
Over the years, we’ve heard feedback from many you that you’d like more flexibility in how Azure Cosmos DB handles scaling and partitioning. Based on your feedback, we are excited to announce the general availability of three key features – burst capacity, hierarchical partition keys, and serverless container storage of 1 TB – to help you get the best cost and performance for your applications.
Burst capacity (GA)
Azure Cosmos DB burst capacity, now generally available, allows you to take advantage of your database or container’s idle throughput capacity to handle spikes of traffic. As a result, you can maintain performance for short, temporary bursts, as requests that otherwise would have been rate-limited (429) can now be served by burst capacity when it is available. This gives a temporary cushion for moments where your workload occasionally exceeds the RU/s you’ve provisioned.
With burst capacity, each physical partition can accumulate up to 5 minutes of idle capacity. This capacity can be consumed at a rate up to 3000 RU/s. Burst capacity applies to databases and containers that use manual or autoscale throughput and have less than 3000 RU/s provisioned per physical partition.
Let’s see how autoscale and burst capacity work together to help handle spikes of traffic. With autoscale, we specify the max RU/s we want to scale to. At any moment in time, we’re able to get 10x instantaneous scaling. For example, if we provision a container with a scale range of 100 – 1000 RU/s, we can scale to 1000 RU/s instantly if our workload traffic increases.
However, there are times when we may see a sudden traffic spike that exceeds the 1000 max RU/s we’ve provisioned. In these cases, we can take advantage of burst capacity.
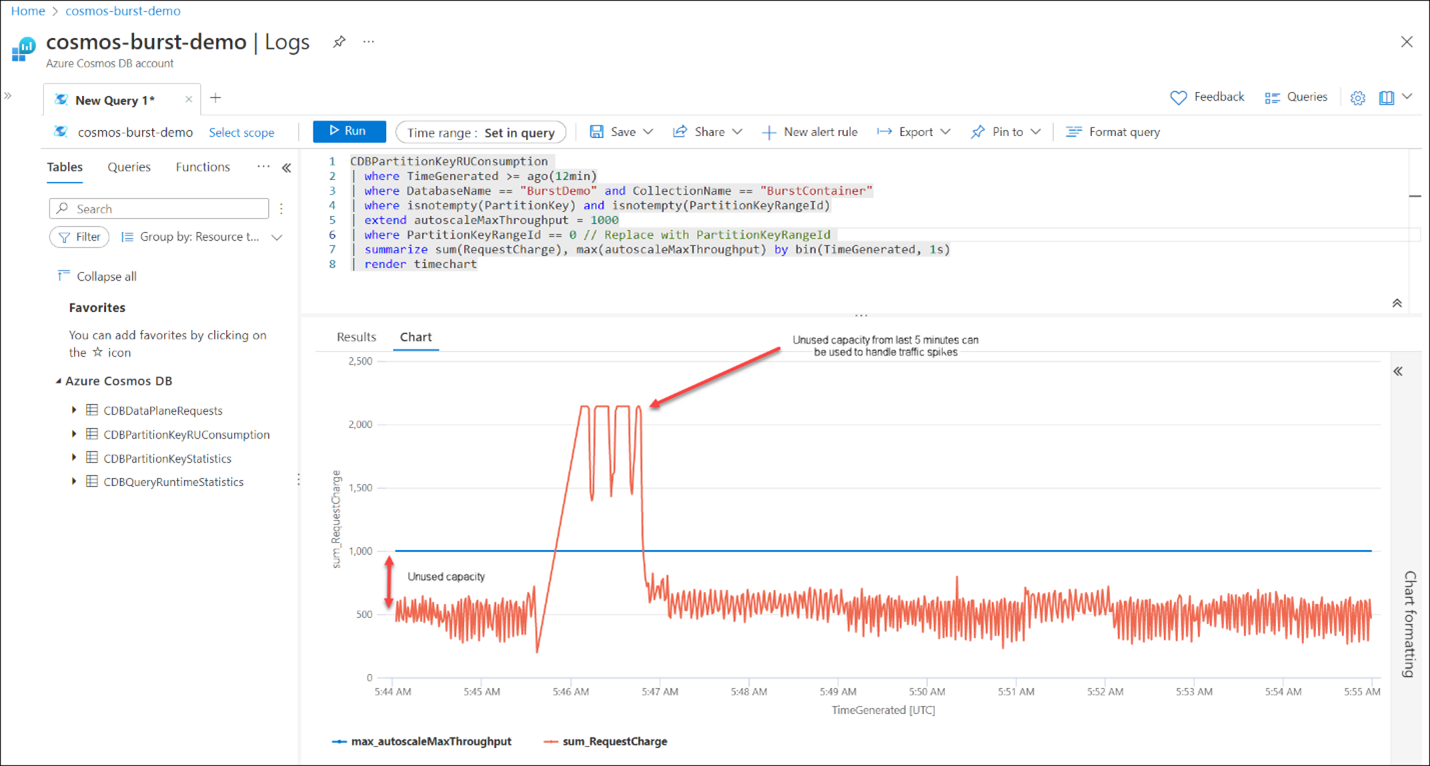
When burst capacity is enabled, for a rolling window of 5 minutes, we accumulate unused capacity each second. During a spike of traffic, when our container has used up all its provisioned RU/s (it has scaled to 1000 RU/s), Azure Cosmos DB will use the burst capacity to serve the additional requests. For example, if our autoscale container (which has 1 physical partition) was idle for 5 minutes before a spike of traffic, we could accumulate up to 300 seconds * 1000 RU/s = 300,000 RUs. Since we can burst at a rate of 3000 RU/s, this means for 100 seconds, we can consume 3000 RUs per second. This is 3x higher than our max autoscale range!
