
We have released support to run the native Cassandra shell (CQLSH) v5.0.1 on the Data Explorer for Azure Cosmos DB Cassandra API accounts. This provides native Cassandra shell capabilities for database management and CRUD operations in your Data Explorer either in the Azure Portal or in its stand-alone version. It also prevents you from having to maintain separate local (or remote) installations of CQLSH to work with Cassandra API. It will be hosted and maintained in Azure Cosmos DB. To use this feature, your account must enable built-in support for Jupyter Notebooks (available in certain Azure regions).
What is the Azure Cosmos DB Cassandra API?
The Cassandra API is our implementation of the wire protocol defined for the Apache Cassandra database, which exists on top of Azure Cosmos DB infrastructure. This allows open-source Apache Cassandra drivers and applications to target Azure Cosmos DB and use our supported set of features on it. Additionally, applications will get global distribution, elastic scalability, automatic partitioning, and many other features when using Azure Cosmos DB.
How can I get the Cassandra shell?
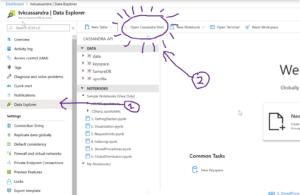
It’s simple! Just check the Data Explorer tab and click on Open Cassandra Shell.
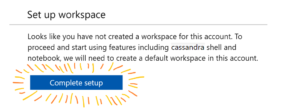
Depending on your account’s specific configuration, you might get the following prompt. Click on Complete setup. This will also enable the Notebooks feature in your account!
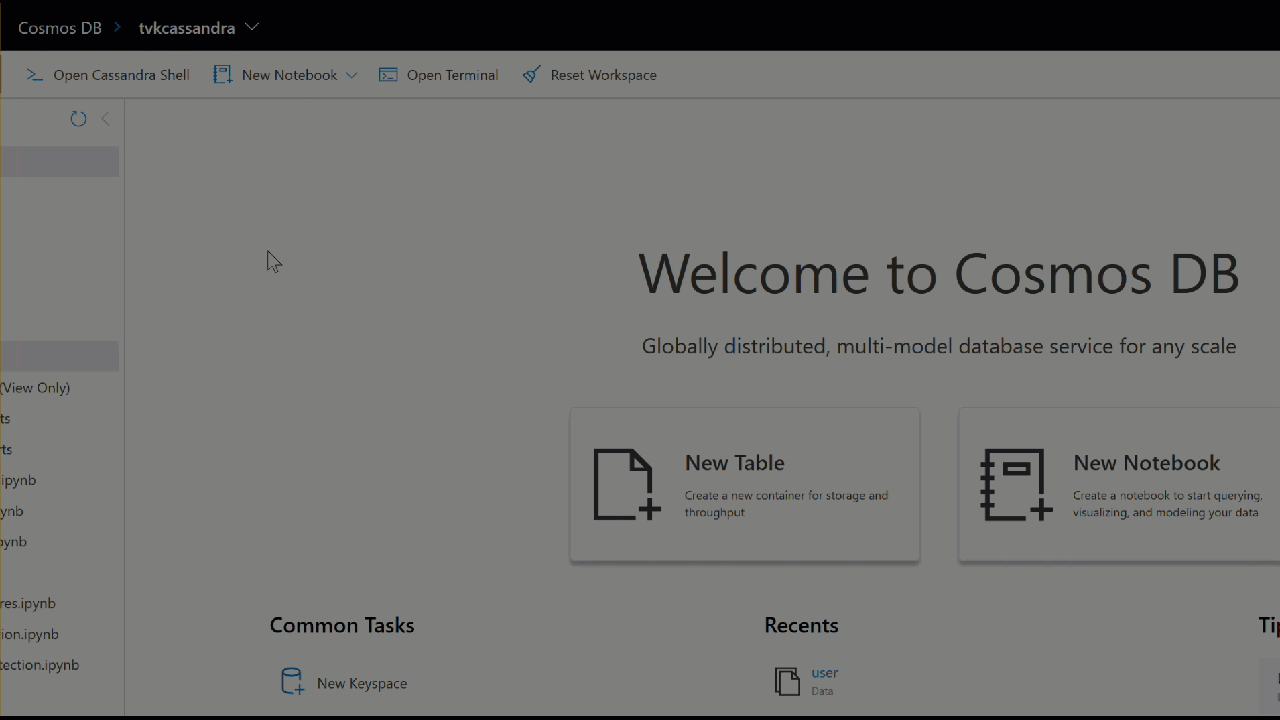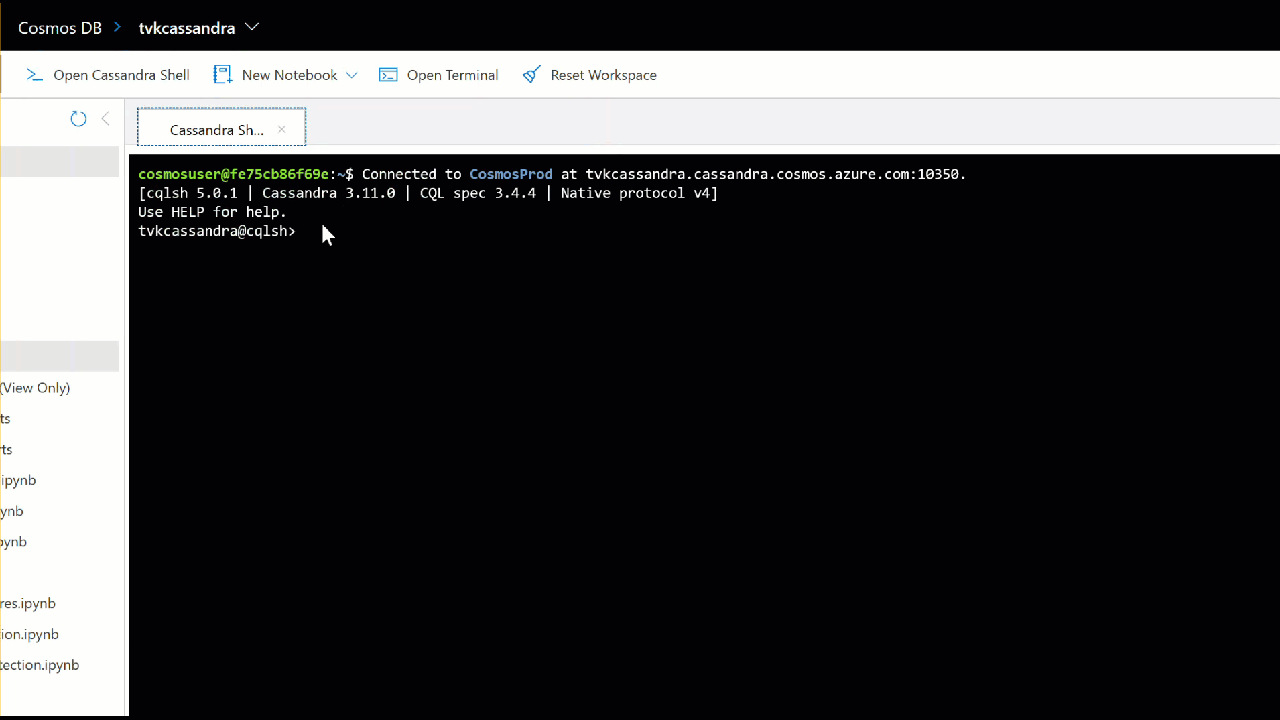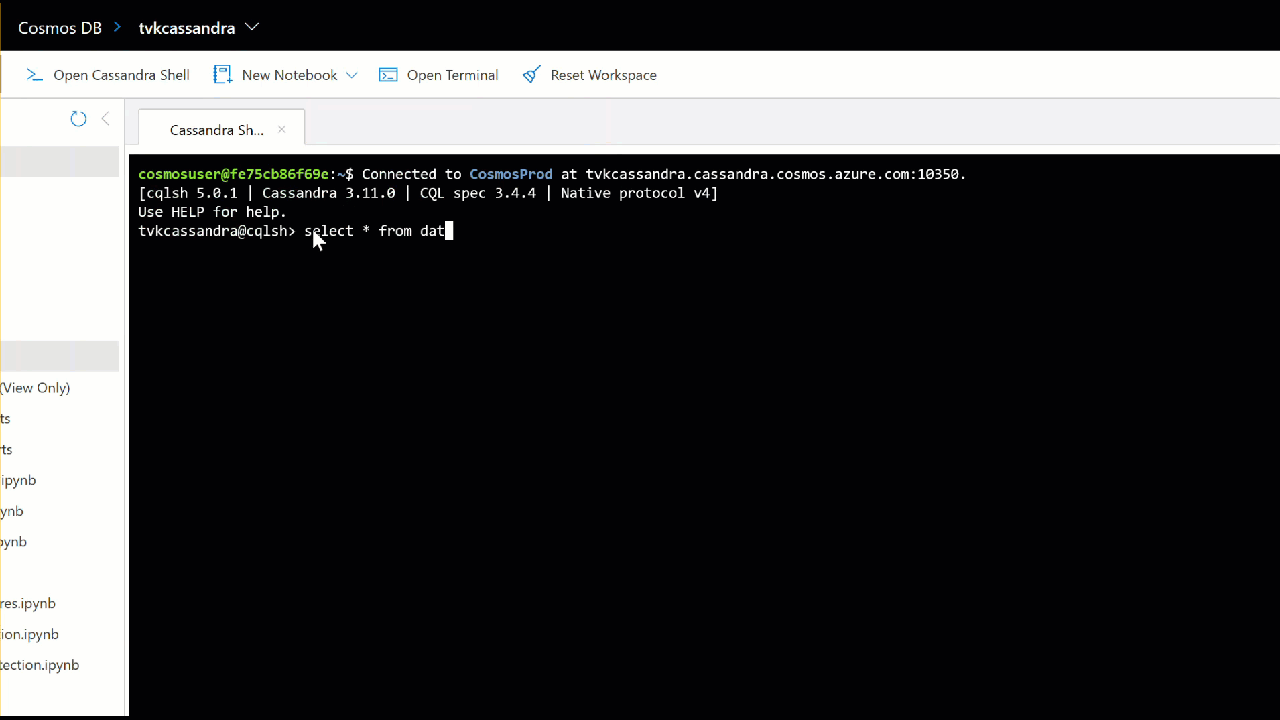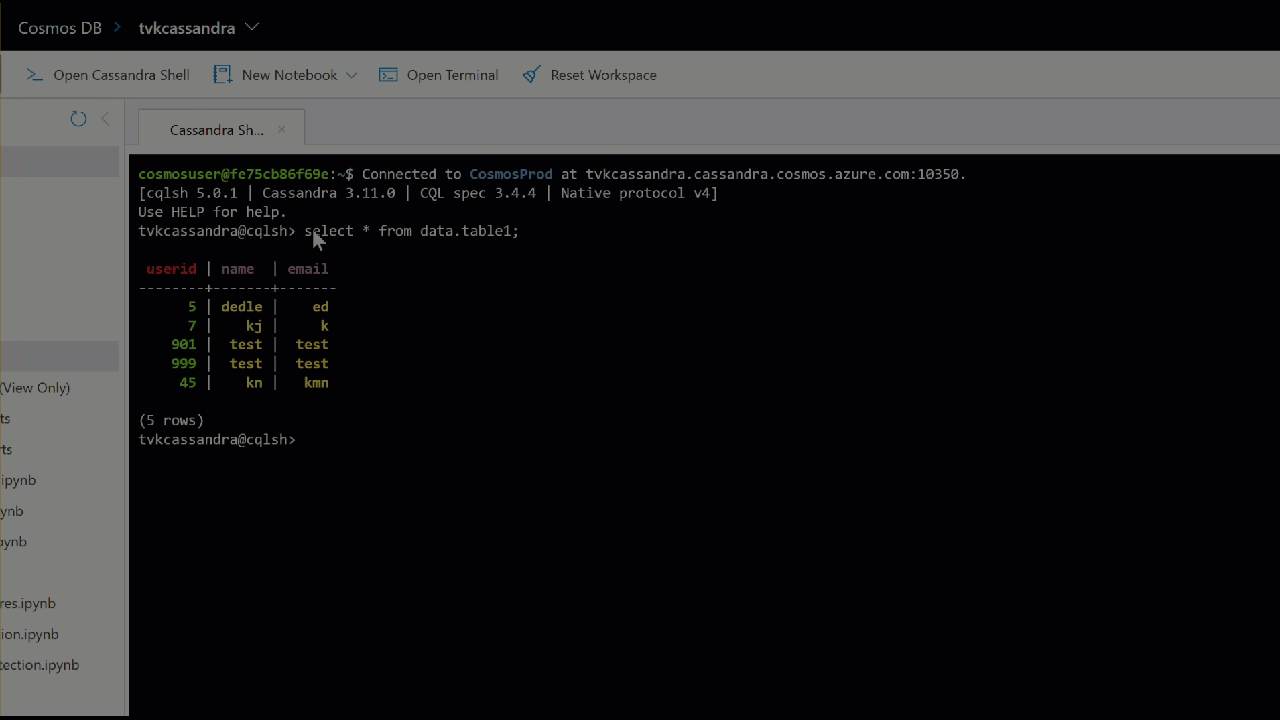
After that, the Open Cassandra Shell button will open a tab with an instance already connected to the account. Voilá! You can now execute Cassandra scripts directly on your keyspaces and tables!
What can I do with it?
