

Guest Post
Rodrigo Ribeiro Gomes, Head of Innovation at Power Tuning, has been leveraging the new AI features in SQL Server engine to simplify the lives of DBAs and developers. He generously shared his experience with us: thank you, Rodrigo!I recently created a GitHub repository to share the T-SQL scripts I’ve accumulated over 10 years as a DBA. However, I’ve always struggled to find the right script when I need it. For years, I relied on simple shell commands like find or just my memory, which could take 10-30 minutes, if I was lucky enough to find it.
But, we are in the AI age, so I created that simple web application where you type what you want, and it finds the best scripts for your needs. The solution was created using the following technologies:
- The Gradio Python library, for Chat UI and REST API access
- Open-source AI models, using the SentenceTransformers Python library for generating embeddings and reranking
- Hugging Face for hosting and the ZeroGPU feature, which allows access to high-end GPUs at low cost
- Google Gemini model, to generate answers
- GitHub Actions to trigger PowerShell code that will index files in the GitHub repo
- PowershAI module to access Gradio
- Azure SQL Database with new AI support, where we index the script file contents and search by meaning
In this post, I will focus on SQL Server’s role, exploring its new AI features and their importance to this solution. If you would like a more detailed post that explains not only SQL, but also the Python code and AI models, read the expanded article version on Simple Talk.
Here is a diagram showing all the main components of the project (in this post we will focus on just how SQL was used):
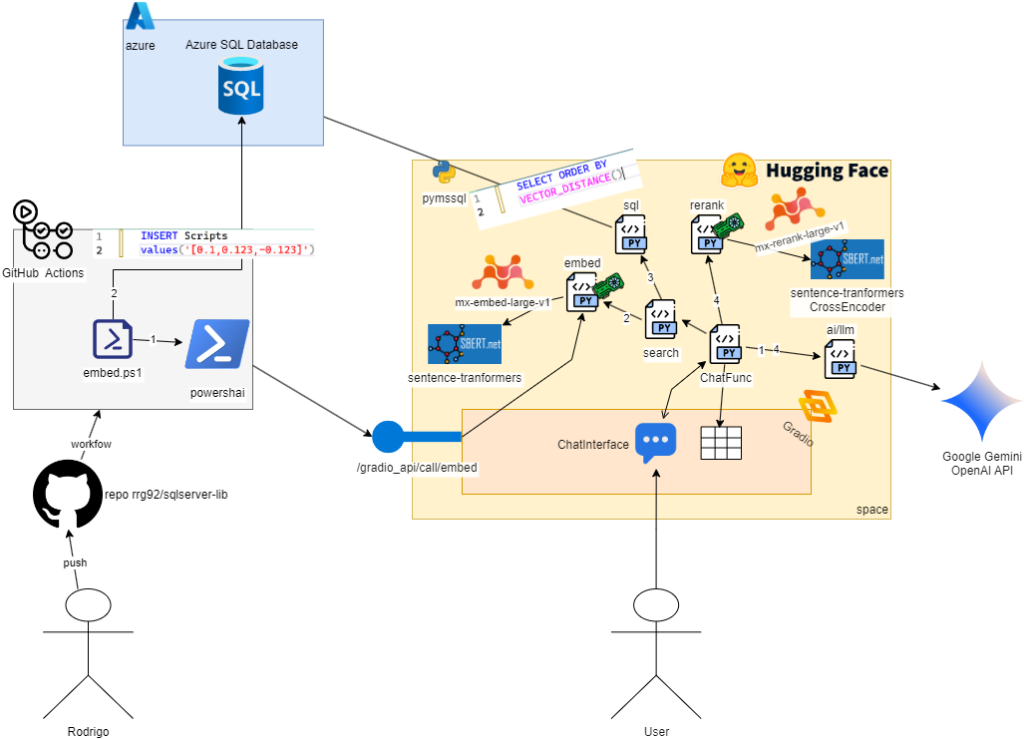
Indexing the data
This project is essentially a RAG (Retrieval Augmented Generation) project where I need to locate the most pertinent scripts from my repository based on the text a user inputs in the chat interface. To accomplish this, we must search for these relevant scripts and utilize a large language model (LLM) to generate a response based on the content of the identified scripts.
The first part of a project like this is indexing the data (our scripts’ content). To do that, we need something called embeddings, which are basically arrays of floating-point numbers generated by an AI model based on the input, and these values can represent the meaning of the text. The flow here is very simple: when I push a specific tag (I chose tag embed-vNN) to the Git repo, a PowerShell script called embed.ps1 will generate embeddings for each script:

The GetEmbeddings function connects to my Hugging Face Space using a PowerShell module I created called PowershAI, which simplifies this process. This approach centralizes embedding generation in the Hugging Face Space.
