build has been completed, the orchestrator is responsible for identifying the outputs and preparing inputs for downstream component builds. Think of this as a local Dependabot, computing the intersection of the declared input repositories against the package level dependency info (see aspnetcore’s) for an example. More information on how dependency tracking works in .NET builds can be found in my previous blog post.
-
Compliance verification – The comparatively stricter environments that our Linux distro partners build in mean that it’s necessary that we build some automation to identify potential problems. The orchestrator can identify pre-built binary inputs, ‘poison’ leaks (previously source-built assets appearing in the current build outputs), and other hazards that might block our partners.
-
Smoke testing – Most of our test logic remains in the individual repositories (more on that later), but the layout also includes smoke tests.
Single Implementation – Pre-built squeaky clean
There are some obvious and non-obvious reasons why these requirements would be hard to meet using the ‘stock’ Microsoft build of .NET, and why Source Build required so much work. An offline build with pre-staged, identified inputs that are buildable from source is a major undertaking. When the Source Build team began to investigate what this meant, it was quickly obvious that a LOT of interesting behavior was hiding in the .NET product build. Sure, binary inputs like optimization data were obviously disallowed, but some other foundational assets like .NET Framework and NETStandard targeting packs were also not buildable from source. Either they weren’t open source in the first place, or they hadn’t been built in years. More concerning, the graph-like nature of .NET means that incoherency is very common. Some of this incoherency is undesirable (the kind we attempt to eliminate during our product construction process). Some of it is expected and even desired.
Example: Microsoft.CodeAnalysis.CSharp
As an example, let’s take a look at the C# compiler analyzers, which are built in the dotnet/roslyn repository. The analyzers will reference various versions of the Microsoft.CodeAnalysis.CSharp package depending on the required surface area to ensure that a shipped analyzer runs all of the versions of Visual Studio and the .NET SDK that it is required to support. They reference a minimum possible version. This ensures that analyzers can be serviced in a sustainable fashion, rather than shipping a different version of an analyzer for every possible VS or SDK configuration.
Because multiple versions of the surface area are referenced, multiple versions of Microsoft.CodeAnalysis.CSharp are restored during the build. That would mean, for the purposes of Source Build, we need to build each and every one of those versions of Microsoft.CodeAnalysis.CSharp at some point. We have two ways to do this:
- Multi-version source layout – Place multiple copies of dotnet/roslyn into the shared source layout, one for each referenced
Microsoft.CodeAnalysis.CSharpversion based on when it was originally produced. This is not only expensive in build time, but it tends to be somewhat viral. If you have 3 versions of dotnet/roslyn you need to build, you need to ensure that the transitive dependencies of those 3 versions are also present in the shared layout. The maintenance complexity of this setup goes up very quickly. These are previously shipped versions of the dotnet/roslyn source base. It will be necessary to maintain security and compliance of those codebases over time. Upgrading build-time dependencies. Removing EOL infrastructure, etc. - Require previously source-built versions to be available – This is really just a flavor of the multi-version source layout with an element of “caching”. If a distro maintainer needs to rebuild the product from scratch, or if a new Linux distribution is being bootstrapped, they might need to reconstruct decent portion of .NET’s past releases just to get the latest one to build in a compliant fashion. And if those old versions require changes to build in a compliant fashion, you’re again in a maintenance headache.
Source Build Reference Packages
There are numerous other examples like Microsoft.CodeAnalysis.CSharp. Any time a project targets a down-level target framework (e.g. net9 in the net10 build), the down-level reference pack is restored. SDK tooling (compilers, MSBuild) targets versions of common .NET packages that match the version shipped with Visual Studio. So how do we deal with this? We cannot simply unify on a single version of every component referenced within the product without fundamentally changing the product.
The Source Build team realized that a lot of this usage fit neatly into a class of “reference-only” packages.
- The targeting packs restored by the SDK when a project builds against a TFM that does not match the SDK’s major version (e.g. targeting net9 with a net10 SDK) do not contain implementation.
- The reference to older versions of
Microsoft.CodeAnalysis.CSharpare surface area only. No assets are redistributed from these packages. If the implementation is not needed, a reference-only package can be substituted.
Enter dotnet/source-build-reference-packages. A reference-only package is significantly simpler to create and build, and it meets the needs of the consumers in the build. We can generate reference package sources for packages where we do not need the implementation, then create an infrastructure to store, build and make them available during the Source Build process. Providing multiple versions is relatively trivial. The dotnet/source-build-reference-packages repository is built during the .NET build, and then consuming components restore and compile against provided reference surface area.
What about all those non-reference cases?
With a solution to reference packages, we can turn our attention to other inputs that are not Source Build compliant and do not fall into the ‘reference’ category. There are three major sets:
- Closed source or inputs that cannot be built from source – Optimization data, Visual Studio integration packages, internal infrastructure dependencies, etc.
