
For years, “Database” and “Search systems” (think Elastic Search) lived in separate worlds. While both Databases and Search Systems operate in the same domain (storing, indexing and querying data), they prioritized different aspects.
OLTP Databases prioritized
- Structured and Semi-structured data
- Transactional & Durability Guarantees (ACID)
- Secondary Indexes and Cost-Based Query Optimization
- Operational Aspects – Low-Latency, Scale, High-Availability
- Cost-Effectiveness – through serverless, auto-scaling, pooling, multi-tenancy
Search Systems prioritized
- Unstructured data
- Full-Text Search
- Semantic relevance (more recently with Vector Search, Rankers and LLMs)
AI and Agents are accelerating the dissolution of the boundary between these two systems. AI solves real world problems in near-real-time that needs both of these systems. Using separate systems for these specializations not only leads to high overhead, but leads to sub-optimal relevance.
Since Databases (especially Distributed Databases) have mastered the systems aspects already, including scale, cost-effectiveness, reliability and the fact that databases are already deep in to Indexing and Query Optimizations, Databases are well positioned to integrate Semantic Relevance in to their engines. Adding Semantic Relevance to databases will be a highly innovative addition and an incremental evolution and not a re-architecture of the database engine.
Distributed Databases, that have a first-class Inverted Index like Azure Cosmos DB, are particularly well-positioned to lead the convergence between Databases and Search Systems. This article goes in to depth on how Azure Cosmos DB’s core strengths enables it to lead this shift and evolve in to a Search-Native Database.
Azure Cosmos DB is built as a database that is
- schema-free (JSON-based, semi-structured),
- automatically indexed with an highly-optimized Inverted Index
- automatically partitioned, infinitely-scalable across storage and throughput
- serverless, auto-scaled
- 5 9’s+ highly available, replicated & globally distributed
and is optimized for flexibility, low-latency, high-scale and internet-grade reliability—powering Tier-0 consumer and enterprise workloads under rigorous SLAs. As application patterns have evolved to be AI-first, developers increasingly expect this same level of flexibility to extend beyond traditional data access and into rich, search-driven experiences. And with AI and Agents, all Queries are Semantic Searches.
The core ability that enables the positioning of Azure Cosmos DB as a Search-Native Database is its highly-optimized Inverted Index, which is partitioned, just like how popular search systems like Elastic Search, are.
Azure Cosmos DB has recently invested in several core search capabilities:
- Vector Similarity Search — Allows storing vector embeddings alongside JSON data and performing efficient similarity queries (e.g., k-NN and A-NN) directly within Azure Cosmos DB’s Distributed Engine, enabling Semantic Retrieval without requiring an external Vector Store.
- Full-Text Search — Provides indexing and querying over Text content in documents using Azure Cosmos DB’s native Inverted Index, supporting Tokenization, Phrase Search, Proximity Search, Fuzzy Matching, Lexical Relevance Scoring, and fast retrieval over large, distributed datasets.
- Hybrid Search & Ranking — Combines Vector Similarity and Full-Text Search paths into a unified query model, allowing applications to blend semantic and keyword relevance to achieve more accurate and context-aware results within a single query. One can rank the result-set documents across both Full-Text BM25 Scores and Vector Similarity Distance using Reciprocal Rank Fusion (RRF) for Hybrid Ranking.
- Semantic Re-ranker (in preview) – This improves the relevance by taking the results of Hybrid Search / RRF and feed that in to a cross-encoder or an LLM that assigns a score to the <Query, Document> pair.
- Auto Embedding Generation (available soon) – One can let Azure Cosmos DB automatically create embeddings for the data. This can work with BYOM (Bring Your Own Models) or an automatically chosen model based on the data type (Text, Images, etc).
Lets dive deep in to the strengths of Azure Cosmos DB that makes the above possible.
Azure Cosmos DB Strengths and Differentiators
Schema-Free JSON Documents
Azure Cosmos DB, like popular search systems such as Elasticsearch, is a schema-free, document-oriented database that uses JSON as its primary data model. JSON provides a natural way to represent hierarchical, semi-structured data, enabling dynamic mapping where new fields can be indexed without requiring predefined schemas.
Because JSON documents decompose naturally into key–value pairs, each pair can be treated similarly to Lucene fields or other term–value constructs, making them well-suited for indexing and advanced querying.
