

“Cosmos DB is the go-to database powering the world’s most demanding workloads at any scale.
OpenAI relies on Cosmos DB to dynamically scale their ChatGPT service – one of the fastest-growing consumer apps ever – enabling high reliability and low maintenance.” – Satya Nadella, Microsoft chairman and chief executive officer
As the need for intelligent applications expands, developers are increasingly relying on artificial intelligence (AI) and machine learning (ML) to enrich their application’s capabilities. Amongst the numerous conversational AI delivery methods, chatbots have become highly sought after. OpenAI’s ChatGPT, a robust large language model (LLM), is an excellent solution for creating chatbots that can comprehend natural language and provide intelligent replies. ChatGPT has gained popularity since its launch in November 2022.
In this blog post, myself and a colleague, Sandeep Nair, walk through our experience in learning the Large Language Models that power OpenAI’s ChatGPT service and API by creating a Cosmos DB + ChatGPT sample application that mimics its functionality, albeit to a lesser extent. Our sample combines ChatGPT and Azure Cosmos DB which is used to persist all of the data for this sample application. Throughout this blog post, as we go through the sample we built, we’ll also explore other ways combining a database like Azure Cosmos DB can enhance the experience for users when building intelligent applications. As you’ll come to see, combining Azure Cosmos DB with ChatGPT provided benefits in ways that turned out to be more valuable than we anticipated.
To run this sample application, you need to have access to Azure OpenAI Service. To get access within your Azure Subscription, apply here for Azure OpenAI Service.
Our Sample ChatGPT App
Let’s get to the application. Our application looks to show some of the functionality for the ChatGPT service that people are familiar with. Down the left-hand side are a list of conversations or “chat sessions”. You click on each of these for a different chat session. You can also rename or delete them. Within each chat session are “chat messages”. Each is identified by a “sender” as User or Assistant. The messages are listed in ascending chronological order and displayed using the Humanizer Nuget package. A text box at the bottom is used to type in a new prompt to add to the session. Finally the number of tokens used for requests to the Azure OpenAI service are displayed both for each chat message and the entire session. We’ll talk more about tokens later.
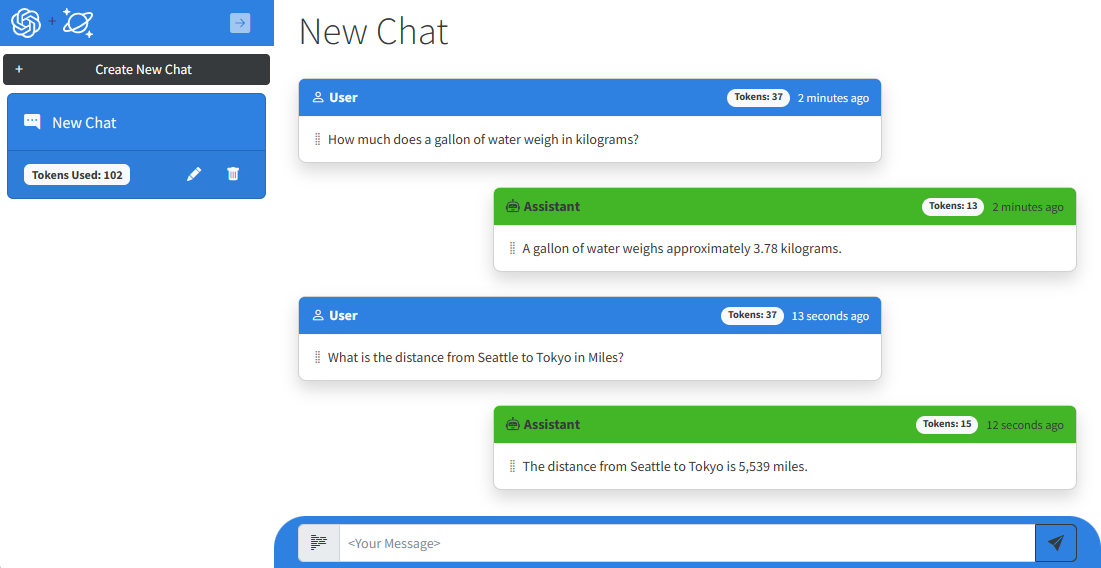
Before getting too far here, some definitions. When interacting with a Large Language Model (LLM) service like ChatGPT, you would typically ask a question and the service gives you an answer. To put these into the vernacular, the user supplies a “prompt”, and the service provides a “completion”. This sample was initially created using the text-davinci-003 model. The current ChatGPT application is based upon a newer model, gpt-3.5-turbo-0301.
