


In this blog, we’ll discuss how Azure Cosmos DB is engineered for resilience and how it ensures high availability when failures happen in the cloud.
Why does it matter ? The only thing that’s constant in distributed systems is failures. No cloud platform is immune to failures — from regional outages and transient network blips to human errors or hardware faults. What defines resiliency & high availability isn’t the absence of failure, but how systems anticipate, isolate, and recover from them.
For many internet applications and services, the database is the first layer (looking bottoms-up) that needs to be highly available, durable, whatever happens under the sun. Machines fail, data centers get overheated, fuel supply goes low, a snowstorm strikes, a fiber cable gets cut, or someone pulls the wrong plug during maintenance, you name it. Despite any of this, distributed databases in the cloud need to be up, so all the online experiences built on top can continue to keep the world spinning.
At Azure Cosmos DB, we never stop thinking about this. We think about resiliency across
- Control Plane (aka. Management Plane)
- Data Plane (Stateful Database Partitions, Gateways, Client SDK/drivers)
- Partial & Full Regional failures – Within-region and cross-region resiliency
- Infrastructure failures, Software Failures, Replicated State Machine Failures, Resource Governance failures
Let’s dive deep into each layer of the stack to see how its made resilient.
Control Plane Resiliency
The Azure Cosmos DB Control Plane is used (only) for management operations, which may include creating a new database account, adding or deleting a secondary region, updating security settings, doing an account level failover, etc. Basically, all account level management operations. Control Plane is not in the hot path of data traffic.
The Control Plane is regionalized to make sure that the blast radius of a Control Plane failure is contained and doesn’t have a global impact. Control Plane has its own Regional Compute to run these management operations as well as a backing Regional Database to hold its own state and service metadata.
Control Plane Compute – All Database Accounts are modeled as a Global Database Account. Each such Global Database Account is assigned to a Regional Control Plane, designated as its Home Location. Compute part of this Regional Control Plane is responsible for executing all Control Plane operations on those Global Database Accounts. In the event of an outage affecting this Regional Control Plane, the Compute will fail over to another healthy region, restoring Control Plane availability. The new region will now assume ownership of all Global Database Accounts that were homed in the outage region earlier.
Control Plane Database – Each Regional Control Plane stores its own execution state along with the service metadata of all Global Database Accounts for which it is designated as the Home Location. It stores all of this in its own dedicated Cosmos DB database. These System Cosmos DB databases are not shared across Regional Control Planes, ensuring that each Control Plane System Database remains fully regional. To provide resilience against regional outages, each Control Plane System Database is replicated to two additional secondary regions with Strong Consistency.
Data Plane Resiliency
Gateways & DNS Endpoint Resiliency
In Azure Cosmos DB, DNS endpoints used by customer applications are Database Account level endpoints and not a region-level shared DNS endpoint that refers to Azure Cosmos DB service as a whole. This helps curtail the blast radius of a single DNS record entry.
Azure Cosmos DB provides 2 modes of connectivity for applications. Direct Mode and Gateway Mode.
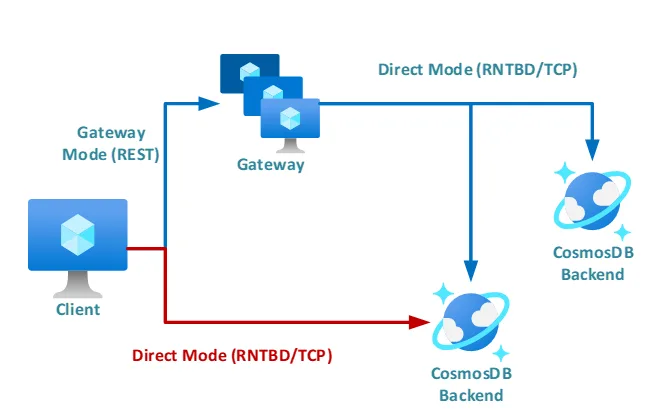
In Direct Mode, the data / document traffic skips the gateway and directly routes it to our Backend database partitions. This has a benefit in that it skips a hop and hence improves latency. Even in Direct mode, a small sub-system, called the Routing Service, is utilized to help the client discover the database replica endpoints as of that time. This Routing Service Instance is also scoped, account specific and not region level or global level shared instance.
