
Background
The increasing availability of networked vehicles is creating new transformative opportunities for the automotive industry. With the right tools to safeguard privacy and security of users, the massive amount of data generated by connected cars can be leveraged to create groundbreaking new services such as remote onboard diagnostics, predictive maintenance, and personalized insurance plans.
We recently worked with Otonomo, a connected car startup, to migrate their cloud service from AWS to Azure. This startup provides a data exchange platform, which enables manufacturers, service providers, and application developers, to connect and exchange real-time automotive data. In order to provide real-time insight, Otonomo needed a scalable event processing architecture, capable of processing 10 million+ incoming messages per second from all the vehicles on their platform.
Otonomo required that any event processing solution support Python so that it could be directly integrated into their application and data science workflow. Before the migration, the company used AWS Kinesis for their data ingestion service. However, the Kinesis Python SDK does not provide a native Python implementation; instead, it provides a set of bindings to a custom Java client. While such a solution enables scalable event processing in Python, developers pay an obfuscation price, since bindings at the Java layer are black boxed and cannot be debugged from Python. This code story outlines how we developed a solution for Otonomo to ingest Azure Event Hubs events at scale using Python and Kubernetes.
The Challenge
Azure Event Hubs
Azure Event Hubs is a highly scalable data streaming platform and event ingestion service, capable of receiving and processing millions of events per second. Event Hubs provides message streaming through a partitioned consumer pattern in which each consumer only reads a specific subset, a partition, of the message stream. This partition is an ordered sequence of events that is held in an event hub. As newer events arrive, they are added to the end of this sequence.

Azure Event Hubs has two primary models for event consumption: a direct receiver and a higher-level abstraction called the EventProcessorHost.
Direct receivers are responsible for their own coordination of access to partitions within a consumer group. A consumer group is a view (state, position, or offset) into a partitioned Event Hub.
The Event Processor Host (EPH) pattern provides a thread-safe, multi-process, safe runtime environment for event processor implementations that also provides checkpointing and partition lease management to enable distributed scaling.

EPH Architecture provides scaling across multiple hosts using an event processor pattern, checkpointing and partition leasing.
The EPH Architecture enables developers to process millions of messages at scale. However, while the EPH architecture is fully supported in Java and C#, Otonomo was blocked by the lack of a Python implementation. Prior to this engagement the Python API only supported a direct receiver implementation, which did not fit Otonomo’s needs.
Solution
We worked with the Azure Event Hub team to implement the event processor host architecture in Python and integrate it into the official Python API. The code for the Event Processor Host is available on GitHub. In order to integrate the code into your solution, you must first populate an Event Hub on Azure. You can also use the loader tool we built that will create a test Event Hub.
When using the default Azure Storage manager, you should provision an Azure Storage account for managing the partition lease and checkpoint state. If you wish to use a custom solution for managing checkpoint and lease states, they can implement the following two abstract classes: Abstract Checkpoint Manager and Abstract Lease Manager. Our default implementation can be used as a reference for implementing a custom storage manager.
Once the prerequisite resources are provisioned, you will need to implement the abstract event processor class with your event processing logic. Then, pass the class definition to the event processor host object, along with your Azure Storage manager and Event Hub configurations and start the given host. A sample implementation of this flow can be found in the examples folder of the GitHub repo.
Scaling the solution to millions of messages per a second
During the implementation of the Python event processor host API, way we faced a handful of language-specific challenges surrounding the global interpreter lock and had to come up with creative solutions.
Challenge #1: Python AMQP 1.0 Client
There are two protocols that can interface with Azure Event Hubs (REST/HTTP & AMQP 1.0). While HTTP is easier to interface with, AMQP 1.0 is preferred for processing messages at scale. AMQP 1.0 provides an open socket connection with a listener that is optimized for receiving short messages while HTTP requires significant overhead for each message request from Event Hubs. Both C# and Javasí direct receivers wrap a native implementation of an AMQP 1.0 client which enables the retrieval of tens of thousands of messages per a second from the Event Hub Service. Unfortunately, there is no native Python AMQP 1.0 client, and instead, the Python implementation of eventhub direct receiver relies on SWIG bindings for the Apache Proton Project.
While Proton enables the direct receiver to process more messages per a second then it would if it relied on an HTTP implementation, the communication cost between the Proton and Python layer limits the client to a max processing speed of 2,000 messages per second, as opposed to the tens of thousands of messages per second that can be processed in C# and Java. While this does not block the ability to scale to processing millions of events with Python, it does mean that Python requires more resources to process the same number of events as the C# or Java implementations. We hope that as the Apache Proton Project matures these communication costs will be minimized and this gap will be bridged.
Challenge #2: Concurrency with Python’s Global Interpreter Lock
Unlike C# and Java, Python employs a Global Interpreter Lock (GIL) that prevents multiple threads from executing bytecodes at once. The GIL is necessary because CPython’s memory management is not thread-safe. For more information on Python concurrency, see Python Multithreading Tutorial: Concurrency and Parallelism.