Azure Cosmos DB further differentiates itself through its highly efficient and flexible JSON binary encoding and serialization format. This encoding significantly reduces storage footprint and allows direct navigation across nodes in a document without requiring full JSON parsing. To better support search workloads—particularly Vector Similarity Search—we extended this encoding to optimize how vector embeddings are stored. Embeddings, represented as arrays of numeric values of a single type, are now stored as contiguous blocks, enabling both space-efficient storage and fast loading of vectors into memory for query execution.
Inverted Index
Azure Cosmos DB makes no assumptions about the documents. It allows documents within a collection to have varying schemas, along with instance-specific values. This is achieved by representing documents as trees, normalizing both structure and instance values into a unified concept—a dynamically encoded path structure. This is enabled by an inverted index that efficiently and flexibly represents the union of all paths across all documents in the container. The Query Engine leverages this tree-based representation, operating directly on JSON properties at any depth without assuming their existence or data type beforehand.
For representing a JSON document as a tree, each label (including the array indices) in a JSON document becomes a node of the tree. Both the property names and their values in a JSON document are all treated homogenously – as labels in the tree representation. We create a (pseudo) root node which parents the rest of the (actual) nodes corresponding to the labels in the document underneath. Below figure illustrates two example JSON documents and their corresponding tree representations. Notice that the two example documents vary in subtle but important ways in their schema.
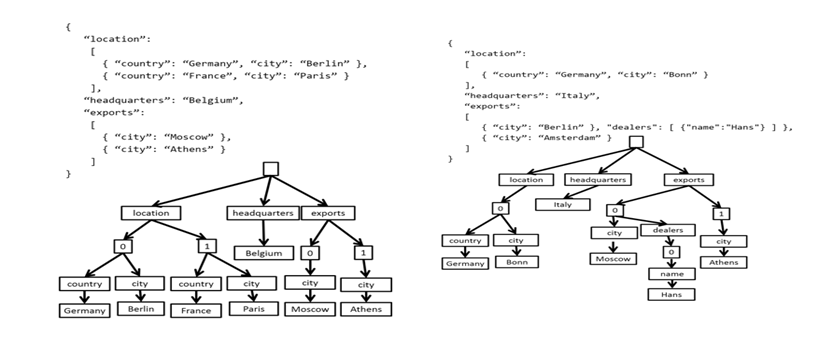
A normalized path representation is the foundation upon which both indexing and query subsystems are built. Given the fact that the Azure Cosmos DB query language operates over paths of the document trees, the inverted index is a very efficient representation. An important implication of treating both the schema and instance values uniformly in terms of paths is that logically, just like the individual documents, the inverted index is also a tree. The index tree grows over time as new documents get added or updated to the collection. Each node of the index tree is an index entry containing the label and position values (the term), and ids of the documents (or fragments of a document) containing the specific node (the postings).
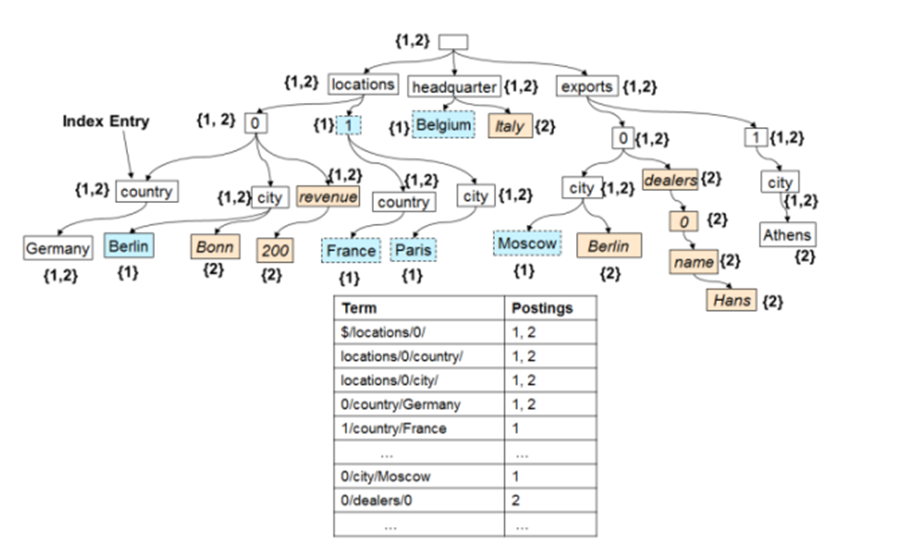
To read more details on our indexing design, please refer to this VLDB paper link. Over the years, more capabilities were added to indexing layer including Composite Indexes which allows efficient searching or sorting across multiple columns at once.