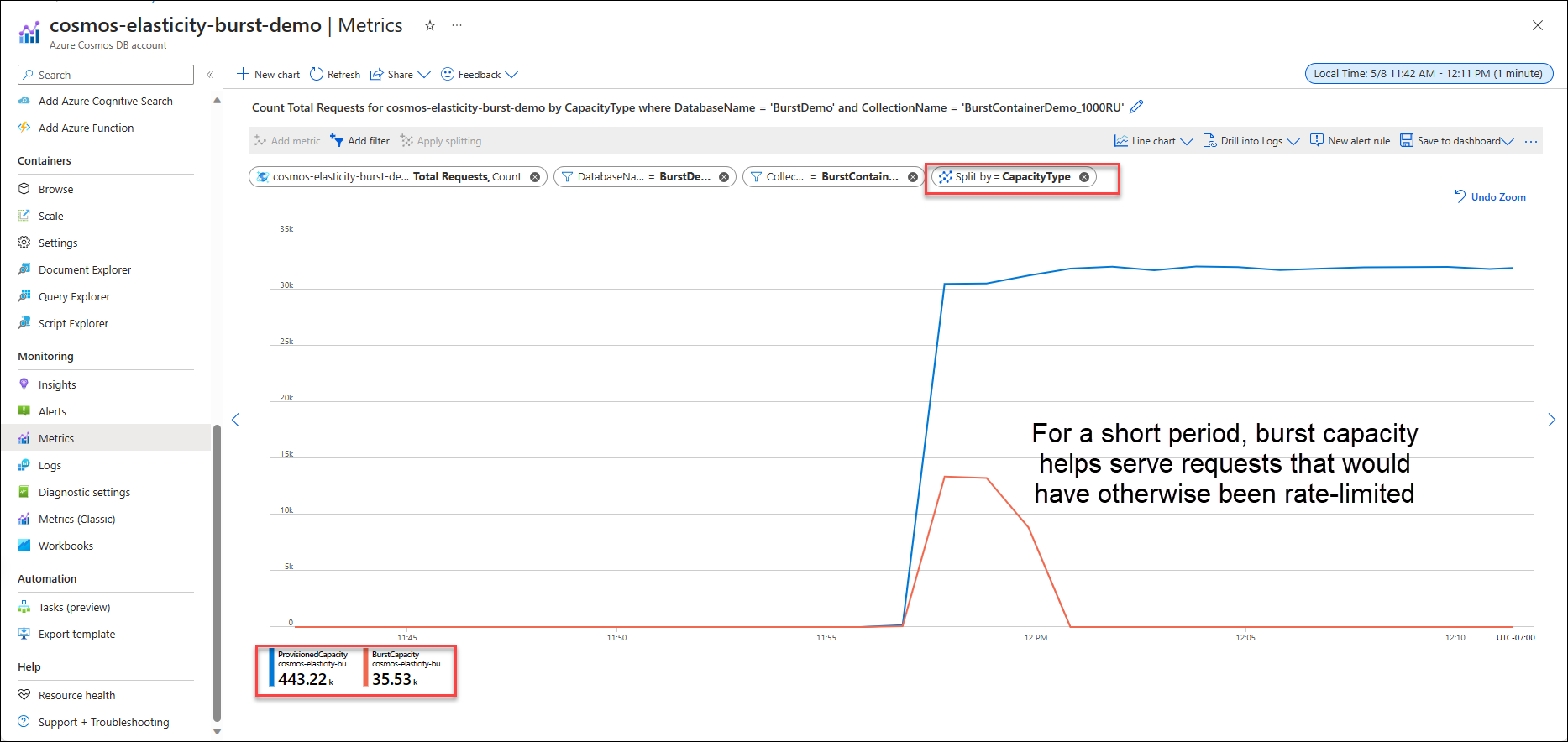
We can also use built-in Azure Monitor metrics to see how many requests (Total Requests) and corresponding request units (Total Request Units) were served by burst capacity. To do this, we use the “split by” feature to split by CapacityType. In the below chart, we see that for a few minutes, we were able to serve more requests through burst capacity (orange line). These are requests that would have otherwise been throttled. After the burst capacity runs out, requests are only served using the provisioned throughput capacity.