- Legacy – Open source dependencies on implementation built in older versions of .NET.
- Joins – Open source dependencies on implementation built on other platforms.
Let’s take a look at how we deal with these cases.
Closed Source/Non-Source Buildable Inputs
Closed source or any inputs that cannot be built from source aren’t allowable in the Linux distro maintainer builds, full stop. To resolve these cases, we analyze each usage to determine what to do. Remember that our goal is to provide a compliant build implementation for use by our distro partners, which is functionally as close to what Microsoft ships as is possible. i.e. we don’t want Microsoft’s Linux x64 SDK to behave in substantially different ways from RedHat’s Linux x64 SDK. This means that the runtime and sdk layouts for Linux x64 need to be as close as possible. The good news is that quite a lot of the closed source usage isn’t required to produce functionally equivalent assets. Examples:
- We might restore a package that enables signing, something not required in a distro partner build
- The dotnet/roslyn repository builds components that power Visual Studio. These components have dependencies on Visual Studio packages that define the IDE integration surface area. However, this IDE integration doesn’t ship in the .NET SDK. This functionality could be “trimmed away” in Source Build by tweaking the build. This is reasonably common.
If dependencies couldn’t be trimmed away without altering product functionality, we have a few additional options:
- Open source the dependency – Often times, a closed source component, or at least a key portion of a closed source component required to satisfy a scenario, can be open sourced.
- Alter product behavior – Sometimes, the team can work to remove the product differences with intentional design changes. Remember that the important part is that everything that ships on distro partner package feeds needs to be built from source. This allows for some assets to be brought in dynamically. Think of this like the NPM package ecosystem vs. the NPM package manager. A distro might build the NPM package manager from source. This leaves users to dynamically restore NPM packages at build time.
- Live with slightly different behavior – These cases are few and far between. Prior to .NET 10, the WinForms and WPF project templates and WindowsDesktop were not included in the source-built Linux SDK, despite being available in Microsoft’s Linux distribution. This was due to the difficulty in building the required portions of those repositories on non-Windows platforms.
Legacy Dependencies
We’ve discussed what we can do with closed source and non-reproducible dependencies. What about legacy dependencies? First, what do we mean by ‘legacy’ dependency? As detailed in earlier discussion, there is quite a lot of ‘incoherency’ in the product. A project might build for multiple target frameworks, redistributing assets from older versions of .NET. This is all to support valuable customer scenarios. But building all the versions of these components isn’t feasible. This is where our single implementation rule comes into play. We choose a single version of each component to build and ship with the product. We do allow for reference to old versions, via dotnet/source-build-reference-packages, but relying on older implementations are off limits.
First, we look for a way to avoid the dependency. Is it needed for the Linux SDK we’re trying to produce? If not, we can eliminate that code path from the build. If so, is there an opportunity to unify on the single implementation? In a lot of cases, incoherency is just a result of the product components moving their dependencies forward at different rates. If all else fails, we could explore compromises that involve behavioral differences, but we want to avoid this as much as possible.
Joins and Verticality
Joins are the last major category of pre-builts to remove. They occur because we end up with intra-product dependencies that are built in another environment. For example, I might be running a build on Windows that creates a NuGet package for a global tool, but to build that NuGet package I need the native shim executables Mac and Linux and Windows. Those shims can only (reasonably) be built in the Mac and Linux host environments. These types of dependencies are indicative of a product build that is more ‘woven’ than ‘vertical’ and tend to naturally emerge over time in a multi-repo product construction graph. Each edge in that graph represents a sequence point where all the outputs of earlier nodes are available, regardless of where they were built. If a dependency can be taken, it will be taken.
However, the distro partner builds need to be single platform and single invocation to fit into distro partner requirements. Bootstrapping notwithstanding, they want to pull in the dependencies, disconnect the machine from the network, and hit build. At the end, out pops a bright new .NET SDK. Cross-platform dependencies preclude any such behavior. They block “build verticality”. Remember joins. We’ll need to come back to them later when we start implementing Unified Build for Microsoft based on the Source Build model.
For Source Build, we again deal with joins a bit like legacy dependencies. The key aspect to remember is that Source Build is narrowly focused on producing a .NET SDK and associated runtimes in the Linux distro partner build environments. So, we eliminate dependencies where possible (e.g. we don’t need to package Windows global tool executable stubs when running the SDK on Linux) and redesign the product or product construction process as necessary to meet requirements (e.g. .NET Workload manifests).