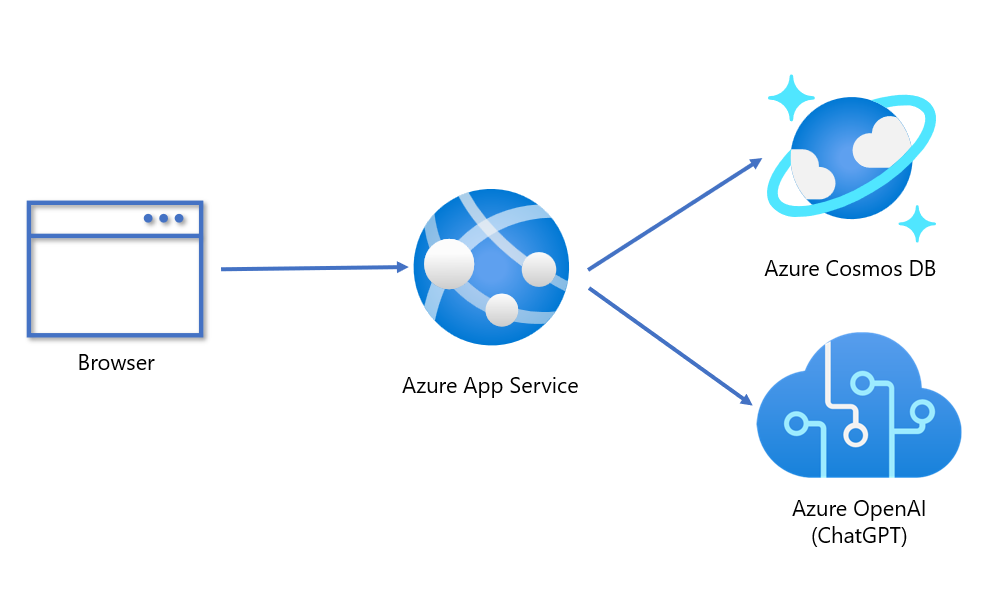
Below is the architecture for our sample. The front-end is a Blazor web application hosted in Azure App Service. This connects to Azure Cosmos DB as the database and the Azure OpenAI service which hosts the ChatGPT model. To make it as easy as possible to deploy our sample application, look for the “Deploy to Azure” button in the readme file for our sample on GitHub. The ARM template will handle all the connection information, so you don’t have to copy and paste keys. It’s completely zero-touch deployment.
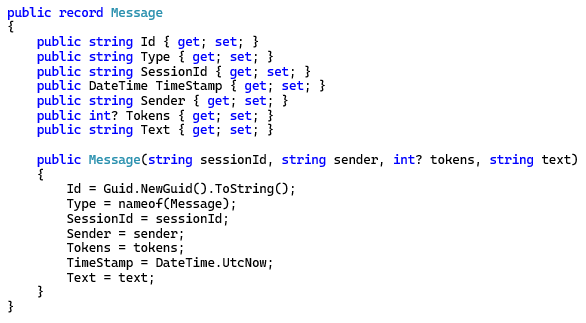
Here is the data model for our application. Very simple with only two classes, chat session and chat message. Everything is stored in a single container.

Giving ChatGPT Memories
If you’ve used ChatGPT at chat.openai.com you may have noticed that in addition to just answering single prompts, you can have a conversation with it as well. ChatGPT gives you an answer, you ask a follow-up without any additional context and ChatGPT responds in a contextually correct way as if you were having a conversation with it.
When designing our sample application using the underlying LLM model, my initial assumption was that LLM’s has some clever way of preserving user context between completions and this was in some way part of the LLM available on Azure. I wanted to see this in action, so I tested the service’s API with prompts I had typed in. However, the service couldn’t remember anything. The completions were completely disjointed.
Let me show you. In this chat below I asked what the seating capacity is for Lumen Field in Seattle. However, in my follow-up, “Is Dodger Stadium bigger?”, it gives a response that is incorrect. You can’t answer yes to the question when the stadium in the follow up question is smaller, not larger than the one asked previously. It looks as though our app is either a huge Dodger fan and in denial about the stadium size or hallucinating that Dodger Stadium is larger than Lumen Field.