Note that the database partitions and its replicas can move around for several reasons and this Routing Service is responsible for sharing the new location to the client application. All of this is transparently handled in our client SDKs with a special client-server handshake, with no impact to applications. Any data replica moves or any machine failures in the fleet do not need any DNS record updates.
After the Global Database Account level DNS endpoint is created during the initial account setup, its updated only in rare circumstances, like when one triggers an account level failover to switch the write status from one to another region (in active-passive setup). This is done so that the Global Database Account Endpoint now points to the new write region (after the failover). Another rare scenario which could trigger a DNS update is when we move the location of the Database Account’s singleton metadata partition which holds key metadata about the account. Any other machine rotation or cluster capacity addition or removal from the fleet do not trigger updates to Database Account DNS entries.
In Gateway mode, all data / document traffic is routed through the gateway. A region comprises multiple gateway clusters and any one Database Account is placed on a slice/subset of these gateway clusters. These Gateway clusters are largely behind Azure Traffic Manager (ATM) endpoints. In large regions, we have multiple ATM endpoints covering the region and hence it is not a single instance (but multiple) to cover the entire region. This additional layer of indirection (through ATM) helps with load balancing and redundancy across multiple gateway clusters behind. If there are failures in one gateway cluster, other gateway clusters can take the traffic transparently. This also comes in handy for load balancing in steady state. Most gateway clusters also span Availability Zones. Since these gateways are stateless, we are able to quickly switch traffic to other gateway clusters or add more clusters behind an ATM to load balance dynamically.
Database Partitions
Within-Region High Availability
All Azure Cosmos DB database partitions have 3+ replicas in the local region spread across different fault domains, managed by Service Fabric. One can think of this as an instance of Multi-Paxos where one primary replica is selected for a period of time. Failure detection can detect failures at network and hosting server layers. And in many cases, the replicas are also spread across Availability Zones (AZ) within the region, in Azure Regions that support AZs. More and more database partitions are automatically moved to AZ as more such AZ capacity is made available.
Cross-Region High Availability
If there are multiple secondary regions added to the Global Database Account, each partition has a corresponding paired partition in each region the account is present in, forming a partition-set across regions. So each partition-set has 3+ replicas in every region the account is replicated to. So Cosmos DB databases are locally redundant in each region, in addition to cross-region redundancy, achieved through a replicated state machine across regions.
Multi-Region-Write Setup (active-active, all regions are writable)
This mode offers the best write & read availability cross-region, achieving RTO = 0. This is made possible by the fact that all regions are writable and hence there is no need to failover on the database side in the event of a failure or an outage. Client SDK driver is able to automatically detect a failure from a regional endpoint, mark that regional endpoint as unavailable in that client session and move the traffic over to the other healthy regions. It does periodic health checks to see if the prior unhealthy endpoint has recovered before switching back traffic. All of this happens at different levels of granularity to keep the blast radius of a failure as minimal as possible, like a partition level or an account level or region level. In multi-write setup, since all regions take writes in parallel for the same database, possibly for same keys, automatic confliction resolution is triggered to resolve conflicts on concurrent updates to same keys.