The Vision – Dreaming up Unified Build
Unified Build seeks to apply the general principles of our Linux distro partner Source Build to the product that Microsoft ships. Achieving this would result in big wins for Linux distro partners, upstream contributors and Microsoft, reducing maintenance costs and improving the ability to build and ship quickly. Although we knew from the outset that we likely can’t exactly match the exact Linux distro build approach without major changes in the product, we thought we could get close. .NET came up with the following high-level goals (Note, “.NET distro maintainers” refers to anyone building .NET, including Microsoft):
- A single git commit denotes all product source for a particular .NET build. All commits are coherent
- A single repo commit can produce a shippable build
- .NET’s build shall be able to create a specific platform’s distribution in a single build environment.
- .NET distro maintainers shall be able to efficiently update and build .NET (both collaboratively and separately) through the entire lifecycle of a .NET version (first to last commit).
- .NET distro maintainers can produce downstream distributions without use of Microsoft provided services.
- .NET distro maintainers shall be able to meet provenance and build environment requirements for their distributions.
- .NET distro maintainers shall be able to coordinate patching of downstream distributions.
- .NET distro maintainers can run verification tests against the built product.
- .NET contributors shall be able to easily produce full product builds for testing, experimentation, etc.
- .NET contributors shall be able to work efficiently on the section of the product for which they are concerned.
Still, getting there would require solving a mountain of new problems. Let’s take a look at some of the problems we need to solve before we can use Source Build as Microsoft’s .NET build.
Provide a way to determine what makes it into the product
When you construct a product using the distributed model, the build of the product, the validation of the product and the determination of what actually constitutes the product are all tied together. Source Build operates on a flattened source layout based on a final coherent graph. However, it relies on the traditional .NET product construction process in order to determine what versions of each component show up in the layout. To get the full benefit we need a way to directly update components within the shared source base without complex dependency flow. Otherwise, if a developer wants to make a change in runtime, they will end up building the product twice. Once to flow the runtime build with their change through all paths that runtime reaches, then once again to build the product using that new runtime.
What we have
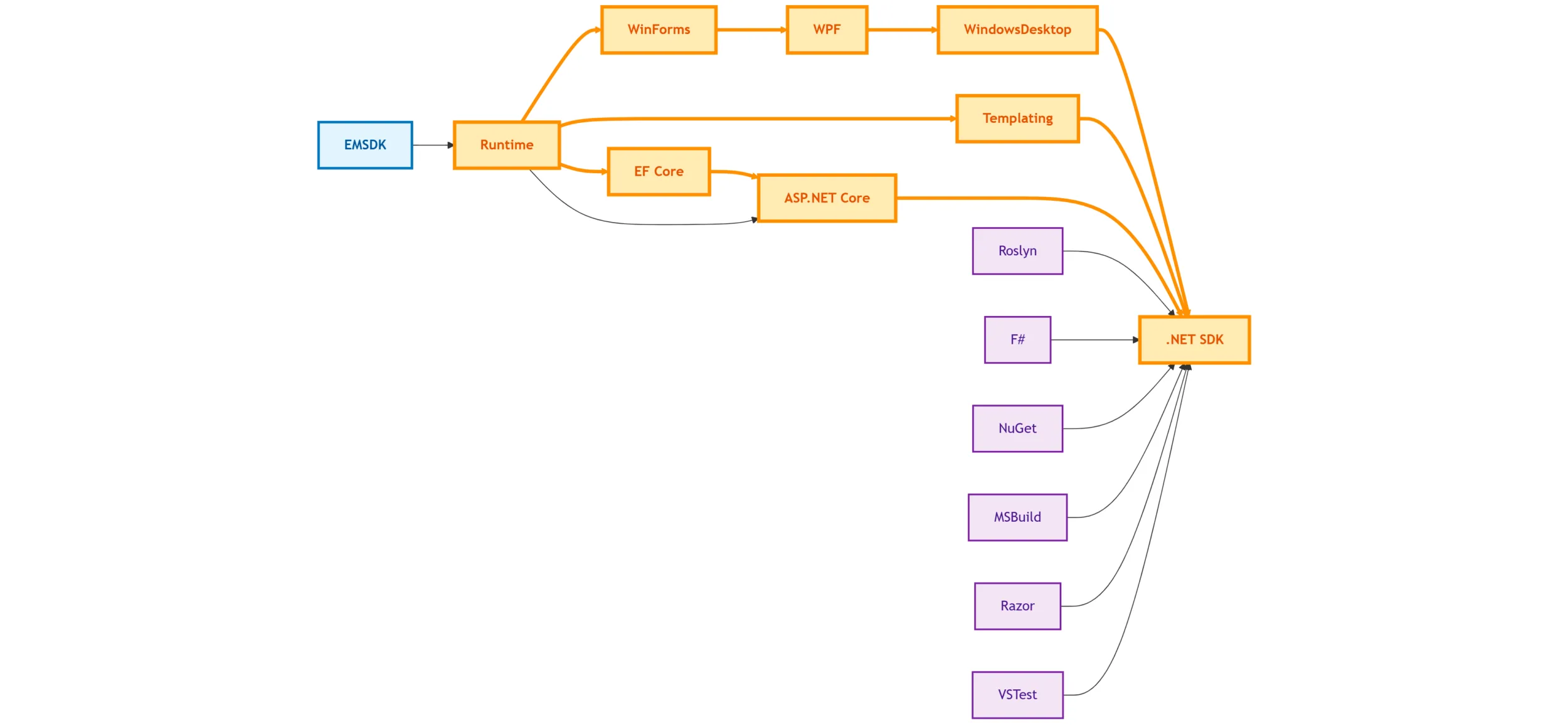 Highlighted paths show how a runtime change cascades through multiple repositories in the distributed build model, requiring sequential builds and dependency flow updates.
