
Optimizing Fashion Retail Inventory Management With Deep Learning Content-based Image Retrieval
Background
The online fashion retail space continues to boom, as modern consumers increasingly lean towards a more convenient remote buying experience. However, to stay ahead of the competition, leading retail brands need to offer an ever evolving catalogue of seasons, styles and sizes on their platforms. This poses a challenge for inventory management, when constantly updating and removing available items daily.
For warehouse staff, and catalogue managers, one of the biggest challenges is developing an efficient system to log new items while on the move, and quickly determine whether the item is already in stock. When dealing with such large catalogues, the traditional method of manually checking each garment from millions of items, would slow processes to a snail’s pace.
In early 2018, Microsoft partnered with a successful international online fashion retailer to find a solution. Our mission was to develop techniques capable of identifying whether a newly arrived item was already in stock, using only a mobile phone image as a source. In Deep Learning Image Segmentation for Ecommerce Catalogue Visual Search, we outlined how we solved the problem of differentiating between the visual environment of the source image and its target match, by using a computer vision approach known as GrabCut, and a deep learning segmentation approach, Tiramisu for background removal.
Our next challenge was to deal with the issue of staging, and differentiating between visually similar items.
Challenges and Objective
Managing an ever-changing inventory of millions of items presents lots of challenges. Firstly, to keep the catalogue up to date, and secondly to ensure that the catalogue is well organized, without any duplicates.
Duplicates occur when staff enter the same item twice unintentionally using two unique product codes. Previously, the only ways to differentiate between items were to manually inspect them, or examine their metadata — such as, brand, gender, and types of garment –, both of which are time consuming and ineffective, if there exists millions of items in the inventory.
To maximize efficiency for employees, we needed to find a way to speed up the process of searching for an item using just a mobile phone snapshot. We identified two objectives that could help us achieve this:
- Highlight and remove duplicate apparel items from the catalogue of millions of professionally photographed items. The aim is to ‘clean up’ the existing catalogue.
- Retrieve image of studio quality with white background from catalogue, using the input of a lower quality mobile phone photo with a busy background. The aim is to reduce the chances of duplicate entry in the future.
Framing these two scenarios into a content-based image retrieval context poses challenges due to staging: the way an item is presented when photographed.
If the same item is accidently entered into the catalogue twice, the two versions of its photograph may be visually different. This could be due to the way the item is positioned on a mannequin, due to creases or folding, different scale, point-of-view, or the draping of the item (Figure 1). At the same time, highlighting different items with the same fabric and colour, but with slight differences in style, which still look extremely similar, also posed another problem to be solved.(Figure 2).
 |
 |
 |
 |
Figure 1: Identical product, displayed and photographed differently.
 |
 |
 |
 |
Figure 2: Visually extremely similar items, but different products.
Addressing the second objective of preventing duplicate entry, the fact that we needed to retrieve matching catalogue items using low quality mobile phone snapshots only further complicates the situation. Figure 3 shows a clear example of the challenges matching query images taken by mobile phone, with the desired studio quality target image. In this example, the visual content, i.e. the RGB values, is rather different, the background features non-relevant information, the size of the item, colouration and positioning differ, the point-of-view is from a new angle and the creases and folding vary.
The top row in Figure 3 shows a mobile snapshot with a busy background, compared to the studio quality target image. The buttons are done up differently, and the folding and colouration would make it hard to determine whether they belong to the same item. The second row of Figure 3 shows an example in which important features, such as text, are hidden, coupled with discolouration and distinct folding.
 |
 |
 |
 |
Figure 3: Query image and target image.
In both cases, there are times when even a human would find it difficult to decide whether the two images belong to the same item. Furthermore, the inventory data systems allow for only one catalogue image per item, posing a challenge in any deep learning approaches.
Methodologies
We assumed that the catalogue image retrieval using a mobile phone image would pose more challenges than when highlighting duplicates from a catalogue. As such, we hypothesize that if a technique is useful for the former, it would also most likely be effective for the latter. Therefore, the following discussion will focus mostly on the retrieval challenge, and only lightly touch on the duplicates removal case.
We tackled the image retrieval challenge in two stages. First, we removed the background of the query image to improve the chances of the algorithms finding the right match. Then, we transformed the segmented region into a new representation, before applying similarity metrics. (Figure 4).
Figure 4: The background of a query image is removed, leaving the region of interest, i.e. the apparel, which is then transformed into a new representation before calculating the distance measure.
For both the segmentation and transformation stages, we experimented with computer vision (CV) and deep learning (DL) approaches as listed in Table 1:
| Segmentation | Image Similarity |
| GrabCut (CV) | GIST + distance metrics (CV) |
| Tiramisu (DL)
* Specifically trained with this data set for apparel segmentation |
ConvNet + dimensionality reduction + distance metrics (DL) |
| Retrain Resnet18 + SVM (DL) |
Table 1: Segmentation and image similarity using computer vision and deep learning approaches.