It is a fully working CQLSH session, so all the regular native CQL commands will be available to use! If you are new to Cassandra API on Azure Cosmos DB, you may want to check out the commands we support. Additionally, here are a few extra Azure Cosmos DB-specific commands for the Cassandra shell.
Setting Throughout
You can set Request Units (RUs), which are the rate-based currency for provisioned throughput in Azure Cosmos DB, at keyspace level in CQL:
CREATE KEYSPACE sampleks WITH REPLICATION = {'class':'SimpleStrategy'} AND cosmosdb_provisioned_throughput=400;
If you want more performance isolation, you can also set throughput at table level:
CREATE TABLE sampleks.t1(user_id int PRIMARY KEY, lastname text) WITH cosmosdb_provisioned_throughput=2000;
In the above scenario, you would have 2400 RUs in total, with one table having 2000 RUs allocated, and any other tables in the keyspace sharing 400RUs (unless they also have dedicated throughput set similar to the above). You can also change a table’s provisioned throughput with an ALTER command:
ALTER TABLE t1 WITH cosmosdb_provisioned_throughput=10000;
Secondary Indexes
In Cassandra API for Azure Cosmos DB, you do not need to specify index name. A default index with format tablename_columnname_idx is used:
CREATE INDEX ON sampleks.t1 (lastname);
For this example, t1_lastname_idx is the index name created on this table. You can learn more about secondary indexes in the Azure Cosmos DB Cassandra API by reading our official documentation here.
See here for details of all the supported Apache Cassandra operations in Azure Cosmos DB Cassandra API.
Troubleshooting
If you experience any connectivity issues with the Cassandra shell, just close the tab and open a new one in the Data Explorer. This should solve any connectivity problems.
Next steps
- Discover all the features and capabilities of Azure Cosmos DB
- Check out FAQs for Azure Cosmos DB Cassandra API
- Share your ideas for Cassandra shell or Azure Cosmos DB Cassandra API on UserVoice
- Have feedback? let us know in the comments below!
0 comments