
This article was co-authored by Zack Rossman, Staff Software Engineer, Veeam; Ashlie Martinez, Staff Software Engineer, Veeam; and James Nguyen, Senior Principal Cloud Solution Architect, AI/ML, Microsoft.
ICYMI: See how Veeam built their AI-powered data discovery solution with Azure Cosmos DB – watch the Ignite session here: How Veeam delivers planet-scale semantic search with Azure Cosmos DB
Most people think of data resilience as two steps: backup and recovery. Backup creates a copy. Recovery brings it back when disaster strikes. But what if you can’t find the file you need to recover when it matters?
At Veeam, we’re committed to delivering reliable and comprehensive data resiliency at planet-scale. That’s why we’ve invested in intuitive, powerful data discovery. It makes sure that contract email, or that missing finance spreadsheet, is right at your fingertips.
Before we reinvented the data discovery workflow in Veeam Data Cloud, everything lived in Azure Blob Storage. Durable, yes. Searchable, not so much. On a small scale, scanning blobs byte by byte was fine. But at enterprise scale with billions of new items added each day across multiple petabytes? That was a no go. Traditional search tools could have helped, but they came with the overhead of running and scaling clusters ourselves. We needed something fully managed and built for global scale. That’s where our partnership with Microsoft came in.
Working with Microsoft, we turned to Azure Cosmos DB as our foundation. Combined with Azure Databricks, Azure Event Hubs, and Azure OpenAI in Foundry Models, we’ve been able to make discovery a core part of Veeam Data Cloud.
In this blog, we’ll walk through:
- Why Azure Cosmos DB: The features that made it the right foundation for discovery
- Schema and partitioning strategy: How we modeled data for scale and performance
- Architecture and ingestion pipeline: The services that feed billions of new items daily
- Querying at scale: How hybrid search delivers relevant results in seconds
- Results at enterprise scale: The impact for our team and our customers
Why Azure Cosmos DB
For discovery to work, we needed a database that could handle billions of new items every day, return results in seconds, and scale seamlessly without burdening our engineering team. Azure Cosmos DB checked those boxes. It’s fully managed, so we don’t spend time running clusters. It’s available across Azure regions, helping us meet strict data residency requirements for our globally distributed customers. And most importantly, it supports vector search. That lets us move beyond keyword lookups and build a data discovery service that better understands the intent of a customer’s query.
When paired with the rest of our Azure stack, Azure Cosmos DB is even more powerful. We use Azure Databricks to process and ingest data at scale, Azure Event Hubs to stream changes in real time, and Azure OpenAI in Foundry Models to generate embeddings that make semantic search possible. Together, these services form the foundation for best-in-class data discovery in Veeam Data Cloud.
Schema and partitioning strategy: Organizing for scale
Once Azure Cosmos DB was in place, the next challenge was designing a schema that could keep up with billions of items ingested and queried each day. With a 20GB limit per logical partition, we needed a structure that spread data evenly and avoided hot spots.
We started with the queries customers run most often—filtering by customer, data type, user, or time range—and designed a hierarchical partitioning scheme that shards data between logical partitions without sacrificing query efficiency.