Burst capacity is applicable for Azure Cosmos DB for NoSQL, MongoDB, Cassandra, Table, and Gremlin. Usage of burst capacity is subject to system resource availability and is not guaranteed.
Getting started
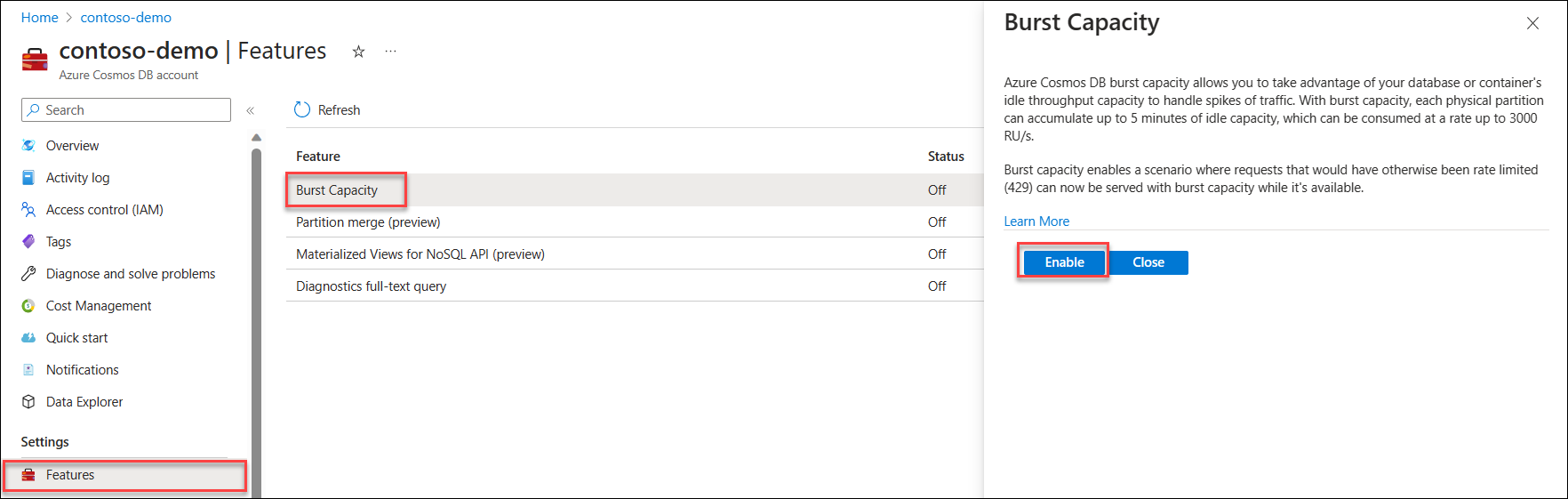
To get started using burst capacity, navigate to the Features page in your Azure Cosmos DB account. Select and enable the Burst Capacity feature. Learn more.
Hierarchical partition keys (GA)
We’re excited to announce that hierarchical partition keys are now generally available for Azure Cosmos DB for NoSQL. With hierarchical partition keys, also known as sub-partitioning, you can natively partition your container with up to three levels of partition keys.
If you currently use synthetic partition keys or have scenarios where your logical partition keys can exceed 20 GB of data (common in multi-tenant applications), hierarchical partition keys can help. Instead of having to choose a single partition key, you can now use up to three keys to further sub-partition your data, enabling more optimal data distribution and higher scale.
Behind the scenes, Azure Cosmos DB will automatically distribute your data among physical partitions such that a logical partition prefix (e.g. TenantId) can exceed the limit of 20GB of storage. In addition, queries that target a prefix of the full partition key path are efficiently routed to the subset of relevant physical partitions.
