
Azure Cosmos DB is a resource governed system that allows you to execute a certain number of operations per second based on the provisioned throughput you have configured. If clients exceed that limit and consume more request units than what was provisioned, it leads to rate limiting of subsequent requests and exceptions being thrown – they are also referred to as 429 errors.
With the help of a practical example, I’ll demonstrate how to incorporate fault-tolerance in your Go applications by handling and retrying operations affected by these rate limiting errors. To help you follow along, the sample application code for this blog is available on GitHub and it uses the gocql driver for Apache Cassandra. In this post, we’ll go through:
- Initial setup and configuration before running the sample application
- Execution of various load test scenarios and analyze the results
- A quick overview of the Retry Policy implementation.
One way of tackling rate limiting is by adjusting provisioned throughput to meet your application requirements. There are multiple ways to do this, including using Azure portal, Azure CLI, and CQL (Cassandra Query Language) commands.
But, what if you wanted to handle these errors in the application itself?
The good thing is that the Cassandra API for Azure Cosmos DB translates the rate limiting exceptions into overloaded errors on the Cassandra native protocol. Since the gocql driver allows you to plugin your own RetryPolicy, you can write a custom implementation to intercept these errors and retry them after a certain (cool down) time period. This policy can then be applied to each Query or at a global level using a ClusterConfig.
The Azure Cosmos DB extension library makes it quite easy to use Retry Policies in your Java applications. An equivalent Go version is available on GitHub and has been used in the sample application for this blog post.
Retry Policy in action
As promised, you will walk through the entire process using a simple yet practical example. The sample application used to demonstrate the concepts is a service that exposes a REST endpoint to POST orders data which is persisted to a Cassandra table in Azure Cosmos DB.
You will run a few load tests on this API service to see how rate limiting manifests itself and how it’s handled.
Pre-requisites
Start by installing hey, a load testing program. You can download OS specific binaries (64-bit) for Linux, Mac and Windows (please refer to the GitHub repo for latest information in case you face issues downloading the utility)
Clone this GitHub repo and change into the right directory:
git clone github.com/abhirockzz/cosmos-go-rate-limiting cd cosmos-go-rate-limiting
Setup Azure Cosmos DB
Create an Azure Cosmos DB account with the Cassandra API option selected
Create a Keyspace and Table
Use the following CQL:
CREATE KEYSPACE ordersapp WITH REPLICATION = {'class' : 'SimpleStrategy'};
CREATE TABLE ordersapp.orders (
id uuid PRIMARY KEY,
amount int,
state text,
time timestamp
);
Start the application
Open a terminal and set the environment variables for the application:
export COSMOSDB_CASSANDRA_CONTACT_POINT=<enter Cosmos DB account name>.cassandra.cosmos.azure.com export COSMOSDB_CASSANDRA_PORT=10350 export COSMOSDB_CASSANDRA_USER=<enter Cosmos DB account name> export COSMOSDB_CASSANDRA_PASSWORD=<enter Cosmos DB access key> #optional (default: 5) #export MAX_RETRIES=<enter max number of retry attempts>
To start the application:
go run main.go //wait for this output Connected to Azure Cosmos DB
To test whether the application is working as expected, insert a few orders by invoking the REST endpoint (once for each order) from a different terminal:
curl http://localhost:8080/orders
Confirm that the order was successfully stored. You can use the hosted CQL shell in the Azure portal and execute the below query:
select count(*) from ordersapp.orders; // you should see this output system.count(*) ----------------- 1 (1 rows)
You’re all set.
Let the load tests begin!
Invoke the REST endpoint with 300 requests. This is enough to overload the system since you only have 400 RU/s allocated by default.
To start the load test:
hey -t 0 -n 300 http://localhost:8080/orders
Notice the logs in the application terminal. In the beginning, you will see that the orders are being successfully created. For example:
Added order ID 25a8cec1-e67a-11ea-9c17-7f242c2eeac0 Added order ID 25a8f5ef-e67a-11ea-9c17-7f242c2eeac0 Added order ID 25a8f5ea-e67a-11ea-9c17-7f242c2eeac0 ...
After a while, as the throughput degrades and eventually exceeds the provisioned limit, Azure Cosmos DB will rate limit the application requests. This will manifest itself in the form of an error which looks similar to this:
Request rate is large: ActivityID=ac78fac3-5c36-4a20-8ad7-4b2d0768ffe4, RetryAfterMs=112, Additional details='Response status code does not indicate success: TooManyRequests (429); Substatus: 3200; ActivityId: ac78fac3-5c36-4a20-8ad7-4b2d0768ffe4; Reason: ({
"Errors": [
"Request rate is large. More Request Units may be needed, so no changes were made. Please retry this request later. Learn more: http://aka.ms/cosmosdb-error-429"
]
});
Observing query errors
To keep things simple, we will use the log output for testing/diagnostic purposes. Any error (related to rate–limiting in this case) encountered during query execution is intercepted by a gocql.QueryObserver. The randomly generated order ID is also logged with each error message so that you can check the logs to confirm if the failed order has been re–tried and (eventually) stored in Azure Cosmos DB.