After generating all embeddings, I insert into tab.Scripts.sql using bulk operation (via .NET method WriteToServer from legacy SqlClient class). This is the table structure:
CREATE TABLE Scripts (
id int IDENTITY PRIMARY KEY WITH(DATA_COMPRESSION = PAGE)
,RelPath varchar(1000) NOT NULL
,ChunkNum int NOT NULL
,ChunkContent nvarchar(max) NOT NULL
,embeddings vector(1024)
)Note the data type of the embeddings column. It is a vector (1024). The 1024 represents the number of positions in the array (also called the number of dimensions). This value depends on the model used to generate the embeddings. More dimensions do not necessarily mean higher quality and, again, depends on each AI model.
For that, I chose this AI model: https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1. I use the powershai module to connect to a Hugging Face Space via the Gradio API and generate embeddings. Later, I will show the code I used to generate the embeddings.
The results are inserted via BULK INSERT into the Scripts table. This is what the table looks like:
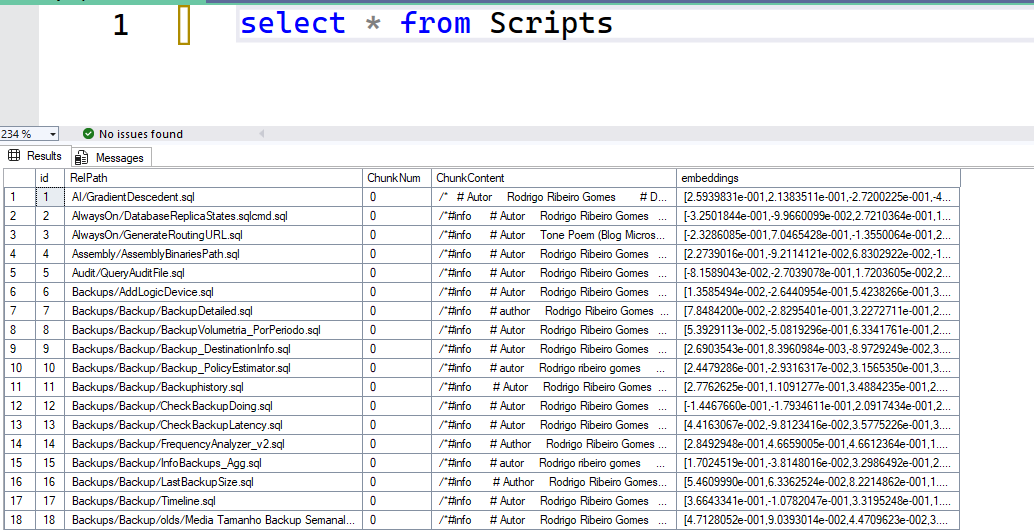
Now, we have a process that keeps that table updated whenever I make updates to the repository. Next, let’s see how I use that data to search and generate a summary for these scripts.
Try in local SQL 2025
If you would like to test on a local SQL Server 2025, I created this script in my git repo. It uses new SQL Server 2025 features, such as the sp_invoke_external_rest_endpoint stored procedure and CREATE EXTERNAL MODEL, to connect to the GitHub API, list files, and generate embeddings using the same embedding function provided by my space. Just follow the comments.Searching Data
Now that we have a table with script content and embeddings, we can use the new SQL Server VECTOR_DISTANCE function to find the most relevant data. In short, the complete process for finding the data is (you can check all that code in file app.py):
- I use the Gradio Python library to build a Chat UI, where the user will send messages
- When a user sends a message, I translate the message to English using an LLM and generate embeddings of the translated message (using the SentenceTransformers library), the same method used to index the data. In my tests, I found that using translated English messages yielded better results for the model I am using.
- Next, I connect to the Azure SQL database using the pymssql library and execute an ad-hoc query to retrieve the most relevant scripts by comparing the embeddings generated in the previous step.
- Use an AI model with the SentenceTransformers library to rerank the results, providing a more precise determination of which script is related to the user’s question.
- Then it passes the reranked result to an LLM, which can better explain and present it in a chat interface.
Let’s look at some parts so you can understand how SQL Server helps.
Here is the search function. That function will receive the text input from the user in its first argument.