Highlighted paths show how a runtime change cascades through multiple repositories in the distributed build model, requiring sequential builds and dependency flow updates.
What we need
 Highlighted path shows how a runtime change immediately flows into the source layout. We call this a ‘flat flow’
Highlighted path shows how a runtime change immediately flows into the source layout. We call this a ‘flat flow’
Provide a way to react to breaking changes
The flat flow significantly reduces the number of hops, and therefore the complexity and overhead in the process of a change making its way into the shared source layout. And we can see that before a change makes it into the product; it will still get PR validation and possibly some more in-depth rolling CI validation. However, let’s say that this change requires reaction in consuming components. Despite the change in dependency flow to a flat flow, ASP.NET Core still depends on .NET Runtime. And ASP.NET Core’s code in the layout doesn’t know about the new runtime change. Whatever PR validation we have before a change is allowed in the shared source layout is sure to fail.
In a traditional dependency flow system, we handle this by making changes in the dependency update PR. If an API is changed, the build breaks. A dev makes a change in the PR (ideally), validation is green, and the PR is merged. For the single-source methodology to work for .NET, we’ll need to be able to make changes to the source of other components in the dotnet/runtime update PR.
Provide a way to validate against repository infrastructure
As we discussed earlier, a large quantity of critical validation lives at the component repository level. That’s where the developers spend their time. Moving or copying all of this is probably wasteful, definitely expensive, and likely hard to maintain. If we can’t rely on the dependency flow to do the validation before components flow into the shared source layout, we’ll need a way to do so after.
To solve our problem, we could have all the outputs of a new product builds flow back into the individual repositories, matching with the dependencies in their Version.Details.xml files. That means dotnet/aspnetcore will get a bunch of new .NET Runtime packages, dotnet/sdk will get a bunch of newly built ASP.NET Core, .NET Runtime and Roslyn compiler packages, etc. They will be validating the ‘last built’ versions of their input dependencies against repository infrastructure.
 Backflow provides a way to validate the recently built .NET output against repository infrastructure
Backflow provides a way to validate the recently built .NET output against repository infrastructure
Provide two-way code flow
Let’s say a runtime insertion PR changed the signature of an API in System.Text.Json. When that forward flows, the responsible dev updates the signatures in all downstream users. Let’s say that’s code in src/aspnetcore/* and src/windowsdesktop/*. The new product is built, and the updated System.Text.Json package with the new API signature makes its way back to dotnet/aspnetcore and dotnet/windowsdesktop. The HEAD of main doesn’t have the source changes made directly in the shared layout forward flow PR. The dev would need to port those changes over, making changes in the backflow PR. This is tedious and error prone. Our new system will need to provide a way to automatically flow changes made in the shared layout back in the source repository.
