
For various reasons, many customers want the ability to easily and efficiently move data from Amazon Web Services’ Simple Storage Service (S3) to Microsoft Azure storage. In this Case Study, you’ll see how to take the simple notion of cloud file-copy and make it fast and efficient using parallel techniques.
There are several solutions available today for moving data from AWS to Azure. These include any number of simple applications that copy data one file at a time, usually by moving the file to a client machine and then uploading it to Azure. Other solutions use Amazon Direct Connect and Azure Express Route to make the copy operations much faster as both provide direct data center-to-cloud connectivity bypassing the internet. Still others involve sending a physical drive to Amazon, copying data to it, and then after the drive is returned, sending to Microsoft and uploading the data to Azure.
Each of these solutions has value in certain circumstances. However, in many cases the sheer size a transfer, often in terabytes or larger, makes basic file-by-file copying slow and inefficient. By utilizing the inherent scale and parallelism in Azure, an innovative approach can dramatically reduce the overall elapsed time of a large copy operation.
Overview of the Solution
The solution, called “awcopy,” consists of several components:
- A (scriptable) command line application which sends user credentials for both Amazon and Azure storage and a set of commands to the Azure cloud service;
- A command dispatcher in Azure which receives the commands and dispatches work items to “agents”;
- Worker agents that are responsible for copying a (configurable) number of files (a command line setting);
- A user interface that shows the progress of each copy job. Multiple copy jobs from multiple users may be running simultaneously.
Conceptually, the pieces fit together as follows:
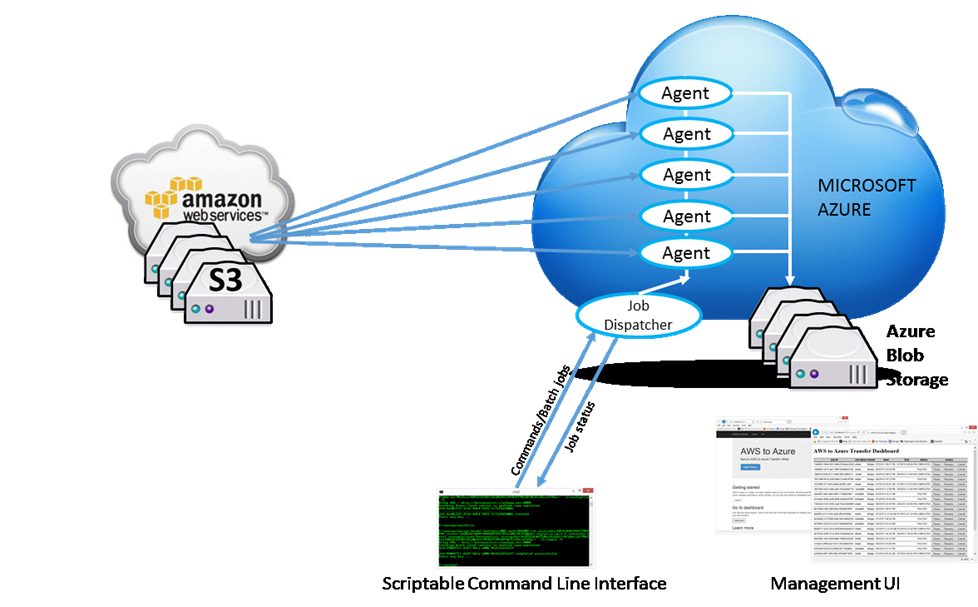
Figure 1. Block diagram of AWcopy
The number of agents is configurable on a per-job basis.
Implementation
The awcopy console application is invoked in the following manner:
C:awcopy>awcopy {aws-parameters} {azure-parameters} {options}
The aws-parameters include:
bucket:{aws-bucket-specification}
path:{aws-object-path} (can be single file, *.*, or regular expression)
accesskey:{aws-S3-access-key}
secret:{aws-S3-secret-key}
region:{aws-region}
Azure parameters include:
container:{azure-container-specification}
storageaccount:{azure-storage-account}
storagekey:{azure-storage-key}
Options (command-line switches) include:
/H: list all commands and explanations
/C: use cloud service to bulk copy files
/U: local (workstation) copy – only useful for debugging/testing credentials
/B: specify block size (default:4MB) format nnnnk or nnnnM
/E: encrypt blobs in Azure
/J: job name
/D: delete files in AWS after copy (confirmation required)
/S: recursively copy
/P: prompt to overwrite existing Azure blobs
/A: (maximum) number of agents in Azure to handle copy (default: 4)
/L: list contents of AWS path and estimate egress charges
/Z: log all activity to local journal file format: awcopy—data-time.log
It is possible to bypass the cloud service to copy files locally (meaning, the files are copied from S3 to the user workstation and then up to Azure) using the /U switch. While inefficient, this is helpful to ensure that credentials are typed in correctly and for other debugging purposes.