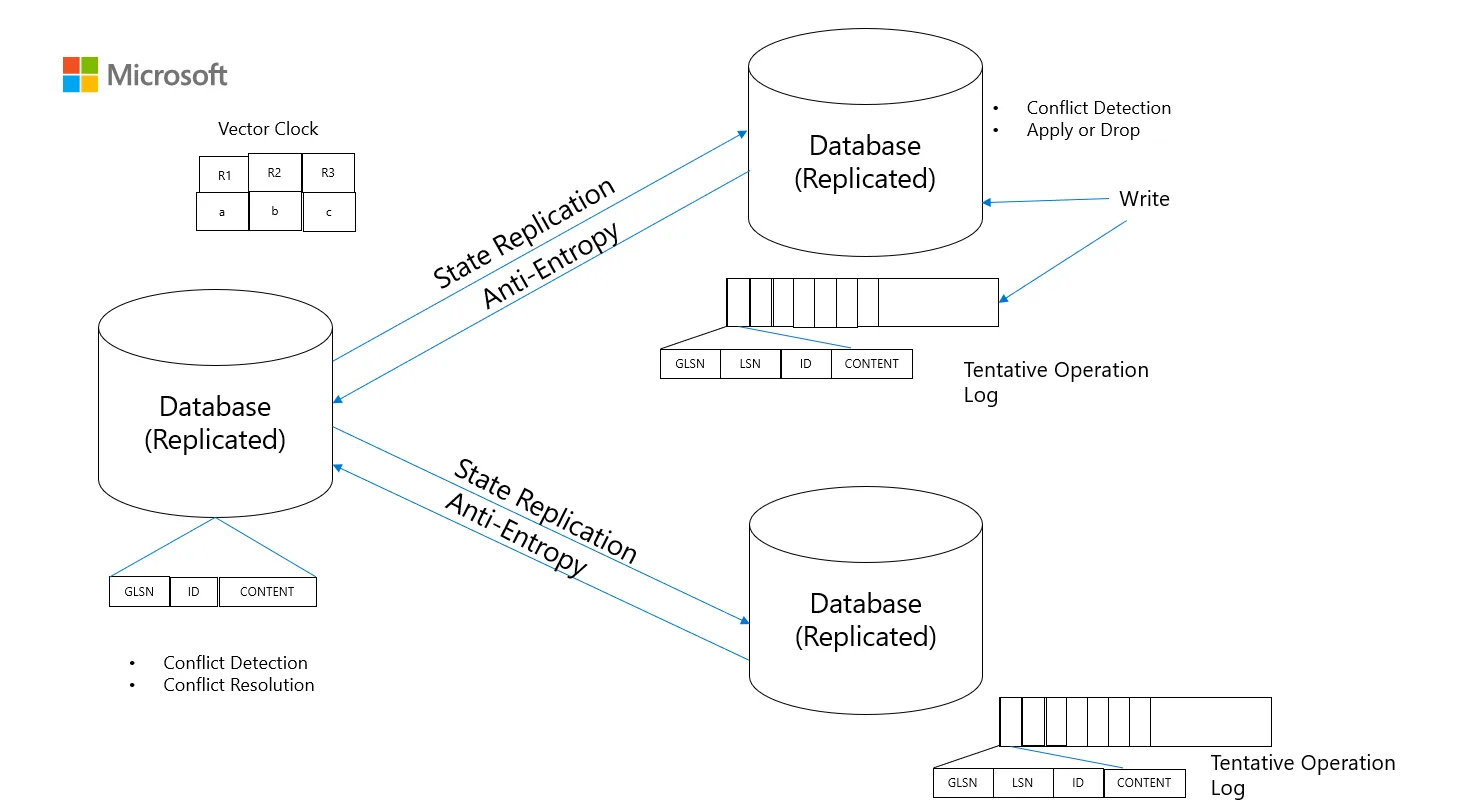
Region Independent Failure Modes
In active-active setup, Azure Cosmos DB ensures that one region’s failure doesn’t cause a correlated or cascading failure on any other region of the Global Database Account. So it has Region-Independent Failure Modes. In Replicated State Machines, like Distributed Databases across regions, Independent Failure Mode needs to be carefully designed for. The updates that come to the active region should be queued in persisted log to replicate to other offline regions once it is available again. So the database and the client SDK work in tandem to increase write & read availability across regions.