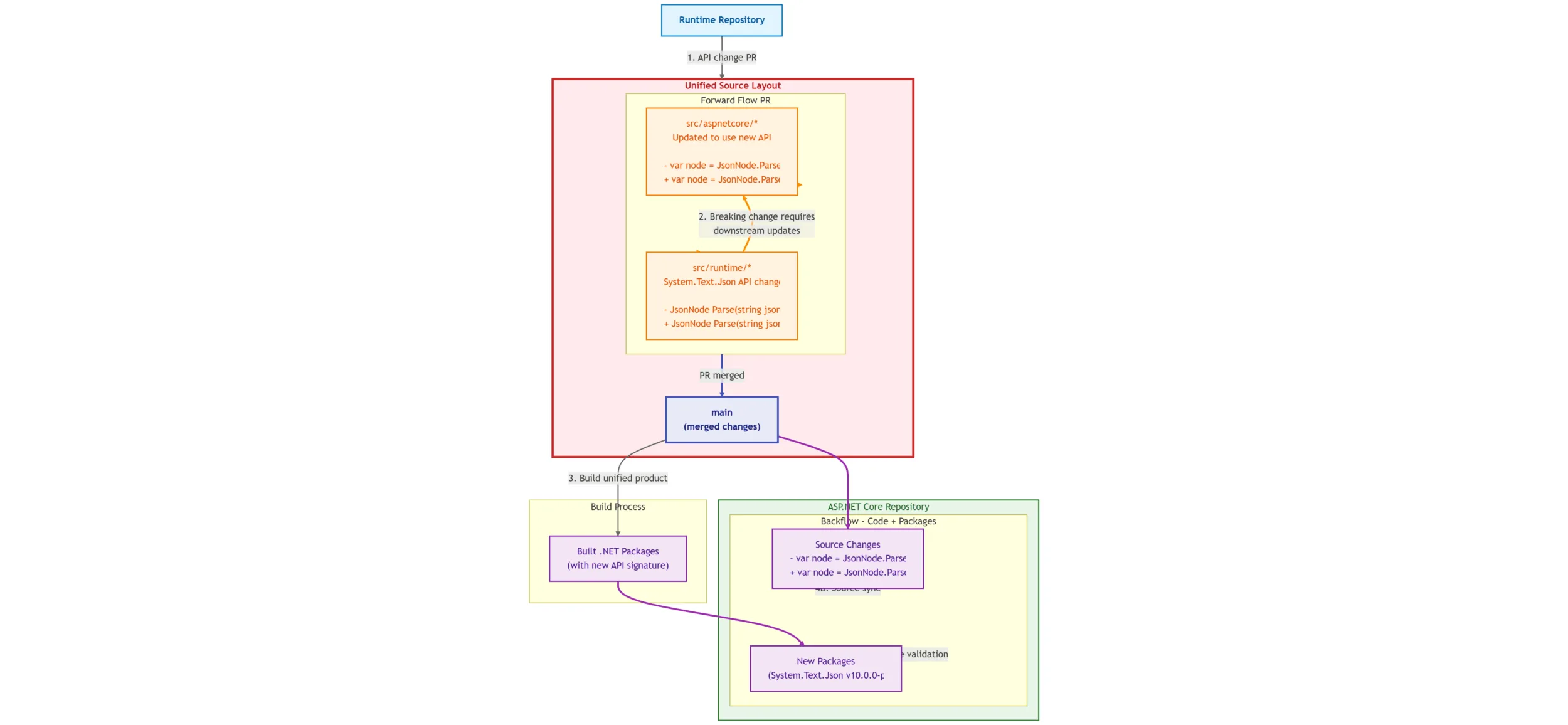 Component changes flow to our shared source layout, additional changes made only in the shared source layout flow back into the component repositories with supporting packages. Note that this is a general capability to backflow shared source changes, not just changes made in forward flow PRs.
Component changes flow to our shared source layout, additional changes made only in the shared source layout flow back into the component repositories with supporting packages. Note that this is a general capability to backflow shared source changes, not just changes made in forward flow PRs.
Provide better insertion time validation
Validation on backflow isn’t perfect. It doesn’t provide an easy pre-merge gate for bad changes in dependent components. We can mitigate this by identifying and closing gaps in repo testing that allowed bad changes to be merged in the originating repo. We can also accept that some things will always slip through and that the process of creating a high-quality product isn’t just a green PR. Many repositories do not and cannot run their full testing suites prior to merging. However, we can also invest scenario testing run against the just-built product. This is something that our traditional dependency flow system is not good at.
Any whole product scenario testing relies on dependency updates for components reaching the dotnet/sdk repository. Up to that point, we don’t have a complete .NET product that we can test. Any attempt is just some kind of “Frankenbuild”. Note: A lot of this end-to-end testing just comes in the form of dotnet/sdk’s repository-level PR/CI testing.. However, changes can take a while to move through the graph to the point there they take effect in a way that would be visible in testing.
The Source Build methodology provides a full product build on each and every component change, regardless of where that component lives in the product construction graph. This means that we have the opportunity to create and run a comprehensive suite of testing on each of those insertions. That testing should be focused on covering wide swaths of product functionality. If this testing passes, there is a reasonable expectation that .NET is functioning in a way that makes it possible for development to make forward progress.
Provide a way to build all of what .NET ships
The Linux distro Source Build offering focuses narrowly on the assets in-box in the 1xx band SDK, ASP.NET Core, Runtime. It builds packages that support the creation of these layouts. As we saw earlier with prebuilt elimination, this narrow focus is necessary to be able to meet distro partner build requirements. If we want to build what Microsoft ships, we can’t have that narrow focus.
Expanding our focus is straightforward in some areas and difficult in others. In some ways, we’re just relaxing restrictions and bringing more functionality back into the build. We need to allow for pre-built binaries (e.g. signing functionality) to be restored from feeds. We need to build all TFMs instead of trimming away .NET Framework targets. We’ll need to build components originally excluded from the souce build focused shared source layout, like Windows Desktop, Winforms, WPF, EMSDK, etc. What’s more difficult are joins. Recall that Linux distro Source Build is single layout, single machine, single invocation. This suffices for producing the layout, but there are a good handful of other artifacts in .NET that require builds on multiple machines. Artifacts that break the single machine verticality concept.