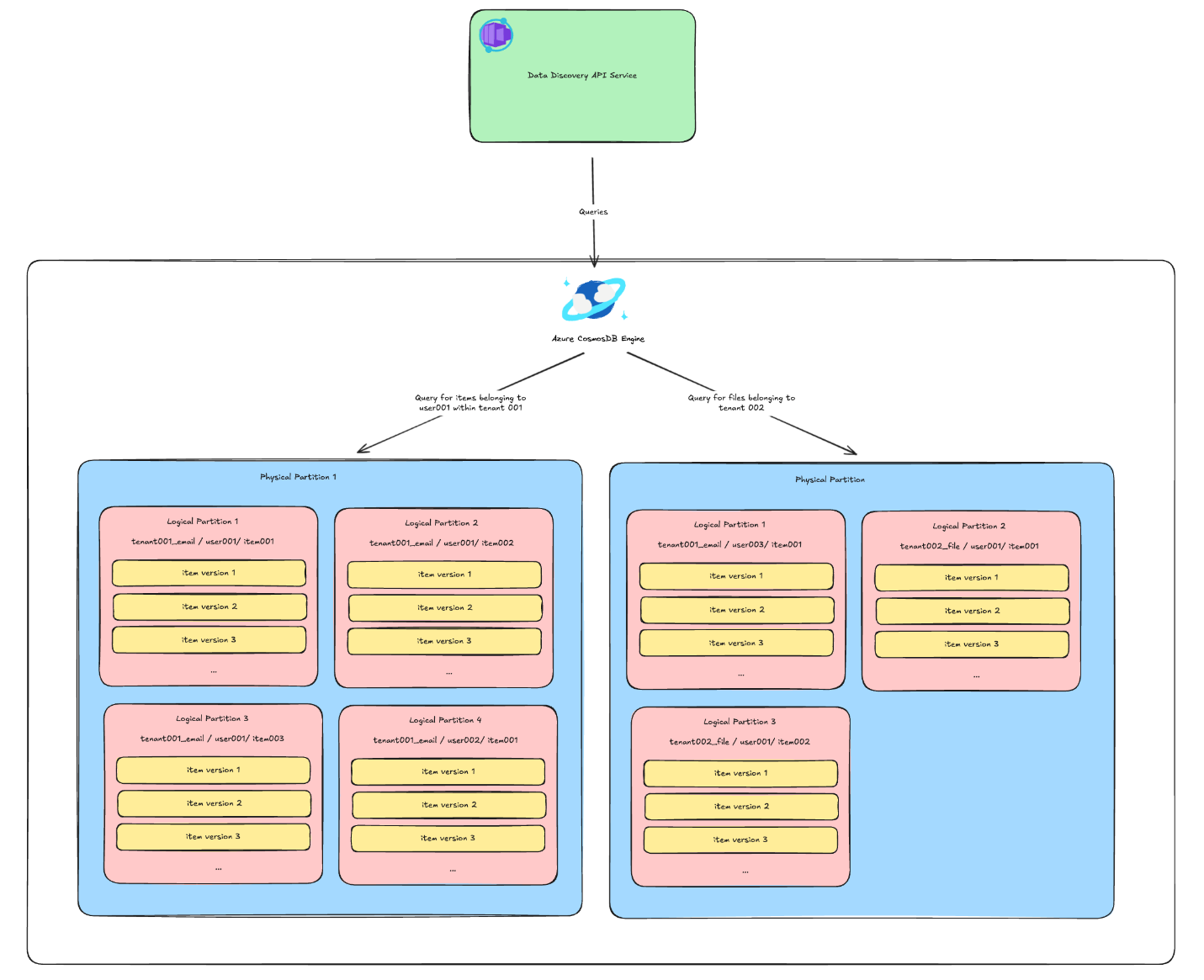
The first partition key is synthetic and combines the customer ID with the type of data (emails, contacts, events, files). The second partition key shards data by the user ID. The third partition key is tied to the item identifier. Altogether, this schema means each Cosmos DB logical partition stores data for all versions of a particular item.