Segmentation
For segmentation we first used GrabCut, a computer vision approach created over a decade ago, and then Tiramisu, a recent deep learning approach. A Tiramisu-based apparel segmentation model has been developed for this specific use.
Image Similarity
We experimented with two different approaches to rank the images by similarity: GIST, a computer vision approach, and convolutional network approaches, largely inspired by i) this reverse image search and retrieval technique, and ii) this image similarity ranking technique.
1. GIST
GIST is a context-based approach which takes the whole image into consideration, instead of focusing on specific features. It involves low-level feature extractions (colour, intensity, orientation, etc), and then aggregates the image statistics and semantics.
As such, it is less affected by background noise, which locally based techniques are more prone to. While GIST was initially designed to recognize different landscapes, and has since been used in web-scale image searches, we decided to use GIST as a baseline for recognizing differences in clothes.
To transform the image into a GIST descriptor vector, we used pyleargist implementation to produce a 1×960 descriptor vector for each image, before using distance metrics to measure similarity. In this case, we used Euclidean distance. This same method was used for catalogue cleaning and catalogue image retrieval using mobile phone images.
2. Using a Pre-trained Convolutional Network as a Feature Extractor
For this method we used a pre-trained convolutional neural network as a feature extractor, PCA was then applied to the segmented query image, reducing the segmented region of interest (the garment) into respective PCA representation. Finally, we compared pairwise Euclidean distances between the PCA representation of the catalogue images, and those of the segmented region from mobile snapshots.
For this process, we experimented using VGG16, ResNet50 and MobileNet, and chose the number of PCA components as 210, 205 and 225 respectively, based on the percentage of cumulative explained variance of 99%.
3. Retraining ResNet18 with Custom Dataset
Representing images as the feature map of a DNN is proven to offer great results on a wide variety of tasks. Using this approach, we fine-tuned the pre-trained network before computing the image representations to optimize performance.
To do this, we started with an original pre-trained model, trained with a large set of generic images, before using a smaller set of catalogue images to fine-tune the network. The lower layers of a deep neural network learn the basic features of an image, upon which higher layers then built upon. As such, we used these learned features, and replaced the top layer responsible for predicting the actual class labels, with a new dense layer able to predict the classes elected for the new task. The input to the old and the new prediction layer was the same, so we simply reused the trained features. Using a custom dataset, we then placed individual images in classes according to their attributes, which were chosen manually. Some example attributes include:
- Check shirts
- Long sleeves
- Jackets
- Solid round neck
Experimentations
Our main aim was to retrieve respective catalogue image using a mobile image. While highlighting duplicates in catalogue for removal is important, we assumed that the former would be more challenging given the poor quality of the query image. If a methodology could successfully be used for catalogue image retrieval, it could also be readily applied to the case of catalogue cleaning.
Therefore, the following experimentations will be mainly discussions on catalogue image retrieval, although there is one experimental result applying GIST on duplicates removal as an example.
Data
The data used in these experiments is privately owned.
In the case of highlighting duplicates in catalogue for removal, we used a set of 380,000 of catalogue images, featuring 934 duplicated entries. Duplicate entries here refer to studio photographs of the same merchandise item, taken at two different occasions, as seen in Figure 1.
For catalogue image retrieval using mobile images, we used 249 pairs of mobile images and associated catalogue images, resized to 516 x 516 pixels. Each of the 249 catalogue images were unique, representing 249 apparel items. Similarly, the corresponding 249 mobile images each belonged to a unique apparel item. The mobile images were segmented via automated GrabCut and Tiramisu for performance comparison.
Removing Duplicates From Catalogue
We applied GIST to remove duplicates from the existing catalogue. The test catalogue contained 934 duplicates amongst the 380,000 total images. This method managed to correctly identify 280 duplicated pairs of items out of the 934 in the catalogue, accounting for 30% of the known duplicates. This performance was calculated only on the closest matched image according to corresponding GIST descriptors measured by Euclidean distance, that is, the 1st matched.
The result of 30% is difficult to interpret due to i) the existence of other unknown duplicates, ii) human error due to high ambiguity between items as depicted in Figure 2. Sifting through the results of 380,000 comparison was deemed too time consuming for the limits of this project. However, it would be useful to understand if this method can also successfully retrieve unknown duplicates, which after all, is the ultimate goal for the large-scale retailers. While this experiment only took the first closest match into account, in practice, it would be useful to retrieve the top 10 closest matches for visual inspection, and to decide which one is correctly identified duplicate. This itself is extremely challenging due to ambiguity illustrated by Figure 1 and Figure 2.
Figures 5 – 7 illustrate some examples of applying GIST on catalogue cleaning scenario. Figure 5 shows an example of an incorrect match, a case in which it would be difficult even for a human to be sure whether the two items are the same.
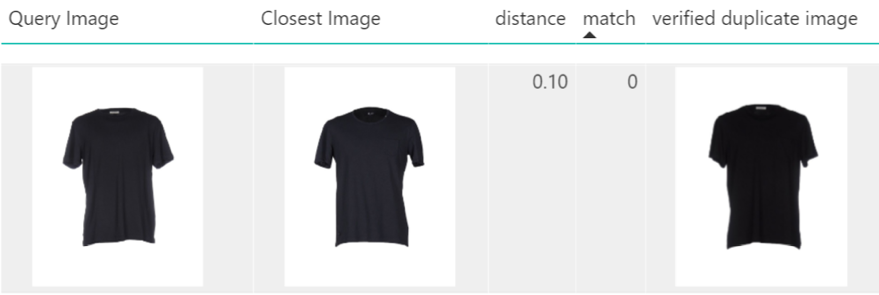
Figure 5: Example of an incorrect match, a case which it is difficult even for a human to be confident about whether those two items are of the same.