In an ideal world, we’d re-architect the product to avoid these joins. But it’s often hard to do so without customer compromise or driving complexity into the product itself. We can’t simplify the SDK without breaking customers, and this is hard to do, even across major versions, in an enterprise-grade product. Past decisions heavily influence future available choices. In the end, we’ll have to eliminate joins where we can via product construction practices. Any remaining joins will be something we have to live with. The build will have to be architected to run across multiple machines, via a series of build passes.
Executing on the Vision – Shipping Unified Build
The Unified Build project can roughly be divided into 4 phases:
- Initial brainstorming and design (.NET 7) – The initial design work on the Unified Build project began in early 2022 during the development of .NET 7 and took ~4 months to complete. The project got full approval to start later in 2022 with the intention of completion by .NET 9 RTM, with some key go/no-go points where we could bail and still have a net win on infrastructure.
- Foundational work (.NET 8) – The Unified Build project during .NET 8 was focused on foundational work to improve the sustainability of the Source Build infrastructure and building features that were required to support the weight of the full build. The investments were designed to be a net positive for .NET overall, even if it turned out that our proof-of-concept stage discovered some major unknown problem and we had to change direction.
- Vertical Build/Code Flow Exploration (Early .NET 9) – After the foundational work completed, we moved to implement a vertical build for each of the 3 major OS families: Mac, Windows, and Linux. The intention was to identify as many of the problems we would need to solve during our productization phase as possible. We were especially interested in finding any previously unknown product construction join points. At the same time, we did a much deeper investigation into the options for code flow and code management, eventually proving out and settling on the implementation listed below.
- Productization (Late .NET 9-.NET 10) – Final implementation started in earnest towards the end of .NET 9 after a spring+summer delay. As a result of the delay, the ship date was pushed back to .NET 10. This turned out to be a blessing in disguise. This bought us about 6 extra months of bake time and allowed us to use the Unified Build product construction process starting midway through the .NET 10 Preview/RC cycle (Preview 4). .NET Preview 4 shipped with the new build process, but on the old code flow. Preview 5 added the new code flow, and we never looked back. Further refinement in developer workflow, more bake time for the build and code flow process happened over subsequent months.
And finally, after almost 4 years of dreaming and work, Unified Build shipped with .NET 10 RTM!
Let’s take a look at the key components of the project.
VMR – The Virtual Monolithic Repository
The dotnet/dotnet VMR, or “Virtual Monolithic Repository” forms the cornerstone of the Unified Build project. It is the source layout from which all of .NET is built, including by our Linux distro partners. It is the orchestrator. Functionally, it’s not much different from the source layout used prior to .NET 8.0. That layout has just been formalized into a git repository (vs. a source tarball). This is key, as it allows developers to work both in their individual component repository, where dev workflows might be very refined, as well as in the VMR when cross-cutting changes are necessary. .NET gets most of the benefits of the distributed repo world, without coherency problems.
Vertical Build
Vertical Build is .NET’s pivot to producing assets in a series of verticals. A vertical is defined as a single build command on a single machine that builds part of the .NET product without input from other verticals. Typically, we divide verticals up by the runtime that we’re trying to produce. For example, Windows x64 vs. MonoAOT vs. Linux arm64 vs. PGO profile Windows x86. Altogether there are 35-40 different verticals. We divide these into what we call “short stacks” and “tall stacks”. A short stack just builds the runtime. A tall stack builds all the way up through the SDK.
The original vision was that if we joined together all the outputs from parallel verticals, we’d have everything .NET needed to ship. Such a setup would be highly efficient and friendly to any upstream partners. Unfortunately, the design of the .NET product has baked in a few required joins over the years. For example, .NET workload packages can’t be built without access to numerous packages built across many operating systems. To resolve this, we ended up with two additional build passes. The good news is that those additional passes are on a reduced set of verticals and a reduced set of components within those verticals. Not perfect, but manageable.
Code flow
Probably the most interesting aspect of the Unified Build project is how code flow is managed. This is where .NET turns standard development patterns on their head a little bit. As detailed earlier, maintaining the product as a graph of interdependent components while flattening code flow into a shared coherent layout requires “two-way” code flow. Changes need to flow from components into the shared layout, and changes in the shared layout need to be able to flow back to the component repositories. Conceptually the code flow algorithm is no more complicated than anything you can model within a single git repository for a given project. The trick is to do this with repositories with no related git history.
Note: The nitty gritty details of this algorithm will be covered in a future post by another team member. I’ll update this post to link to it when it’s available.