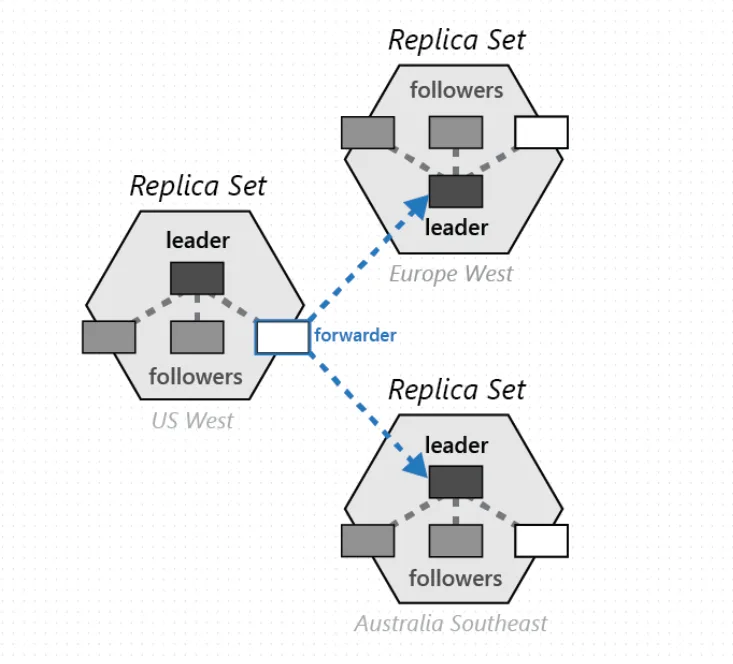
Single-Write-Region, Multiple-Read-Region Setup
This setup implies only one of the regions is writable at any one point in time. Could be used to provide strong consistency or if the application prefers to avoid conflict resolution that’s seen in multi-write setups. We recently introduced Per-Partition (aka Decentralized) Automatic Geo Failover which does automatic failure detection and uses CAS-Paxos to do automatic cross-region leader election to failover to another region and restore availability within the partition-set. This helps to keep the failure detection and failover radius as contained as possible and hence have them execute fast & automatically. Even failback is automatic. The Azure Cosmos DB client SDKs automatically detect that some or all of the database partitions have failed over and redirect requests to the new write region. Such cross-region automatic failover does not depend on our Control Plane. Hence it’s a completely decentralized architecture with Per-Partition Automatic Geo Failover. This decentralization removes the dependency on Control Plane to maintain data plane availability. Failure detection part of the infrastructure is highly extensible to add more scenarios (incl. gray failures). Note that we are not dependent on DNS record updates to do automatic geo failover. The Client SDK is already aware of the cross-region endpoints to try if the primary write region fails. Today, this feature needs customer to opt-in and take the latest client SDK version.
In the below diagram, its an active-passive setup. Region 1 is the Write Region. Region 2 and 3 are readable secondary regions. With Per-Partition Automatic Failover, there is a Distributed Failover Manager that heart beats across all regions of the partition-set, does CAS Paxos to achieve consensus on selecting the next Write Region if a need arises (i.e, on detecting a failure of the current Write Region, Region 1)
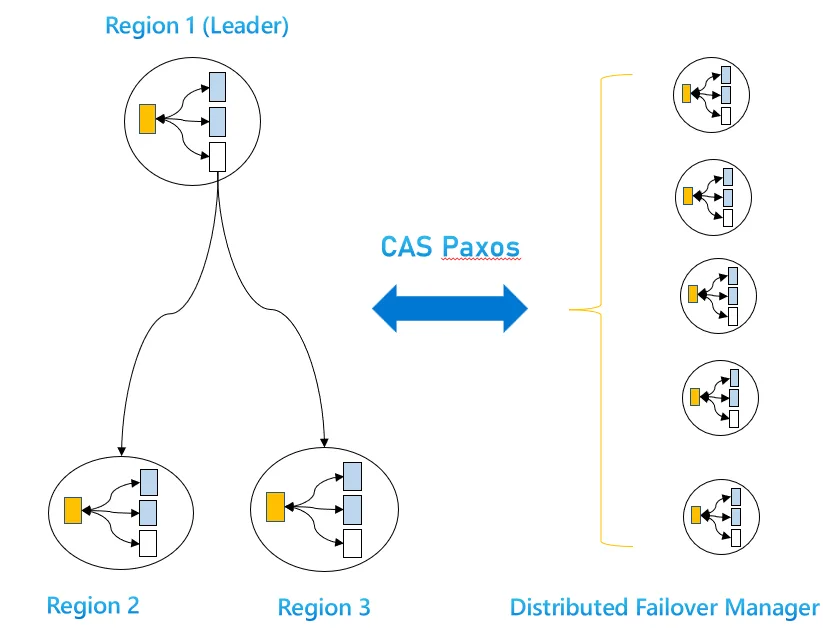
Decentralization is extremely useful for massively distributed databases like Azure Cosmos DB. A single Database Account’s partitions are highly spread out among physical clusters across the region. And most outages are partial in nature, in that it’s usually a part of the region that is impacted. In such cases, the decentralized, per-partition failover will make sure only the affected portion of the database is automatically failed over to the other region and fails back when healthy.