Figure 6: Example of an incorrect match that is obvious.
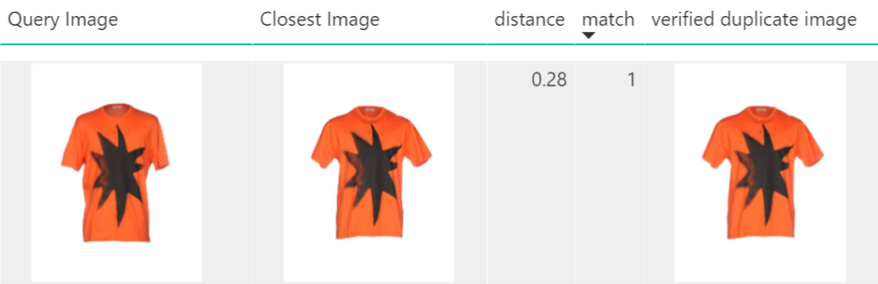
Figure 7: Example of a correct match.
Catalogue Image Retrieval Given Mobile Snapshot
For catalogue image retrieval, we used 249 pairs of mobile images and their associated catalogue images. For this experiment, we compared the effects that different segmentation tools had on the final performance using the GIST methodology. The mobile images were then segmented using automated GrabCut and Tiramisu methods respectively.
It appeared that applying GIST onto GrabCut segmented mobile snapshots produced similar retrieval results to that of Tiramisu, with GrabCut performing slightly better. Then, we applied the convolutional network methodologies onto a mobile snapshot on which the background had been removed by GrabCut. You can find a comparison of the retrieval rates in the Results section.
Figures 8 -9 show examples of retrieval results, with the top 5 closest matches when GIST was applied to GrabCut and Tiramisu segmented query images.
Figure 10 shows examples of when Resnet50 pre-trained ImageNet was applied as a feature extractor onto GrabCut segmented query images. Figure 11 shows examples of retrieval based on the retrained Resnet15 approach.