For now, let’s take a look at the basics:
Both the VMR and the component repository keep track of the last code flow from their partner. This is tracked alongside standard dependency information in eng/Version.Details.xml, though one could imagine it could be kept elsewhere.
- dotnet/runtime knows the VMR SHA of the last “backflow“, which is the flow from the VMR to dotnet/runtime
- The VMR knows the dotnet/runtime SHA of the last “forward flow“, which is the flow from dotnet/runtime to the VMR.
The idea is to determine the diff between the “last flow” and whatever is flowing in now. For example, in a very simple case, when a new commit is made to dotnet/runtime and no changes have been made to src/dotnet/runtime in the VMR, the dependency flow system will take the following steps:
- Determine two points, A and B, for which to compute a diff. For this case, point A is the last flow of dotnet/runtime that was checked in to the VMR (or is currently in PR). Point B is the new commit to dotnet/runtime.
- Construct a patch file, remapping the files src/runtime files onto the directory structure of the VMR.
- Open a PR with the diffs. See an example forward flow and an example back flow.
.NET 8 and .NET 9 use VMRs with only one-way code flow. These cases with no changes on the other side are trivial and robust. Things get spicier when developers start making changes on both sides, and when dependency flow starts shifting around over time.
- Computing the diff points gets more interesting and involves knowing which way that “last flow” was.
- Merge conflicts arise and need to be dealt with in a way the developer can understand.
- Changes in the source and target of code flow can cause havoc and need robust error handling and recovery mechanisms.
I’ll leave code flow there for now. Stay tuned for more.
Scenario Test Validation
The last major pillar of Unified Build is additional scenario testing. To be clear, .NET does not lack testing. .NET Runtime could use month’s worth of machine time on every PR to validate its millions of tests if it were practical or pragmatic to do so. Our approval, build, validation and signoff procedures ensure high-quality shipping bits. Still, when making changes directly in the VMR, the flat flow introduces new lag between that making that change and in-depth validation of it against each of the VMR components. While we can’t run every last test on PR and CI, we did recognize that better automated scenario testing could play a solid role in preventing regressions. The goal was to add tests that covered wide swaths of product functionality that were not directly tied to the build system or repository infrastructure. Instead, they executed against the final built product. If the scenario tests pass, then there is a good sense that the product is functional at a decent level and contributors won’t be blocked.
Results
So, what did .NET get for almost 4 years of dreaming, scheming, and hard work? That’s a lot of effort to put into one project. Did the outcome justify the investment? As it turns out, we got quite a lot.
Let’s start with the most visible outcomes and then take a peek under the covers.
Flexibility, predictability and speed
By far the biggest return we’ve seen on the investment is flexibility. Distributed product construction is slow. Producing coherent builds is slow. Checking in new fixes or content requires coordination to avoid “resetting the build”, because what you want to ship, and how you build it are tied together in a distributed, OSS-style ecosystem. Taking a new fix might mean you don’t have something ready to handoff for validation. Flat flow eliminates that coherency problem, separating the what and the how. This is incredibly valuable during the drive towards an RTM build or a servicing release. It means we can make fixes later in the release cycle, focusing much more on whether those fixes meet our servicing bar and much less on whether we can actually build and deliver the change. That flexibility is good for customers.
Some of that flexibility comes from the speed of the build. This may sound glacially slow (.NET is a big, complex product), but .NET set a goal of producing an unsigned build in less than 4 hours, signed in less than 7. That’s down from significantly longer times in .NET 8.0 and .NET 9.0. A build of 8.0 or 9.0 can easily run to 24 even if everything goes perfectly. A signed build in 7 hours means a rolling set of new .NET assets to validate ~3 times a day. Most of that build time improvement comes from simply removing overhead.
Some of the flexibility also comes from predictability. Distributed product construction has more moving parts. It has more human touch points. More places for systems and processes to fail. This tends to make outcomes unpredictable. “If I check in a fix to dotnet/runtime, when will I have a build ready?” is a hard question to answer in a distributed system. I know how long dotnet/runtime’s build takes. But at what time will that change show up downstream via dependency flow? Will someone be around to review and approve it when it does? What’s the status of PR/CI validation downstream? Will a new important change be merged into dotnet/aspnetcore before we get a coherent build, setting us back on validation? This question is vastly easier to answer in .NET 10. The change flows into the VMR (or is made there directly) and will show up in the next build. The next build will take N hours.