Hierarchical partition keys must be specified upon container creation, and you must use a version of the Azure Cosmos DB client that supports the feature.
Example scenario
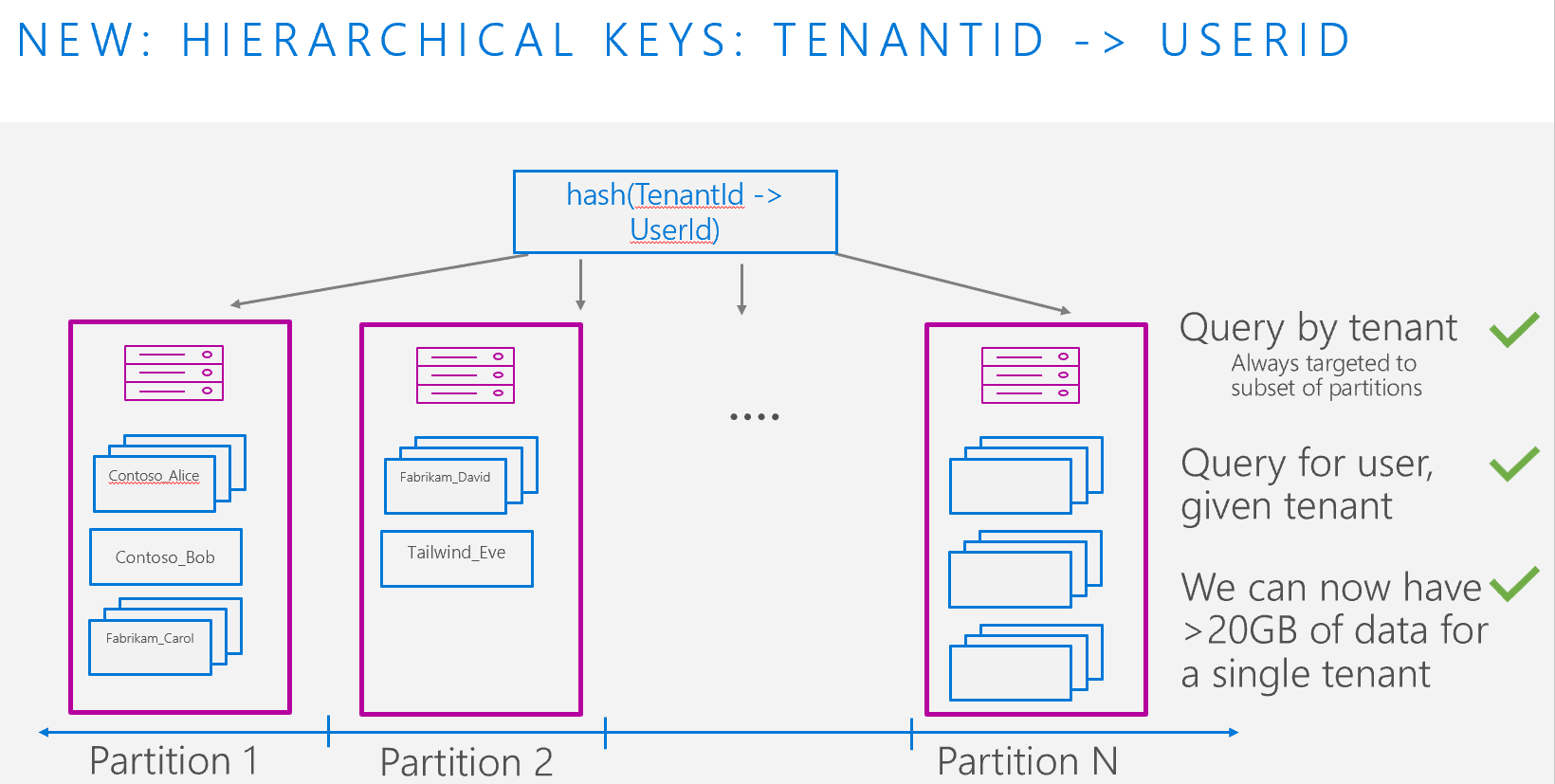
Suppose we have a multi-tenant application that keeps track of user login information, with 1,000 tenants. Each tenant has between 10 – 100,000 users. Some tenants are larger than others, and it is possible for a single tenant to have more than 20 GB of data across all its users.