Additionally the /L switch will recursively list the contents of an AWS S3 bucket. This command will also estimate egress charges for moving the data out of S3. Here is a screen shot (credentials have been blacked out):
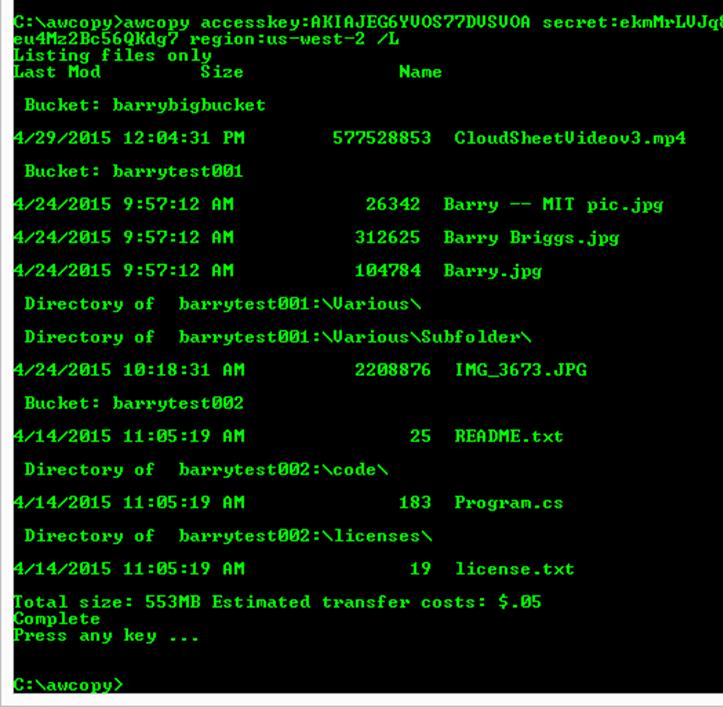
Figure 2. Listing AWS S3 files with estimated egress charges
The Azure cloud service is architected as a simple WebAPI application (web role) and a scaled-out worker role implementing the Orleans actor model. Commands are marshalled and sent to the WebAPI where they are passed on to the Dispatcher actor, a singleton. The Dispatcher then calculates the number of files and divides them among a configurable number of AWSCopy actors, or agents.
Each such job is assigned a GUID. The username (Environment.Username) and an optional job name, a simple string and current job status are maintained in an Azure Table.
Using the AWS .NET SDK and the Azure Storage SDK, files are copied in increments, as specified by the blocksize; by default, 4MB are copied at a time. There is no practical limitation on file size. The blocksize gets stuffed into the relevant AWS S3 structure as shown:
Amazon.S3.Model.GetObjectRequest amzreq = new Amazon.S3.Model.GetObjectRequest
{
BucketName = s3data.Bucket,
Key = s3data.Path,
ByteRange = new Amazon.S3.Model.ByteRange(0, parms.BlockSize)
};
Because the files can be copied by many separate actors, and because actors can be transparently distributed across many cores and servers, a high degree of parallelism can be achieved. While this does not reduce the egress charges from Amazon, it can dramatically reduce overall elapsed time of a large copy operation. To the extent possible, all calls are asynchronous to improve CPU utilization.
A simple dashboard written using angular.js shows job status:
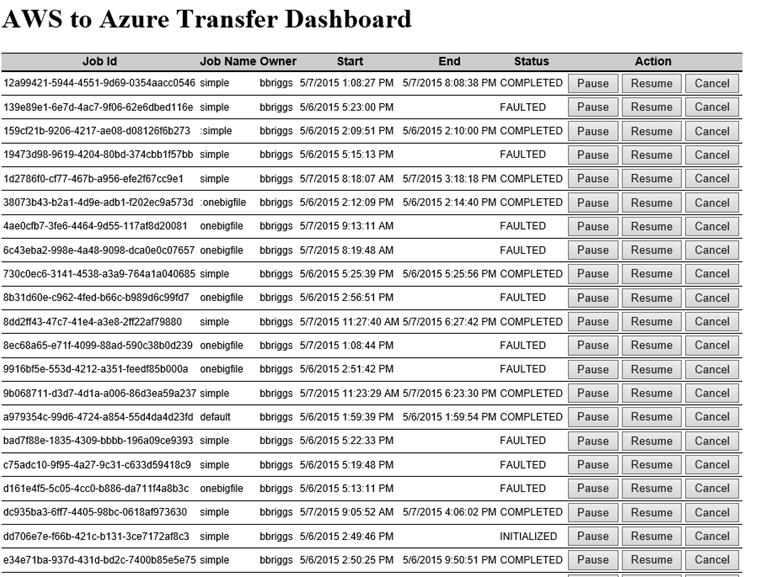
Figure 3. AWcopy Dashboard
(This snapshot was taken while testing fault conditions.)
Challenges
The ongoing challenge in such a project is to make the transfer as fast and efficient as possible. Currently the unit of granularity is the file, meaning files are distributed among agents for transfer. A subsequent iteration of the service if demand warrants would be to split blocks of files among agents for further parallelism.
Opportunities for Reuse
AWcopy can be used essentially out of the box for large-scale copy operations. There are however many other scenarios in which this technology could be applied: for example, inter-cloud backup. A modification would enable files modified since a certain date/time to be moved on a scheduled basis. This is a feature that could be added without significant effort.
In addition, the pattern of awcopy as an application running on the Orleans framework is one that could be replicated for many bulk scale operations.
The Orleans framework can be found here: https://github.com/dotnet/orleans . This repository includes sample applications. The code for awcopy can be found at https://github.com/barrybriggs/AWCopy (note that to build awcopy requires a certain amount of configuration, to use your Azure subscription, storage account and so on).
Notes
“Amazon Web Services”, “AWS”, “Amazon S3”, and “Amazon Simple Storage Service” are registered trademarks of Amazon Web Services, an Amazon.com company.