Infrastructural robustness and completeness
Behind the flashier metrics, there are years of quality-of-life improvements to the infrastructure that pay major dividends day in and day out. Improvements to the Source Build infrastructure in .NET 8 reduced the cost of keeping Linux distro Source Build running. A lot of its cost was related to the delay between a change getting checked in and discovering whether it would break the build when it finally flowed through the graph and reached the shared source layout. It was not uncommon for the Source Build .NET SDK to not be “prebuilt-clean” or shippable by distro partners until the middle of the previews. The infrastructure improvements in .NET 8 made it much easier to identify new pre-built inputs at PR time when they are easier to diagnose and resolve, before they made their way in the source layout. We are now prebuilt clean 100% of the time. That then reduced the load on the Source Build team, which gave them bandwidth to work in other areas. They added build parallelism, more predictable dependency flow, better logging, removed unneccessary complexity…the list goes on and on. Investments that make a product successful.
Our signing tooling had to be overhauled to support signing on every platform for a wide variety of archive types. Without this work, we couldn’t have shipped Unified Build. But this expanded support benefits more than just the core .NET product. There are numerous ancillary repositories that were able to simplify their builds, avoiding shuttling bits from Mac/Linux to Windows machines where the signing tooling ran. Lower build overhead, faster and simpler builds.
Future directions
So where does the Unified Build project go next? While we won’t have the same level of investment in .NET 11, we’ll be making targeted improvements to the infrastructure to improve developer workflow and UX, mainly around code flow. One area I’m particularly excited about is AI agents that monitor code flow, connecting the dots between the various systems involved in creating the product and identifying issues. There are lots of systems and parties involved (Azure DevOps, GitHub, the code flow services and their configuration, code mirroring, developer approvals, machine allocation, etc.) in making a change go from PR to product. When it works, it works. When it doesn’t it’s often down to a human to track down exactly where the chain of events went wrong. It’s tedious and time consuming. We have tools, but it’s mainly about connecting lots of dots. We could write a rules engine for this, but my hunch is that it would be fragile and very complicated. Agents that can look at the system a little more fuzzily are ideally suited to this type of task. Less toil, a better .NET.
Lastly, beyond .NET 11, another push to get rid of join points might be on the horizon. The benefits are pretty clear: simpler, faster, and friendlier to contributors. We know now exactly how fast a build would be if you got rid of the remaining joins (less than 4 hours).
Conclusion
If you made it this far, thanks! It’s good to provide some insight into how .NET build and ships. You’ve learned how distributed dependency flow product construction models aren’t always a great fit for shipping software predictably and reliably. These systems tend to have high complexity and overhead, which adds time. You’ve read about the roots of the .NET Unified Build project in .NET Linux distro Source Build, and what made it difficult to apply those concepts to .NET. Lastly, you learned how .NET applied those concepts and the drastic improvements we’ve seen in our day-to-day work.
The blog post detailing the flat code flow algorithms should be along shortly. Stay tuned!
Matt, can you speak to why some downstream packages like System.ServiceModel.* appear to be broken? From an end-to-end product construction perspective, it seems like this bug report in the WCF repository is your teams responsibility to verify proper packaging. https://github.com/dotnet/wcf/issues/5868 - I actually had a hard time following how everything you wrote above relates to issues I experience as a customer, but can also deeply appreciate that CI processes at your scale are extremely complex. I apologize if you're not actually the right person to "own" these issues, but even when I look at the release notes for WCF, nothing...
Responded on the WCF GitHub issue. We don’t have insight into these layers on top of .NET when we ship. We’ll get the issue routed to the right place though.
Love the Talking Heads reference!
I tried to work talking heads references into all the headings but it was a bit awkward.
Wow… thank you for putting this together. First, I intimately know how difficult it is to write something like this, from both a structural perspective, but also needing to remember your audience doesn’t have the same institutional knowledge you do.
You have not only accomplished in giving us some amazing content but also help ed demystify things that I’ve made general assumptions for previously (even with having insider/NDA knowledge as a .NET Microsoft MVP). I look forward to future posts from you, keeping us in the loop!
P.S. This post is trending in dev circles 🙂
Great article. Love reading a detailed description of how such a complex problem has been solved. Any chance of turning Maestro into a shippable product? 🙂
It’s open source today, over at https://github.com/dotnet/arcade-services. We have deployed it for use by other teams occasionally. That said, at this point I’d still call it a fairly customized piece of software that’s targeted at .NET’s use cases.
Watch out @Stephen Toub, there’s a new dog in town.
Such a breath of fresh air to read about some real engineering challenges instead of trying to shoehorn AI into everything.
I haven’t yet finished the whole article as I’ll consume it in chunks, but wanted to say it’s a very refreshing and interesting read! Thank you!
be warned that AI does get a look in at the end 🙂 but sounds like a good use of it
Yeah, I think that use of AI to monitor and point out issues is a really ideal use case for an agent-based workflow. It's a tedious process today that a dev ends up doing, when they could end up doing more valuable work. It's a bit fuzzy. You need context across a bunch of systems and data sources. You need to know what state a repo's build is in, you need to know what PRs are open, you need to know about any known issues (e.g. a network issue causing problems with MacOS builds). You need to know what the...