As part of our data access pattern for this scenario, we have the following operations:
Write operations
- Insert data for each login event
Read operations
- Get all data for a particular tenant
- Get all data for a particular user
- Read a single event for a user in a tenant
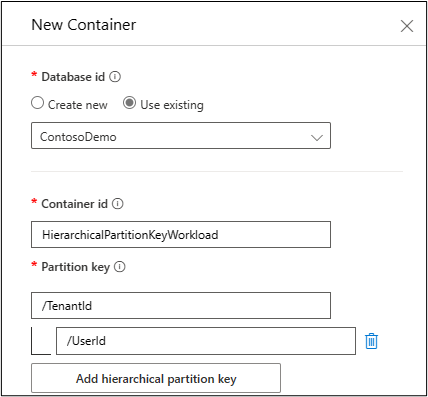
If we partitioned only by TenantId, we’d hit the 20 GB logical partition key limit. To ensure we can scale beyond that, we’ll use hierarchical partition keys, with TenantId as the first level and UserId as the second level. This allows every combination of TenantId and UserId – for example, user Alice in Contoso tenant – to have up to 20 GB of data.
Note, if we believe it’s possible a user in a tenant can exceed 20 GB, we can add a 3rd level key with high cardinality (such as an Id or a property with a GUID), which effectively ensures there is no limit on how much data can be stored for a single user.
Hierarchical partition keys also give us advantages over synthetic keys.
If we used a synthetic key of TenantId_UserId for our above scenario, any query by TenantId on its own would be a full cross-partition fanout query. This can be inefficient and lead to high RU costs for large workloads. With hierarchical partition keys, queries by Tenant are routed to only the targeted subset of physical partitions the data is on, resulting in more efficient queries.
In addition, we don’t need to create any customer properties in our documents; we just need to ensure that the TenantId and UserId exist as properties in every document. This helps reduce application complexity.
The diagram below shows an example partition layout, with purple boxes representing each physical partition, and blue boxes representing the logical partition. We see that the data for TenantId = “Fabrikam” has grown beyond 20 GB and spans Partition 1 and 2. If we ran the query, “SELECT * from c where c.TenantID = “Fabrikam”, Azure Cosmos DB would only need to check Partitions 1 and 2, avoiding the rest. In contrast, with synthetic partition key of TenantId_UserId, because the entire partition key was not specified, Azure Cosmos DB would have to check all partitions, resulting in a less efficient query.
Getting started
To get started, create a new container with hierarchical partition keys in the Azure portal or use the supported SDKs.
- .NET V3 SDK – version 3.33.0 (or a higher version)
- Java V4 SDK – version 4.42.0 (or a higher version)
- JavaScript V3 SDK – version 3.17.4-beta.1 (only available on this preview version)
For more information, visit our documentation on hierarchical partition keys.
Serverless container storage capacity increase to 1 TB (GA)
Azure Cosmos DB serverless lets you use your account in a consumption-based manner, where you only pay for the storage and throughput that you use. We are excited to announce that we’ve expanded the storage capacity of serverless containers to 1 TB, now generally available. Previously, the limit was 50 GB of storage.
To take advantage of the new storage capacity, no action is required – all existing and new serverless containers will be able to store up to 1TB by default. With expanded storage, 1TB containers also offer increased burstability. The maximum throughput for serverless containers starts from 5000 RU/s and can go beyond 20,000 RU/s depending on the number of partitions available in the container. For more information, see Serverless performance.
Serverless is a great solution for applications with intermittent and unpredictable traffic, as you don’t have to worry about provisioning RU/s or capacity management. This enables you to focus on developing your application and optimizing your cost.
Learn more about serverless and how to get started.
Next steps
In summary, we are excited to release these features to help you optimize the cost and performance of your Azure Cosmos DB workloads. Visit the links below to learn more about each feature.
We look forward to hearing your feedback!
Get Started with Azure Cosmos DB for free
Azure Cosmos DB is a fully managed NoSQL and relational database for modern app development with SLA-backed speed and availability, automatic and instant scalability, and support for open source PostgreSQL, MongoDB and Apache Cassandra. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on Twitter, YouTube, and LinkedIn.
What is the difference between brust capacity and execution based on priority that they mention in the following link? do you get the same result?
Hello,
I hope this answers your question:
In Azure Cosmos DB, "burst capacity" and "execution based on priority" are two different concepts that affect the performance and behavior of your database operations, but they have distinct implications and results.
Burst capacity: Burst capacity refers to the ability of Azure Cosmos DB to handle sudden spikes in throughput for a short duration. It allows you to exceed the provisioned throughput (RU/s or Request Units per second) for your container or database to accommodate temporary increases in workload. Burst capacity helps maintain low latency and avoid throttling during unexpected traffic peaks. When you exceed the...