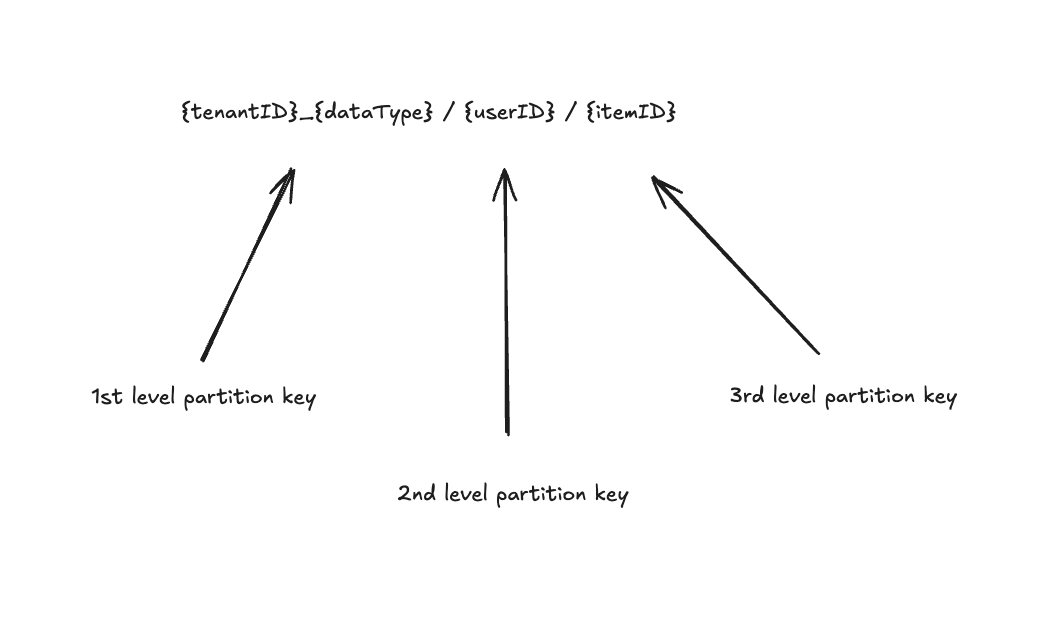
This structure ensures that even in edge cases, we never exceed the 20GB limit for data stored on a single logical partition. By layering keys into a synthetic hierarchical partition key, we unlocked virtually infinite scalability while ensuring low-latency and providing rich query capabilities for Veeam customers.
To ingest data at scale, Veeam relies on Azure Databricks pipelines, backed by Databricks Jobs and Delta Lake, to feed billions of new items into Azure Cosmos DB every day.
Architecture and ingestion pipeline: Building the flow
Designing the schema was one part of the challenge. The other was creating a pipeline that could move billions of backup items into Azure Cosmos DB every day—and enrich them so discovery actually works.
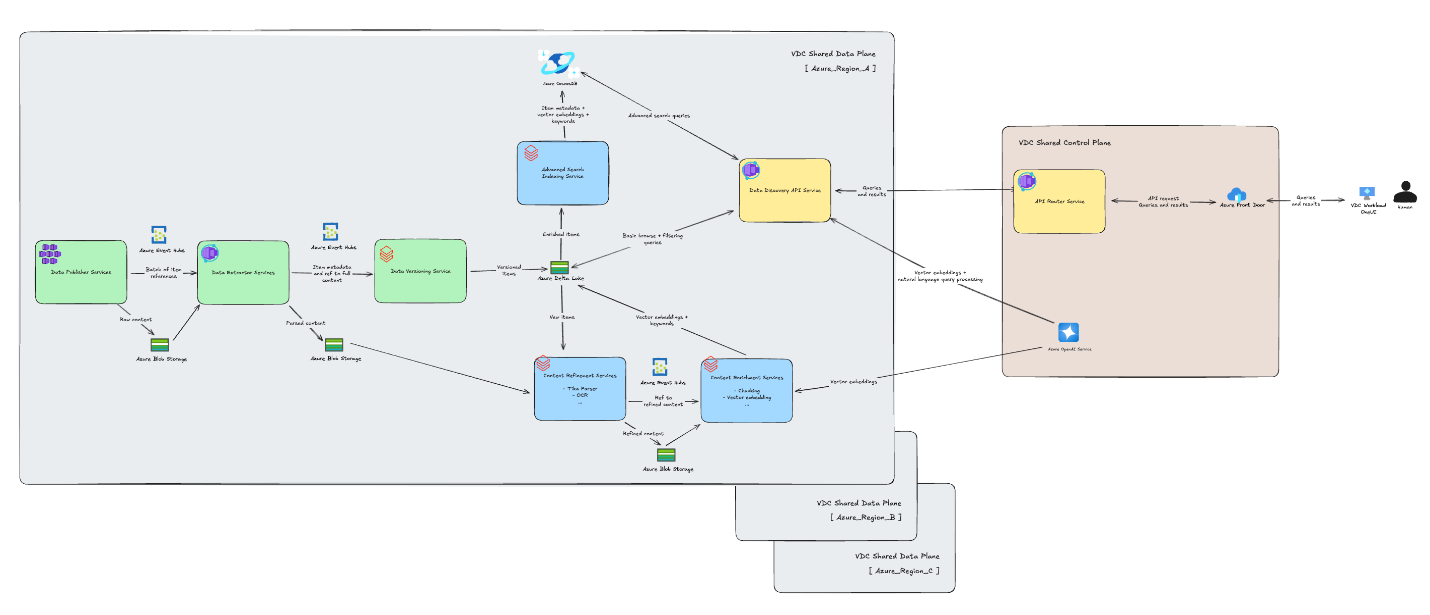 Here’s how the pipeline comes together:
Here’s how the pipeline comes together:
Data ingestion
- Veeam backup engines stream backup data from Microsoft 365, Salesforce, and other workloads into Azure Blob Storage and Azure Event Hubs in real time.
