
Bulk support has been available since version 3.4.0 of the Azure Cosmos DB .NET SDK. In this post we’ll go over the improvements released in the recent 3.8.0 SDK and how they affect your bulk operations.
All aboard
As we described in our previous post, the SDK groups concurrent operations based on partition affinity and dispatches them as a single request. This means that if the data is distributed evenly across a wide range of partition key values (with different partition affinity), the SDK can create multiple independent groups of operations and dispatch them in parallel.
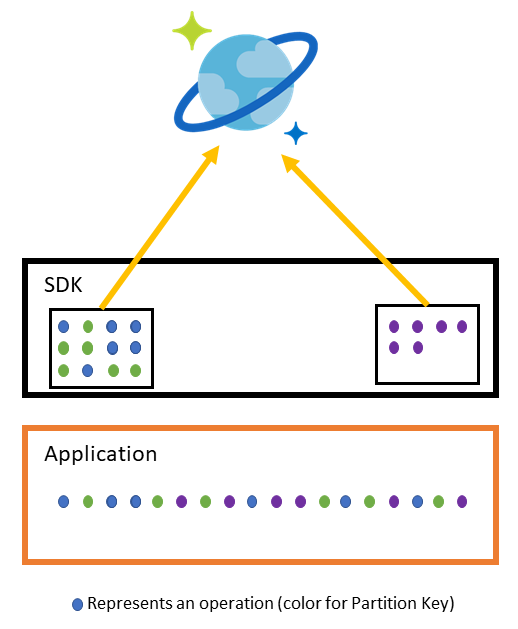
In our initial Bulk implementation, we allowed multiple parallel requests as long as they had a different partition affinity, but only a single in-flight request for each partition.
Think of it as a train station. There will be one train track per partition, and each operation is a passenger inside a train. Multiple trains can depart at the same time as long as they are on different tracks, but on the same track only one train can be moving, the next one will depart when the previous one comes back.
What’s changed?
In 3.8.0, we added a congestion control component to bulk. Now, the SDK will send multiple requests in parallel for the same partition. If it detects throttling, it will start to limit the degree of parallelism on that partition. As long as throttling continues it will keep decreasing it until it achieves a balance between available throughput and volume of requests (or the minimum of 1).
Following the train example, trains heading to the same destination (partition) can now depart as soon as their are full, regardless of whether the previous train came back or not. If a congestion happens on the destination, the manager will reduce the amount of trains that can be on course on the same track at any given point in time until it reaches a balance.
What are the expected improvements?
This change means that we are increasing the data flow from the client and reactively decreasing it if the provisioned throughput is not enough. Early performance numbers show an increase in throughput after this change. For example, in a container provisioned with 300,000 RU/s, we are now able to insert 4.8 million documents in 2 minutes versus 4.3 million before (almost 20% more on the same time).
When measuring time taken, in a container provisioned with 1 million RU/s, inserting 5 million documents now takes 77 seconds versus 350 seconds before (almost 80% faster).
In scenarios where the provisioned throughput is much lower compared with the data volume (for example, inserting 10,000 documents in a container provisioned with 3,000 RU/s), we see an increase in throttling but the overall elapsed time remains in the same line as before.
Next steps
- Get the performance benefits by updating to the latest SDK.
- If you are still using the Bulk Executor library, see our new migration guide to V3 SDK.
Is there a solution for bulk inserting 2000-12000 documents with sub second latency i.e as fast as possible for very high write throughput scenarios?