The traditional way to work around this limitation is with multiprocessing, which enables the spawning of processes using a similar interface to spawning threads. Communication between processes and their parents is handled using a thread/process-safe multi-process queue. The reason multiprocessing is not used to manage partition receivers in the EPH is that objects passed to a multiprocess queue must be process-safe and Protonís event objects, generated by the direct receiver, are not. As a result, using multiprocessing with EPH would require events to be serialized at the client layer before being passed to the event processor, resulting in a large communication cost that cancels out any performance gains.
Due to the limitations of Python’s GIL the number of messages processed by concurrently executed partition receivers will never exceed the amount of any individual direct receiver. To scale up, a mechanism, such as a container orchestration service is needed. A container orchestration service is used to ensure that at peak loads one instance of the EPH client will exist for every available event hub partition.
You might wonder why, if you need container orchestration, would you even bother using the EPH pattern over a distributed list of partition receivers? The answer lies in the fact that the checkpointing and leasing capabilities of the EPH architecture enable it to elastically scale down resources during non-peak messaging periods which results in significant resource savings.
Example: How to use EPH in Python
import logging
import asyncio
import sys
from eventprocessorhost.abstract_event_processor import AbstractEventProcessor
from eventprocessorhost.azure_storage_checkpoint_manager import AzureStorageCheckpointLeaseManager
from eventprocessorhost.eh_config import EventHubConfig
from eventprocessorhost.eph import EventProcessorHost
class EventProcessor(AbstractEventProcessor):
"""
Example Implmentation of AbstractEventProcessor
"""
def __init__(self, params=None):
"""
Init Event processor
"""
self._msg_counter = 0
async def open_async(self, context):
"""
Called by processor host to initialize the event processor.
"""
logging.info("Connection established %s", context.partition_id)
async def close_async(self, context, reason):
"""
Called by processor host to indicate that the event processor is being stopped.
(Params) Context:Information about the partition
"""
logging.info("Connection closed (reason %s, id %s, offset %s, sq_number %s)", reason,
context.partition_id, context.offset, context.sequence_number)
async def process_events_async(self, context, messages):
"""
Called by the processor host when a batch of events has arrived.
This is where the real work of the event processor is done.
(Params) Context: Information about the partition, Messages: The events to be processed.
"""
logging.info("Events processed %s %s", context.partition_id, messages)
await context.checkpoint_async()
async def process_error_async(self, context, error):
"""
Called when the underlying client experiences an error while receiving.
EventProcessorHost will take care of recovering from the error and
continuing to pump messages,so no action is required from
(Params) Context: Information about the partition, Error: The error that occured.
"""
logging.error("Event Processor Error %s ", repr(error))
try:
# Storage Account Credentials
STORAGE_ACCOUNT_NAME = ""
STORAGE_KEY = ""
LEASE_CONTAINER_NAME = "leases"
# Eventhub config and storage manager
EH_CONFIG = EventHubConfig('', '','',
'', consumer_group="$default")
STORAGE_MANAGER = AzureStorageCheckpointLeaseManager(STORAGE_ACCOUNT_NAME, STORAGE_KEY,
LEASE_CONTAINER_NAME)
#Event loop and host
LOOP = asyncio.get_event_loop()
HOST = EventProcessorHost(EventProcessor, EH_CONFIG, STORAGE_MANAGER,
ep_params=["param1","param2"], loop=LOOP)
LOOP.run_until_complete(HOST.open_async())
LOOP.run_until_complete(HOST.close_async())
finally:
LOOP.stop()
Solution Scaling Hosts with Container Orchestration and Kubernetes
Kubernetes enables easy scaling of EPH containers across different nodes, maximizing the performance of each container. To scale the EPH, deploy each container in a Kubernetes pod and limit the CPU resources to ensure each container is guaranteed to have as much CPU as it requests but is not allowed to use more CPU than its limit. The following testing and performance section contains the GitHub repository with the deployment YAML files used for this project.
Testing and performance verification at scale
After the basics of the Python implementation were working, we wanted to create a relatively automated pipeline to test the solution for issues and performance. We used the load test tool to create event hubs and generate messages with different kinds of payloads. To verify the runtime performance, we used telemetry data sent to Application Insights, which resulted in graphs like the example below.