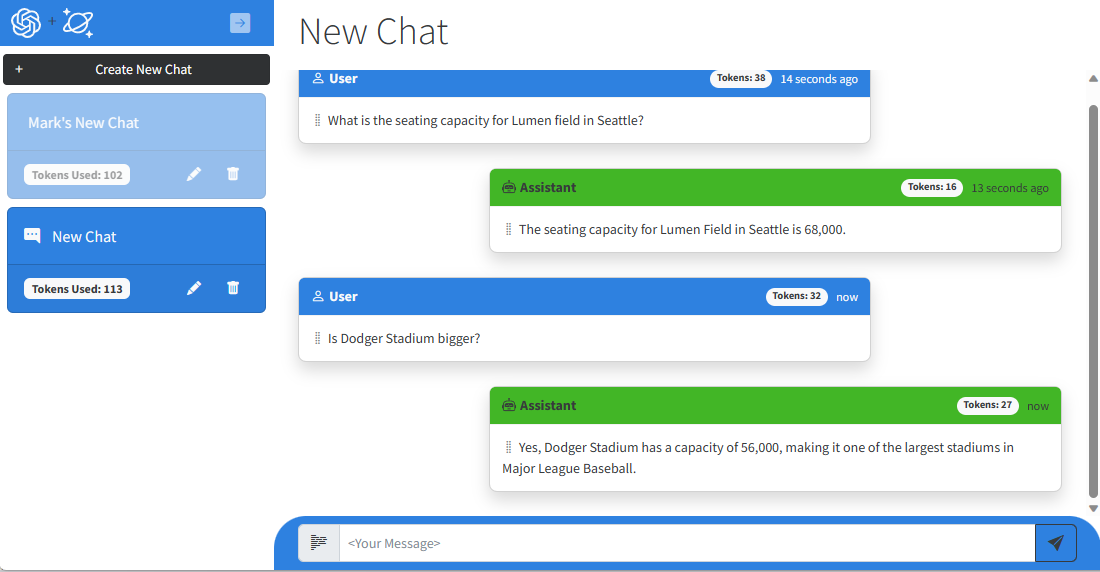
What exactly is happening here? Well, it turns out my assumption was not correct. The underlying large language model, whether gpt-3.5-turbo-0301 or any LLM model, do not have some clever mechanism for maintaining context to enable a conversation. That is something YOU need to provide so that the LLM can respond appropriately.
One way to do this is to send the previous prompts and completions back to the service with the latest prompt appended for it to respond to. With the full history of the conversation, it now has the information necessary to respond in context and correctly. It can now infer what we mean when we ask, “Is that bigger than Dodger Stadium?”.
Let’s look at the same chat when I send the previous prompts and completions in my follow-up.
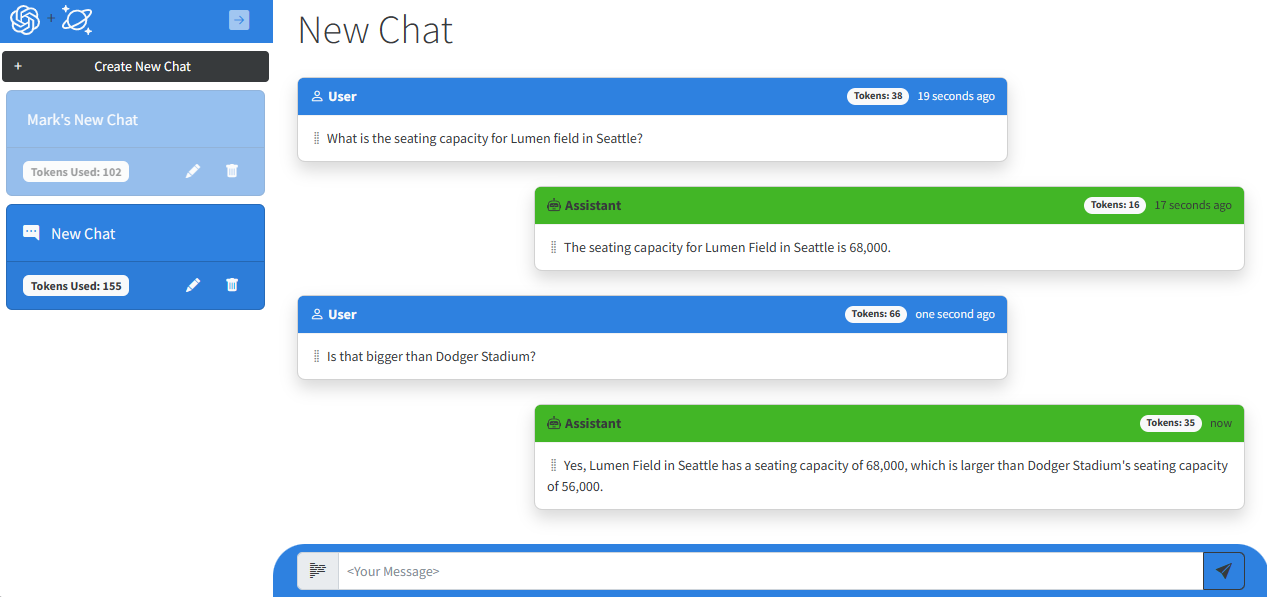
Clearly the response is now contextually aligned with the rest of the conversation. The sample application is now able to mimic ChatGPT’s conversational experience for users.
Some Practical Considerations
While providing a history of a chat is a simple solution, there are some limitations to this. Large Language Models are limited in how much text you can send in a request. This is gated by “tokens”. Tokens are a form of compute currency and can vary in value from one character to one word in length. They are allocated by the service on a per-request basis for a deployed model. The maximum amounts allowed vary across models most of the “GPT” LLM’s up to GPT 3.5 Turbo all have a maximum number of 4096 tokens. In the sample we built, we tested various values for tokens. Here are some things to consider.
First, tokens are consumed in both the request and the response. If you use 4096 tokens sending a complete history in the request, you won’t get anything back in the response because your tokens were all consumed processing the text you sent in the request.
Newer models such as GPT 4.0 have much greater capacity so can potentially handle huge payloads of text for completion generation. However, setting the token limit aside, ensuring efficient token usage is a smart strategy. Also sending large payloads of text on every request is just not something you really want to do. It’s expensive on the client, consumes lots of bandwidth, and increases overall latency.
How We Implemented Memory
To deal with these practical considerations, we limited the amount of memory by sending only the most recent prompts and completions for that conversation. This would allow it to mostly respond with the context it needed to carry on a conversation. However, if a conversation drifted significantly over time, context increasingly would be lost and follow-up questions to older prompts would result in contextually incorrect responses again. Still, this works good enough.
