
Real-time, event-driven applications are now the expectation, not the exception. Teams want dashboards that update the instant something happens, microservices that react the moment data lands, and pipelines that move changes downstream without polling a database on a timer. Since Change Streams reached General Availability in Azure DocumentDB, that pattern has been production-ready and the feature has kept getting better.
Here’s a quick tour of what’s new since GA, with the headline being three of the most requested capabilities: richer change events, historical replay, and Multi-Node Change Streams, now in Public Preview.
The Idea in One Picture
Change streams turn your database into an event source. A producer writes data, the database publishes each change, and one or more consumers subscribe with a single watch() call and react in real time, no polling required.
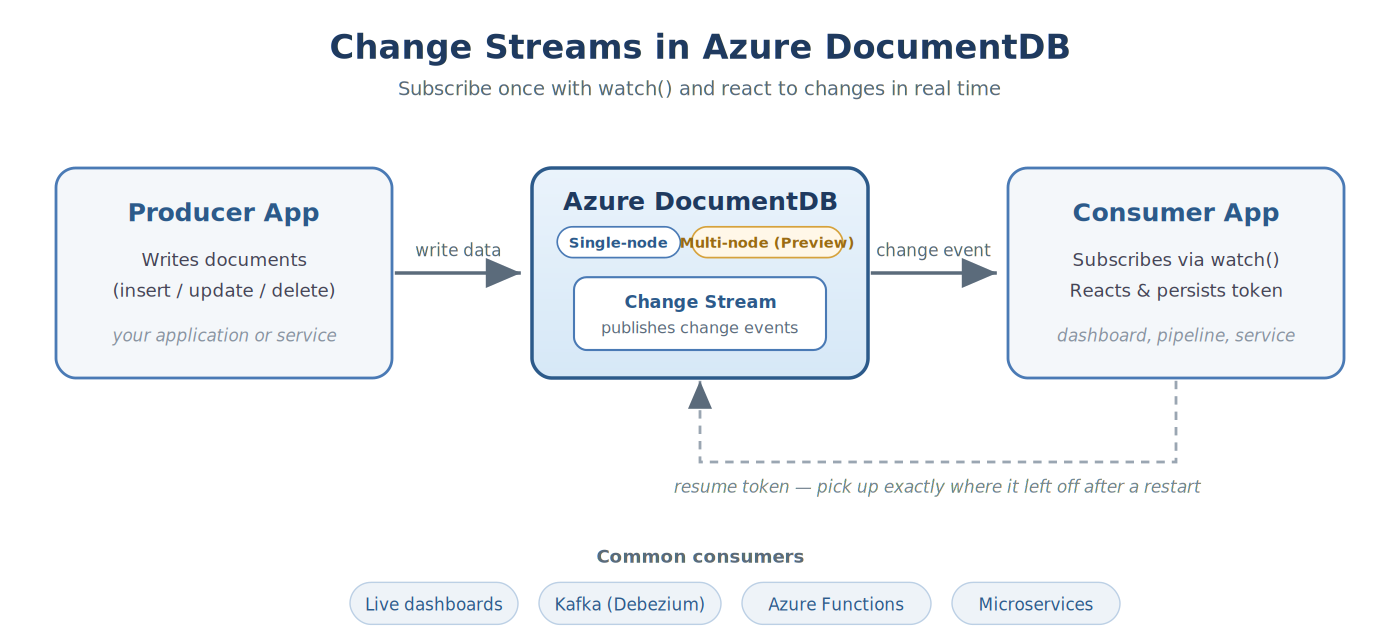
The consumer does two things: process each event, and persist a resume token so it can pick up exactly where it left off after a restart, deploy, or scale event, no missed changes.
Getting started is genuinely a one-liner:
const changeStream = db.exampleCollection.watch();
for (const change of changeStream) {
processEvent(change); // each event carries operationType, fullDocument, ns, and a resume token
}What’s New Since GA
Richer change events: update descriptions and pre-images
Change events now tell you more about what changed, not just the end state. Update descriptions surface the exact fields that were added, removed, or modified, ideal for change-data-capture and audit pipelines that only want to propagate deltas. And pre-images let an event include the full document as it looked before the change, so you can answer “what was the old value?” without a separate lookup.
Pre-images are opt-in per collection and come with flexible modes (include-if-available vs. strictly required), since capturing the prior version of each document adds some storage and processing overhead. The official docs cover the modes and the trade-offs in detail.
Historical Change Streams: replay the past
Standard change streams live within an active change log, so once it rotates, older events are out of reach. Historical Change Streams remove that ceiling, you can replay or resume from a past point in time, with point-in-time-restore integration extending recovery to roughly the last month of activity. This is a big deal for backfilling a new downstream system, recovering a consumer that fell behind, or reprocessing after a bug fix.
Broader driver compatibility across languages
Change streams use the standard watch() API, no special SDK or proprietary library. The companion driver-compatibility repo ships runnable consumer examples in six languages, each following the same resilient shape: resume if a token exists, otherwise start fresh, and persist the token after every processed event.
| Language | Driver |
|---|---|
| Python | PyMongo |
| Java | MongoDB Java Driver |
| Node.js | Mongoose |
| C# | MongoDB .NET Driver |
| Go | MongoDB Go Driver |
| Ruby | MongoDB Ruby Driver |
The pattern looks the same everywhere, here it is in Python:
resume_token = load_resume_token()
stream = collection.watch(resume_after=resume_token) if resume_token else collection.watch()
with stream:
for change in stream:
process(change)
save_resume_token(change["_id"]) # persist after each eventKafka integration via the Debezium connector
For larger event-driven architectures, change events can stream straight into Apache Kafka topics through the Debezium connector, turning your database into a first-class event source for distributed pipelines, no bespoke glue code. A runnable delivery-tracking sample app shows the end-to-end flow.
Customizable event pipelines
You can shape each consumer’s feed by passing aggregation stages to watch(),filtering to only the operations and fields you care about keeps payloads lean and consumers focused.
const stream = db.exampleCollection.watch([
{ $match: { operationType: "insert", "fullDocument.department": "IT" } },
{ $project: { "fullDocument.name": 1, "fullDocument.position": 1 } }
]);Multi-Node Change Streams (Public Preview)
Until recently, change streams were supported on single-shard clusters only, which left the largest, highest-throughput deployments without real-time change capture unless they engineered workarounds. That’s the gap Multi-Node Change Streams close, and they’re now in Public Preview.
As your data grows, you scale horizontally across multiple shards. Multi-Node Change Streams let you capture changes across that sharded, multi-node topology while keeping the exact same watch() programming model – consumer code, resume-token handling, and driver support all stay identical. Only the topology underneath changes.
A few things to design for during preview: ordering is guaranteed per shard key rather than globally across the cluster, a cluster’s transition from single-shard to multi-shard affects resumability, and cursors reinitialize after a failover (resume capability is preserved). Because it’s a preview, it’s a great moment to validate against your workloads in non-production, exercise resume and failover handling on a multi-node topology, and share feedback that shapes the road to GA.
Get Started Today
With this GA release, Change Streams is ready for production workloads. Explore the full potential of this feature through the official documentation.
We’re excited to see what you’ll build next with Azure DocumentDB and Change Streams!
About Azure DocumentDB
Azure DocumentDB is a fully managed document database service for building and modernizing MongoDB-compatible applications. Powered by the open-source DocumentDB engine, it combines familiar APIs, tools, and workflows with Azure’s security, scalability, and operational simplicity. Whether you’re developing new applications or migrating existing MongoDB workloads, Azure DocumentDB helps you get started quickly and scale with confidence.
0 comments
Be the first to start the discussion.