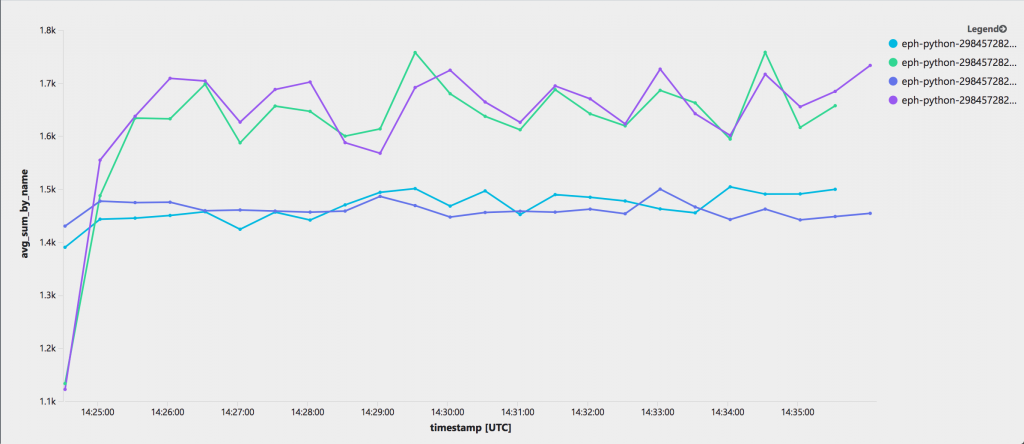
In our initial telemetry pipeline, we sent information about all processed messages to Application Insights. The issue with that approach was that, due to the high scale, we ended up sending too much telemetry which also affected the performance. To improve, we started calculating the “messages per second” value in the client-side and only flushed that to Application Insights. You can find the implementation, instructions on how to run the tests and related Application Insights queries from this GitHub repository.
In our load test, we selected to checkpoint every 10 seconds. This was seen as a reasonable trade-off between performance and potentially receiving duplicate messages. The way duplication relates to the checkpoint interval is that if a receiver crashes (or something else unexpected happens during that 10 seconds), messages received during that 10 seconds might potentially be delivered to another receiver. This duplication is not seen as a problem, because in high scale ingestion via Event Hubs you must anyways be prepared for potentially receiving duplicate messages (the message ID can be used to recognize duplicates in the downstream services).
We also compared the new Python implementation with the existing .NET and Java implementations. You can read more about that work in this blog post. With this performance verification pipeline, we were able to verify that the Python implementation can handle the 2 MB/s throughput from a single partition, which Event Hubs promises per Throughput Unit, in a Standard_D2_v2 VM, allocating 0.9 vCPU per receiver.
As mentioned in the performance verification section above, we were able to reach over 2 MB/s per partition. However, when comparing with implementation in other languages, we did identify that Python performance decreases when a single receiver needs to handle multiple partitions.
This can be seen from the table below. The table header is in format “number of partitions / number of receivers / payload size” and the Throughput Units were 100 in all tests (more info in this blog post).
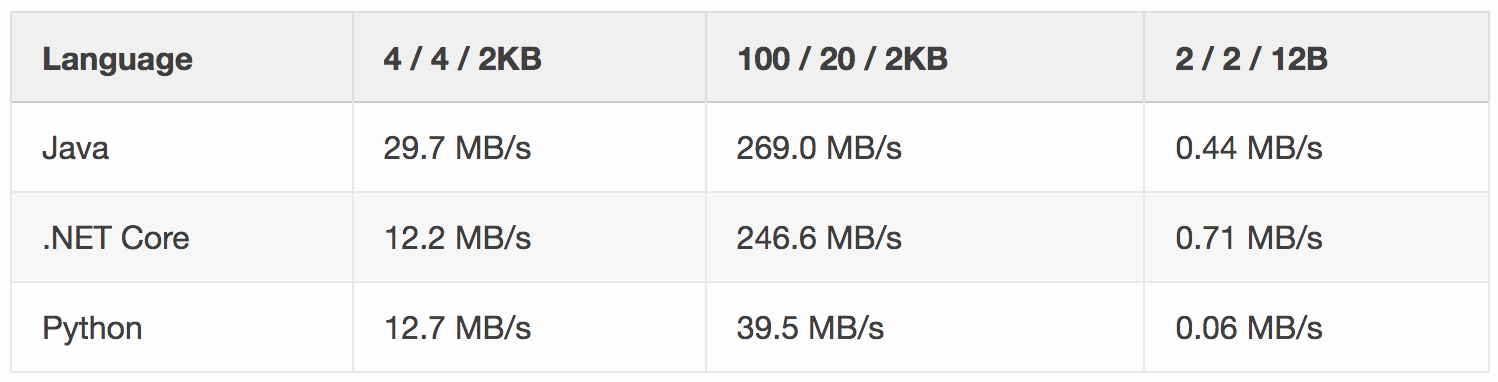
Future optimizations could be considered for the Python implementation to achieve performance parity in all the scenarios.
One thing to consider also is compressing the payload. For example, the 2.0KB payload that was used in performance testing would be roughly 1/4 of the size when gzipped. Using that ratio, you could get 4 times the data ingested by a single Throughput Unit. The price to pay would be additional CPU usage on the receivers that would have to decompress because Event Hubs do not have native decompression.
Conclusion and Reuse
The assets in the solution are available for anyone with a use case that would benefit from using the event processor host architecture with Python, such as real-time data transformation, stream classification, or anomaly detection. Additionally, we provide assets for load testing and benchmarking for Azure Event Hubs with Kubernetes.
- azure-event-hubs-python project repo
- Ubuntu container with Python and Proton
- Azure Container Service (AKS)
- Tool for generating load to Azure Event Hubs
- Benchmarking Azure Event Hub EPH with Application Insight
If you have any comments or questions, please reach out in the comments below.
Cover image: Black Suv Beside Grey Auv Crossing the Pedestrian Line during Daytime