Here is the code snippet:
....
type OrderInsertErrorLogger struct {
orderID string
}
// implements gocql.QueryObserver
func (l OrderInsertErrorLogger) ObserveQuery(ctx context.Context, oq gocql.ObservedQuery) {
err := oq.Err
if err != nil {
log.Printf("Query error for order ID %s\n%v", l.orderID, err)
}
}
....
// the Observer is associated with each query
rid, _ := uuid.GenerateUUID()
err := cs.Query(insertQuery).Bind(rid, rand.Intn(200)+50, fixedLocation, time.Now()).Observer(OrderInsertErrorLogger{orderID: rid}).Exec()
....
How many orders made it through?
Switch back to the load testing terminal and check some of the statistics (output has been redacted for brevity)
Summary: Total: 2.8507 secs Slowest: 1.3437 secs Fastest: 0.2428 secs Average: 0.5389 secs Requests/sec: 70.1592 .... Status code distribution: [200] 300 responses
This is not a raw benchmarking test and neither do we have a production grade application, so you can ignore the Requests/sec etc. But draw our attention to the Status code distribution attribute which shows that our application responded with a HTTP 200 for all the requests.
Let’s confirm the final numbers. Open the Cassandra Shell in the Azure Cosmos DB portal and execute the same query:
select count(*) from ordersapp.orders;
//output
system.count(*)
-----------------
301
You should see 300 additional rows (orders) have been inserted. The key takeaway is that all the orders were successfully stored in Azure Cosmos DB de–spite the rate limiting errors because our application code transparently retried them based on the Retry Policy that we configured (with a single line of code!)
clusterConfig.RetryPolicy = retry.NewCosmosRetryPolicy(numRetries)
A note on dynamic throughput management
If your application spends most of its time operating at about 60-70% of it’s throughput, using Autoscale provisioned throughput can help optimize your RU/s and cost usage by scaling down when not in use – you only pay for the resources that your workloads need on a per-hour basis.
So, what happens without the Retry Policy?
Deactivate the policy to see the difference
Stop the application (press control+c in the terminal), set an environment variable and re-start the application:
export USE_RETRY_POLICY=false go run main.go
Before running the load test again, make a note of the number of rows in the orders table using select count(*) from ordersapp.orders;
hey -t 0 -n 300 http://localhost:8080/orders
In the application logs, you will notice the same rate limiting errors. In the terminal where you ran the load test, at the end of the output summary, you will see that some the requests failed to complete successfully i.e. they returned a response other than HTTP 200
... Status code distribution: [200] 240 responses [429] 60 responses
Because the Retry Policy was not enforced, the application no longer re–tried the requests that failed due to rate-limiting.
Increase provisioned throughput
You can increase the Request Units using the Azure Portal (for example, double it to 800 RU/s) and run the same load test
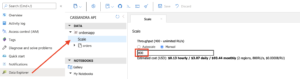
hey -t 0 -n 300 http://localhost:8080/orders
You will not see the rate limiting (HTTP 429) errors now and relatively low numbers for latency, requests per second etc.
As expected, all the orders will be persisted successfully (without any errors or retries)
The next section briefly covers how the custom Retry Policy works.
Behind the scenes
CosmosRetryPolicy adheres to the gocql.RetryPolicy interface by implementing the Attempt and GetRetry functions.
type CosmosRetryPolicy struct {
MaxRetryCount int
FixedBackOffTimeMs int
GrowingBackOffTimeMs int
numAttempts int
}
Retry is initiated only if the number of retry attempts for that query are less than or equal to max retry config or max retry config is set to -1 (infinite retries)
func (crp *CosmosRetryPolicy) Attempt(rq gocql.RetryableQuery) bool {
crp.numAttempts = rq.Attempts()
return rq.Attempts() <= crp.MaxRetryCount || crp.MaxRetryCount == -1
}
GetRetryType function detects the type of error and in the case or a rate-limited error (HTTP 429), it tries to extract the value for RetryAfterMs field (from the error message) and uses that to sleep before retrying the query.
func (crp *CosmosRetryPolicy) GetRetryType(err error) gocql.RetryType {
switch err.(type) {
default:
retryAfterMs := crp.getRetryAfterMs(err.Error())
if retryAfterMs == -1 {
return gocql.Rethrow
}
time.Sleep(retryAfterMs)
return gocql.Retry
//other case statements have been omitted for brevity
}
Azure Cosmos DB provides you the flexibility to not only configure and adjust your throughput requirements using a variety of ways but also provides the basic primitive that allows applications to handle rate limiting errors, thereby making them robust and fault-tolerant. This blog post demonstrated how you can do this for Go applications, but the concepts are applicable to any language and its respective CQL compatible driver that you choose for working with the Cassandra API for Azure Cosmos DB.
To learn more:
Check out some of these resources from the official documentation:
0 comments