All the above Inverted Index representation is within the context of one partition and there is distributed scale-out engine on top that’s partitioning the Inverted Index using the Partitioning Key that’s specified at the level of an Azure Cosmos DB Collection.
BwTree – the optimized storage engine for Inverted-Index that powers search
Azure Cosmos DB leverages BW-Tree as the core structure for its inverted index, enabling a lock-free, write-optimized, and highly concurrent foundation for search workloads. The BW-Tree’s delta-update and page-mapping architecture allows Azure Cosmos DB to sustain extremely high ingest rates without blocking readers, making it ideal for dynamic, real-time indexing of JSON documents. Its latch-free design ensures predictable low-latency lookups even under heavy contention, while its incremental, non-destructive updates reduce write amplification and avoid costly page splits common in traditional B-Tree implementations. By building the inverted index on top of the BW-Tree, Azure Cosmos DB achieves a combination of throughput, scalability, and consistency that is difficult to match with conventional indexing structures.
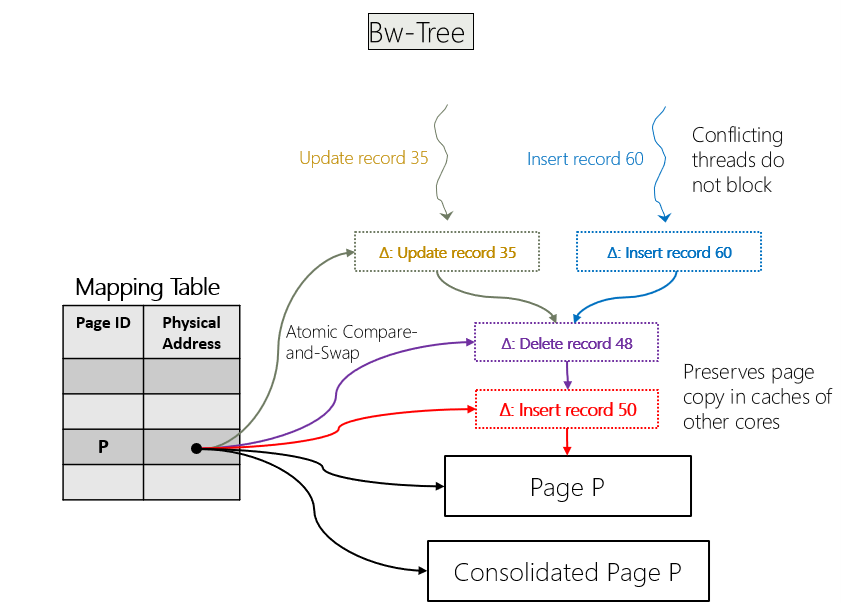
Beyond its BW-Tree foundation, Azure Cosmos DB introduced several innovative solutions that enable the inverted index to support advanced search capabilities.
For Vector Search, Azure Cosmos DB stores embeddings directly within the inverted index using specialized term encodings and contiguous storage layouts, enabling efficient retrieval of vector embedding payloads and allowing vector distance computations to be performed directly on index terms without requiring full document scans. Further, it stores the Quantized Vectors which allows most query processing to avoid loading full vectors and hence improve performance. As we support DiskANN Index, which is a graph representation for searching nearest neighbor, we added support for storing adjacency list in the same index, but encoded as forward index terms since the value is an array of vectors.