Real-time microservices (Azure Container Apps)
- Extractor services normalize data into consistent formats.
Bulk processing and enrichment (Azure Databricks)
- Enrichment jobs transform data in bulk, calling Azure OpenAI in Foundry Models to generate embeddings (text-embedding-3-small) and vectorize content.
- Indexing jobs merge vectors and metadata at scale into Azure Cosmos DB through Spark connector.
- Databricks jobs allow our services to process request batches in parallel and horizontally scale the underlying compute and storage resource. This dynamic, high-throughput architecture allows us to keep up with petabyte-scale indexing.
- Versioning services track item lifespans so queries can reflect data at any point in time.
- Refinement services strip out noise, like HTML wrappers, to isolate clean text.
Querying at scale: Making discovery fast and relevant
Azure Cosmos DB gives us hybrid search: the ability to combine precise metadata filters with semantic queries in a single request, and to do so consistently across every region our customers operate in. For example, a customer can filter by user ID and time range, then search for “the email about database schema design.” Azure Cosmos DB resolves the query using a combination of deterministic lookups and vector similarity; it then applies Reciprocal Rank Fusion (RRF) to merge and re-rank results from both vector search and full-text keyword search—surfacing the most relevant matches at the top. Thanks to Azure Cosmos DB’s request unit (RU) model and autoscale settings, those queries return in seconds—even at billion-documents scale—without over-provisioning or throttling during spikes.
Because queries are powered by embeddings from Azure OpenAI in Foundry Models, customers aren’t limited to keywords. They can use natural language to search for relevant data, even in multilingual scenarios. For example, a query in Spanish can surface emails with body content in English. This multilingual search capability is especially valuable for Veeam’s largest customers whose employee bases spans multiple geographies.
Discovery at enterprise scale
The difference has been dramatic. Queries that once took 30 minutes (or failed outright) now return in seconds. That’s a 100x to 1000x improvement, turning search into a feature customers rely on every day. Scale tells the same story. Our Microsoft 365 backup product ingests massive volumes of data daily and, thanks to Azure Cosmos DB’s partitioning and autoscale capabilities, customers can now search across tens of billions of documents efficiently.
The impact extends to operations. By offloading cluster management to Azure Cosmos DB, we don’t need a dedicated search infrastructure team. We’re able to deliver state-of-the-art data discovery at planet-scale with a lean engineering team. For customers, semantic search has become a hero feature—fast, relevant, and resilient. It completes the story of backup and recovery by making discovery an integral part of the Veeam Data Cloud experience.
Join us at Ignite to hear more about Veeam’s search solution: “How Veeam delivers planet-scale semantic search with Azure Cosmos DB” Thursday, Nov. 20, 1 PM PST.
About the authors
Zack Rossman is a tech lead for the Veeam Data Cloud AI & Security team.
Ashlie Martinez is a tech lead at Veeam and the former lead designer and implementer of the open-source Corso backup project.
James Nguyen is a Microsoft Principal Cloud Solution Architect who helps organizations innovate through AI/ML, Generative AI, and advanced analytics at scale.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless NoSQL and vector database for modern app development, including AI applications. With its SLA-backed speed and availability as well as instant dynamic scalability, it is ideal for real-time NoSQL and MongoDB applications that require high performance and distributed computing over massive volumes of NoSQL and vector data.
Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on X, YouTube, and LinkedIn.
0 comments