More on the decentralized per-partition automatic geo failover in the following paper
[2505.14900] Implementing Decentralized Per-Partition Automatic Failover in Azure Cosmos DB
TLA+ spec for Per-Partition Automatic Failover (PPAF) work can be found here.
In the absence of customer opt-in to this feature (PPAF), one could do “Offline Region” in the portal to offline a region that has an ongoing outage. This will do the failover to the next region in the Failover Priority List. It does Force Failover at an account level orchestrated by our Regional Control Plane.
Dynamic Quorum-Set
When secondary regions are slow to apply replication traffic or hits a failure, they are actively managed (at partition-set level) in the “slow build queue” so that the laggard targets do not cause degradation to steady state traffic processed by other replica regions. This is done while honoring the consistency levels selected by the user. Note that Azure Cosmos DB has multiple consistency levels that users can choose from to select a trade-off between read consistency and read performance. Dynamic management of active-region-set allows to maintain write availability amidst varying read consistency levels.
Cross-Region Hedging
Azure Cosmos DB’s client SDKs are equipped to do cross-region hedging to reduce the latency in case of transient failures from One Regional Database Endpoint. This essentially kicks off a parallel request to an alternate region after a configurable time, so that client doesn’t wait on the full timeout from the initial region to start the failback process to alternate region. This is highly used by several services to improve availability and hence not having to trade-off between availability and latency in the event of failures.
Client SDKs
Azure Cosmos DB Client SDKs are very aware of the failure modes and takes automatic decisions for restoring availability. This includes retry policies, cross region failover and failback policies, disambiguation of several failure / error codes, those that originate from service, and those that fail before reaching the service endpoint. And we continuously update our SDKs to enhance the end-to-end experience of mission critical applications.
In closing, the above gives an overview of how Azure Cosmos DB is hardened to run world population scale consumer & enterprise internet apps with high resiliency. Azure Cosmos DB powers worldwide ChatGPT, Microsoft Teams, Walmart.com, Microsoft Copilot, all-up Azure’s Control Plane, Azure RBAC, Entra and more. Our mission here is to ensure every layer of the stack anticipates failures and recovers seamlessly. We continue to evolve our architecture with innovations like Per-Partition Automatic Geo Failover, Dynamic Quorum-Set, Active-Active & Region Independent Failure Modes, so customers can trust their database platform to stay online despite failures. We continue to learn from every failure that happens in the cloud and iterate with those learnings.
More user information here: High Availability (Reliability) in Azure Cosmos DB for NoSQL | Microsoft Learn
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless NoSQL and vector database for modern app development, including AI applications. With its SLA-backed speed and availability as well as instant dynamic scalability, it is ideal for real-time NoSQL and MongoDB applications that require high performance and distributed computing over massive volumes of NoSQL and vector data.
To stay in the loop on Azure Cosmos DB updates, follow us on X, YouTube, and LinkedIn.
Outstanding overview of Cosmos DB’s resiliency architecture. The combination of per-partition automatic failover, dynamic quorum management, and cross-region hedging highlights a thoughtful, battle-tested design. Looking forward to learning more about how these mechanisms evolve with future releases.