Our initial approach to this was very simple. We simply counted words and set a maxConversationLength of 2000 bytes in our appsettings.json file as a limit. A token can represent a single character all the way up to a word. To be cautious we figured that 2000 bytes would give us enough history to provide enough conversational memory to generate complete responses.
Our next iteration took a more precise approach. When you generate a completion from OpenAI it tells you how many tokens were used to generate the completion. It also tells you how many tokens were used in the user prompt as well. However, since we send more than just the last user prompt the tokens measured includes all the conversational history. You can’t use this amount when calculating max tokens in a request because it overstates the amount since the tokens returned are for the conversation.
The solution was to use a Tokenizer called SharpToken which is a port from OpenAI’s tiktoken and calculate the tokens needed for just the last entered user prompt. This way when we go through the user prompts and completions when constructing our conversational history, we had an accurate count of how many tokens would be used in the request. With that data we added a tokens property to our object model and save the cost for each prompt and completion. We also included this in our session object as well as a total for the entire session or conversation. We could then set the amount of tokens and more precisely manage how many tokens are used in each request, ensuring enough tokens were available to generate a completion to the user.
Here you can see in our implementation. We loop through messages, adding them to an array and counting the tokens which were consumed, then breaks out of the loop once it goes over the _maxConversationTokens amount. Because we build the conversation from most recent to oldest, we build the array in reverse. To put the conversation in the correct order, we call reverse on the List object in a Join function and pass it back to the function calling it.

Make ChatGPT Do It
There is another approach for maintaining conversational context which I’ve seen others suggest and you might consider. You can maintain context for a conversation by asking ChatGPT to summarize or categorize the conversation, then use that instead of sending the full or partial history of the conversation in each request. The benefit of course is drastically reducing the amount of text needed to maintain that context.