|

Figure 8: Retrieval results when applying GIST on GrabCut segmented query images.

|

Figure 9: Retrieval results when applying GIST on Tiramisu segmented query images.

|

Figure 10: Retrieval results when applying Resnet50 pre-trained ImageNet as the feature extractor onto GrabCut segmented query images.
 |
Figure 11: Retrieval results when applying re-trained Resnet15 and SVM, onto GrabCut segmented query images.
Results
This section discusses the performance of the above-mentioned methodologies when applied to catalogue image retrieval using a mobile snapshot:
The performance metric chosen here uses the top 10th most similar images returned by the technique, with the cumulative rate of accuracy given at every nth image returned when the nth catalogue image is a correct match for the query image (the segmented mobile snapshot).
The graph in Figure 12 shows the accuracy for the top nth correctly retrieved image from the catalogue of 249 apparel items, when using a query mobile image:
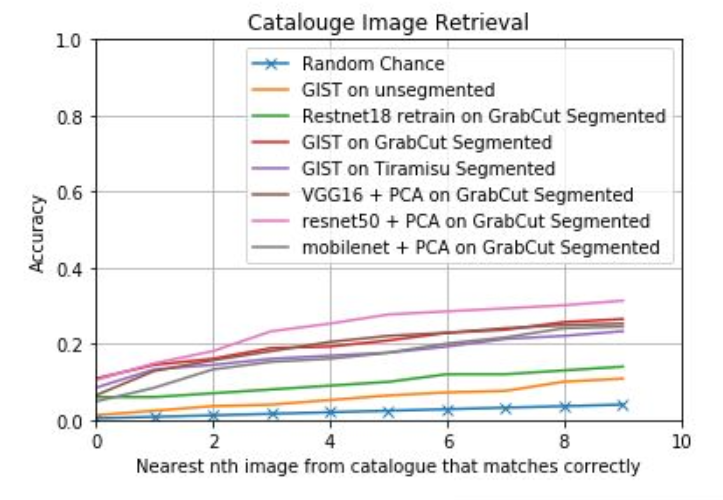 Figure 12: Results comparing all the methods.
Figure 12: Results comparing all the methods.
We used random chance as a ‘naïve’ baseline (-x-) to ensure a meaningful comparison was made between all of the methods that we experimented with, and that they do better than random chance.
Firstly, we used the GIST methodology to retrieve the top 10th closest matched catalogue images. We chose a computer vision technique as the baseline due to recent advancement in the deep learning approach, which in many cases, if not matching human performance, exceeded it. We expect to achieve better results than a computer vision technique when using deep learning approaches.
The GIST method was then applied onto three variations of a query mobile image:
- unsegmented
- backgrounds were removed via GrabCut
- backgrounds were removed via specially trained Tiramisu architecture.
The performance was considerably better when the background was removed before measuring image similarity.
While the specially trained Tiramisu-based apparel image segmenter gave very similar results to that of GrabCut, it slightly underperformed when compared to the retrieval rate using images segmented using GrabCut.
Secondly, we applied three convolutional networks pre-trained with imagenet as feature extractors, using PCA as dimension reducer:
- VGG16
- Resnet50
- Mobilenet
The VGG16 retrieval rate was extremely close to that of GIST on GrabCut segmented query images, while mobilenet slightly underperformed. The best performer in this setting was Resnet50.
It is interesting to note that the computer vision technique GIST was on-par with the convolutional network approach VGG16.
It is important to mention that we didn’t need to re-train for these specific experiments, but that re-training the network, especially the last few layers would most likely have improved the overall performance.
Thirdly, we retrained Resnet15 with visually different apparel in attempt to fine-tune the pre-trained model. A few possible reasons why this technique has yet to demonstrate sufficient performance could be due to:
- Annotations made during training were of poor quality, and taken as verbatim from the explanation in the reference examples.
- We assumed each image only had a single attribute, when in fact the images had multiple attributes. This may have confused the network.
- Forcing the network to choose between a fixed set of attributes forced it to learn distributed representation, which is not of much use when searching for similar images.
Future Work
We started to explore the method of fine-tuning a convolutional network with studio catalogue images, based on the hypothesis that a network trained specifically using this type of data would yield a higher performance when used as a feature extractor to retrieve closely matched images.
We were able to cluster those catalogue images into n-number of clusters. However, the next step would be to develop a systematic method to determine the optimum number of clusters by working closely with market leaders in the online fashion space, and with further statistical research.
Once an entire catalogue featuring several hundreds of thousands of images segregated into distinct clusters based on appearance characteristics is created, these labelled images can then be used to fine-tune a convolutional network, and re-train the last few layers of the networks which have already been tested.
Another possible approach would be to apply a Siamese network, where the segmentation step could be removed, creating a one-step process in which the original query input image of a garment from a mobile snapshot would not need to be segmented before being fed into a predictor.
Similarly, using an auto encoder is under consideration. Not only due to its ability to learn the latent space, but also because it has proven useful accurately matching a noisy image with a clean image. One way to approach this problem could be in treating the mobile snapshot as ‘noisy’, while considering the corresponding catalogue image as ‘clean’. However, the notion of ‘noisy’ in this case is far more complex.
Summary
Image retrieval has been used in a number of applications, however, it is rather new when applied to the fashion retail industry within this context.
In this project, we applied the computer vision technique GIST to highlight duplicates within a catalogue for removal. We also applied GIST and a pre-trained convolutional network as feature extractors to assess image content similarity for image retrieval from online catalogues. Our studies highlighted the considerable effect that background removal has on the outcome of retrieval techniques, and illustrated the performance of computer vision technique, GIST, and convolutional network approaches as feature extractors. this project highlighted that a deep learning approach performs better than a computer vision technique by a some margin.
While our tool was created for applications in retail inventory management, we hope our approach can also assist others in future content-based image retrieval projects in other industries. We encourage anyone building a visual search solution to leverage these techniques, and leverage the code we have shared in our repo , which also contain example on how to operationalize this approach.
It works really well for me
Great news!