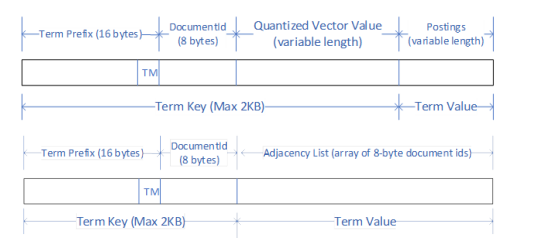
For Full-Text Search, Azure Cosmos DB augments index terms with additional structural metadata—most notably word positions (and word count terms for ranking)—to natively support complex search patterns such as proximity and phrase searches. These enhancements elevate the inverted index from a traditional keyword lookup mechanism to a versatile, multi-modal index capable of powering semantic, lexical, and hybrid search workloads within a single, unified system.
To recap, we insert the following 3 sets of terms to the index, with some examples.
Example:
“With a 2022 population of 749,256[11] it is the most populous city in both the state of Washington and the Pacific Northwest region of North America, and the 18th most populous city in the United States.”
- Position terms with wild card index
/FT/text/String("11") -> DocId (5)
/FT/text/String("america") -> DocId (5)
…more
- Position terms – the location index of each token in the document property.
/FT/text/WordPosition("population"|1) -> DocId (5)
/FT/text/WordPosition("749,256"|2) -> DocId (5)
/FT/text/WordPosition("11"|3) -> DocId (5)
…more
- Word Count Term for the document (the count after stop-word removals)
/FT/text/18 -> DocId(5)
Azure Cosmos DB Query Engine
Azure Cosmos DB’s query engine provides a powerful, fully optimized pipeline that compiles intuitive SQL queries into highly efficient execution plans through a series of progressive transformations. As a query flows through multiple optimization stages, each applying logical rewrites, cost-based decisions, and physical plan refinements, the engine produces execution strategies tailored to both the data model and workload characteristics. The engine further enhances performance through Adaptive Index Evaluation, which dynamically adjusts execution decisions on the fly based on real-time data characteristics and index-selectivity feedback, ensuring the best possible plan is used for each query. This robust compilation framework, combined with Azure Cosmos DB’s familiar SQL syntax, enables deep integration of advanced capabilities such as Vector Similarity Search and Full-Text Search. Developers can express semantic and lexical search operations through natural SQL constructs, while the engine automatically optimizes and orchestrates the underlying vector computations, inverted index lookups, and hybrid relevance scoring, delivering both power and ease of use.
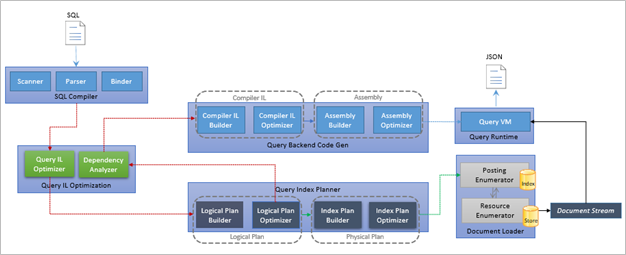
Azure Cosmos DB Search Capabilities
Vector Similarity Search
Azure Cosmos DB supports Vector Similarity Search through three indexing modes—each offering a different balance of accuracy, performance, and storage efficiency:
- Flat Index — Stores full-precision vectors and performs a brute-force kNN scan to compute nearest neighbors, providing exact results with the highest recall.
- Quantized-Flat Index — Uses compact quantized vectors to accelerate brute-force kNN scans; this mode delivers faster performance and reduced storage while maintaining strong recall characteristics.
- DiskANN Index — Enables approximate nearest-neighbor search optimized for large vector corpora. When enabled, Azure Cosmos DB augments the BW-Tree inverted index with quantized vector terms (similar to Quantized-Flat) and graph adjacency list terms representing each vector’s out-neighbors, allowing efficient traversal and querying of the DiskANN graph.
- Sharded DiskANN – Enables design of a multi-tenant vector index where-in, we automatically maintain an isolated DiskANN index for each tenant so there is no cross-tenant overlap of vector index traversal.
Here is a link to VLDB paper with detailed overview of Vector Search on Azure Cosmos DB.