There are however some limitations to this approach. For instance, how often should you refresh the summary? How do subsequent refreshes maintain fidelity? Can one maintain fidelity over a long conversation with limited tokens? After pondering these and other questions, we decided this wasn’t the correct approach for us. Our sample application’s implementation was good enough for most use cases.
However, we did end up using this approach, but for something different. If you’ve used ChatGPT, you may notice it renames the chat with a summary of what you asked. We decided to do the same thing and use ChatGPT to summarize the chat session on what the first prompt is. Here is how we did it.

We tried a bunch of different prompts here as well. It turns out that just telling it what you want and why works best. It’s worth pointing out that this was much easier with the older text-davinci-003 model. When we migrated to gpt-3.5-turbo-0301 what we had just would not work anymore. We spent a few weeks testing different prompts as well as tweaking Temperature and NucleusSamplingFactor to try to find the right combination. Turns out that gpt-3.5-turbo-0301 does not do a very good job at following system prompts. This is likely why we struggled. And it still sometimes returns a summary of the chat that isn’t quite right but that’s ok.
Instructing Chat Models
It turns out that what I’ve described in giving an LLM a memory is part of a larger concept around prompts that provide the model with greater context needed to interact with users. There are different types of prompts as well. In addition to user prompts that are used to provide context for a conversation, you can use starting, or system prompts to instruct a chat model to behave a certain way. This can include lots of things from whether to be, “friendly and helpful” or “factual and concise” or even, “playful and snarky”.
One thing that most people don’t realize is Large Language Models like GPT are probabilistic, not deterministic. Each time you send a prompt for a completion there are “probabilities” at work in generating that completion. It’s a bit strange to wrap your head around. Most developers expect things to work the same every time they run the same code. That’s not what happens in these systems. One thing that can help in this regard is Temperature and NucleausSamplingFactor. In our testing, we found that this combination we used, reduced the changes of ChatGPT returning the best summarization for a given user prompt.
Exploring the possibilities
This process of writing a sample application gave me lots to think about. Our intention was to create a simple intelligent chat application that had some ChatGPT features using Cosmos DB to store chat messages. But it got me starting to think about how else I could combine a database like Azure Cosmos DB with a large language model like gpt-3.5-turbo-0301. It didn’t take me long to think of various scenarios.
For instance, if I was building a chatbot retail experience, I could use starting prompts to load user profile information for a user’s web session. This could include information on product or other recommendations. “Hi Mark, your mom’s birthday is next month, would you like to see some gift ideas?” Or simply being able to ask natural language questions without having to scroll through products. “Do you have red socks in size 10 available?” There are limitless possibilities.

Going further
Prompts are great at providing information and arming a chat bot with some simple information. However, there’s a limit to how much data you can feed into a prompt. What if you wanted to build an intelligent chat that had access to data for millions of documents and domain data? You can’t cram GB of data into a prompt. For this scenario you need to do what is called, model fine-tuning. Not only does this result in better responses, but it saves in tokens and reduces latency from smaller request payloads.
This is however, not an approach that makes sense for most users. There is another way which is probably a better approach for most people called, Retrieval Augmented Generation (RAG). There is a good blog post from Pablo Castro which describes what it is and how it works using Azure Cognitive Services. It also links to a GitHub where you can try it for yourself.
UPDATE: I have built some examples of how to build these RAG pattern applications for you to look at. We have one that combines Azure Cosmos DB & Azure Cognitive Search with Azure OpenAI Service for our Vector Search & AI Assistant solution accelerator and reference application. I have also built a second example that uses Azure Cosmos DB for MongoDB vCore’s Integrated Vector Database capability with Azure Web Apps that provides vector search on your operational data in Azure Cosmos DB for MongoDB vCore. Both of these samples are written in .NET. We are looking at porting one or both of these to Python or Node.JS as well.
Stay tuned here as you can expect more from us in this space with product announcements, additional samples and blog posts. What an exciting time for all of us.
Start your journey here!
- Download and explore our Azure Cosmos DB + ChatGPT Sample App on GitHub
- Get your Free Azure Cosmos DB Trial
- Open AI Platform documentation
0 comments