Full-Text Search
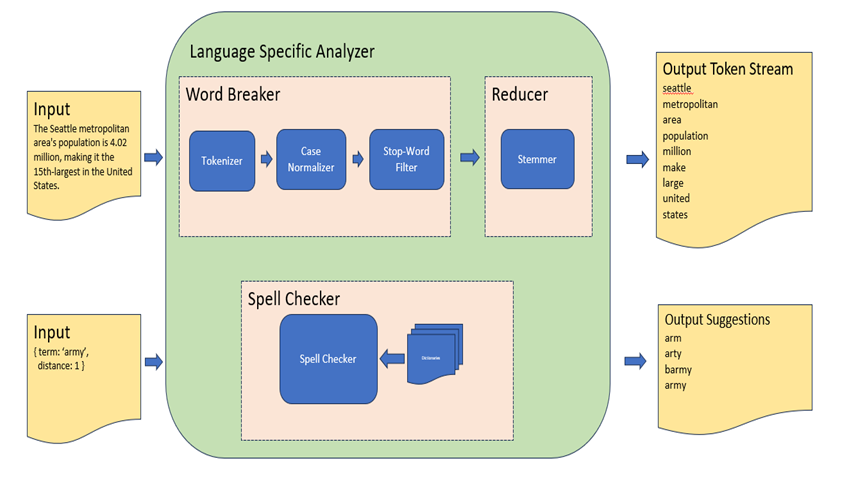
Cosmos DB provides robust Full-Text Search capabilities that enable developers to perform rich, lexical queries directly over JSON documents. Key features include:
- Tokenization and Normalization — Breaks text into meaningful tokens and applies language-specific normalization to ensure consistent indexing and querying. It also enhances with removing stop words and stemming. At runtime, few additional steps may be involved such as Spell Checking, Dictionary / Thesaurus Consultation and other semantic analysis.
- Phrase Search — Allows queries for exact sequences of words, leveraging positional information in the index for accurate results.
- Proximity Search — Supports finding terms that appear within a specified distance of each other, enabling contextual relevance.
- Fuzzy Search — Detects and matches terms with minor typographical or spelling variations to improve recall.
- Relevance Scoring and Ranking — Uses term frequency, inverse document frequency, and other signals to rank results according to relevance. BM25 Scoring mechanism is employed, which depends on Term Frequency, Document Length, Number of documents containing the term and Average Document Length.

Hybrid Search
Azure Cosmos DB’s Hybrid Search seamlessly combines the power of Vector Similarity Search and Full-Text Search into a unified query experience, enabling applications to retrieve results that are both semantically and lexically relevant. By integrating vector embeddings with traditional inverted index terms, the query engine can simultaneously evaluate semantic similarity and keyword relevance, allowing developers to express complex retrieval intents using familiar SQL syntax. The engine’s optimization pipeline efficiently orchestrates the execution of vector distance computations alongside text-based ranking, while adaptive index evaluation ensures low-latency performance even on large datasets. This unified approach allows Azure Cosmos DB to support advanced search scenarios such as semantic search with keyword constraints, recommendation systems, and retrieval-augmented generation, all within a single, operational database.
SELECT TOP 10 *
FROM c
ORDER BY RANK RRF(VectorDistance(c.vector, [1,2,3]), FullTextScore(c.text, "searchable", "text", "goes" ,"here"), [2, 1])
Hope the above shed some light on our evolution as a search-native database. Will keep this blog updated with new insights as we evolve this stack.
Conclusion
AI‑first applications are dissolving the old divide between databases and search systems. Developers now expect semantic, vector, and full‑text retrieval to live inside the operational database itself. Azure Cosmos DB is leading that convergence—its schema‑free JSON model, optimized inverted index, BW‑Tree storage engine, and native vector + full‑text capabilities turn it into a true search‑native database. Features like Hybrid Search, RRF ranking, DiskANN, and upcoming semantic re‑ranking and Automatic Embedding Generation show how relevance and operational scale now belong in the same place. This is the path forward: a single globally distributed system delivering top-tier search‑intelligence in real time.
References
- Cost‑Effective, Low‑Latency Vector Search with Azure Cosmos DB
- Schema‑Agnostic Indexing with Azure DocumentDB
- Azure Cosmos DB Indexing Overview
- Azure Cosmos DB Vector Search
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless NoSQL and vector database for modern app development, including AI applications. With its SLA-backed speed and availability as well as instant dynamic scalability, it is ideal for real-time NoSQL and MongoDB applications that require high performance and distributed computing over massive volumes of NoSQL and vector data.
To stay in the loop on Azure Cosmos DB updates, follow us on X, YouTube, and LinkedIn.
0 comments
Be the first to start the discussion.