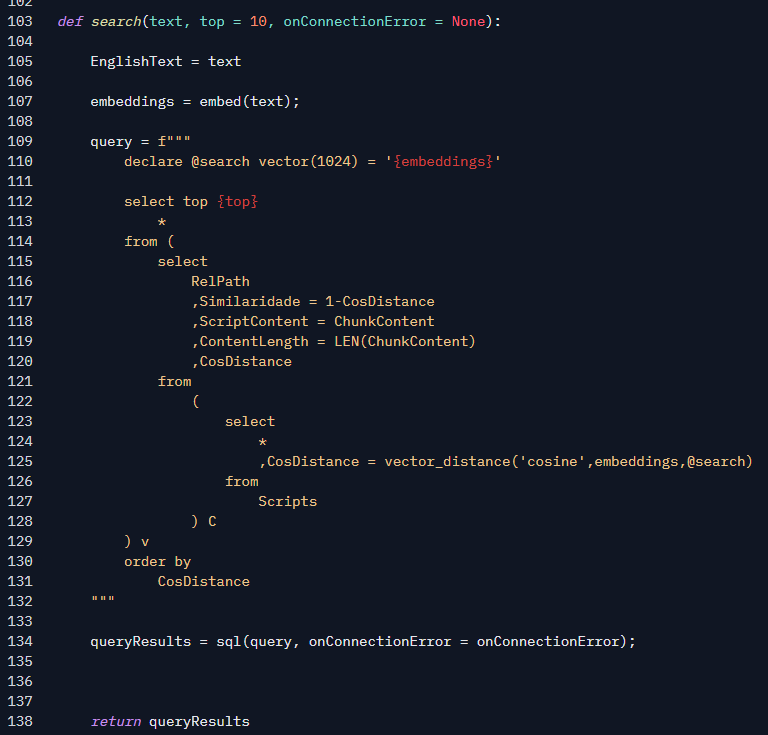
First, we generate embeddings from the translated user text, as shown in line 107. This is the same function that was used to index data (Gradio exposes it via REST API and powershai understand that API). The embed function, defined in line 55, uses an object from the SentenceTransformers library, which loads the AI model called mixedbread-ai/mxbai-embed-large-v1 and expose it simply as that method. Note that the function is decorated with @spaces.GPU: this is what allows the function to use the high-end GPUs provided by Hugging Face infrastructure, so our function runs very, very fast.

So, back to the query, now I have the embedding from the user text, so we can start finding scripts related to it. We need to run a query against our script database to find the rows that best match the user query, using that generated embedding. The query is an ad-hoc query, defined directly into the body of the search function:
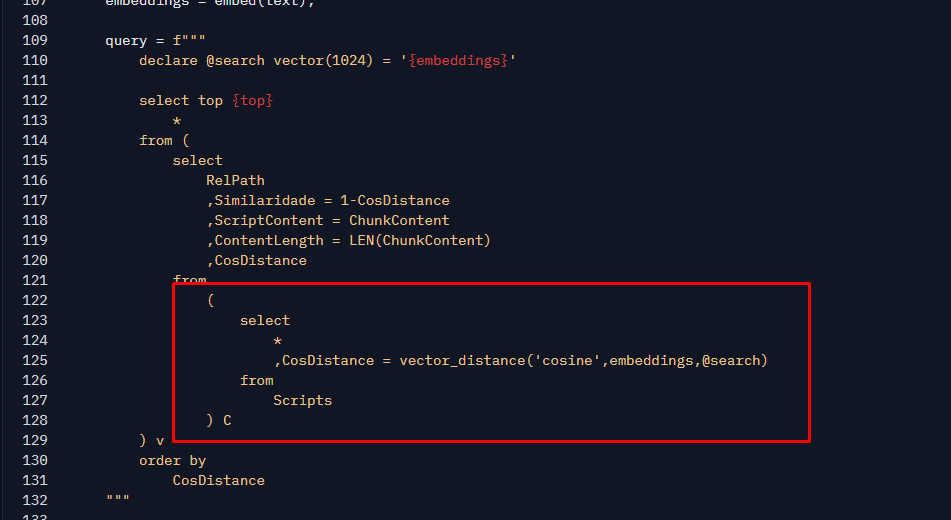
Notice that we don’t filter using common filters like the LIKE operator or any FullText type. In other words, we aren’t filtering text here but searching for the best match using only numbers. These numbers are the embeddings of our search text, stored in the @search variable (using simple string concatenation), and those stored for each script. Remember, embeddings are generated by an AI model and are an array of floating-point numbers representing the meaning of the text. This my post and this video from MVP Deborah Melkin provides a good introduction to help you understand how it works.
Let’s break this down so you understand, starting with the innermost query, highlighted in red in the image above. That query uses a new function called VECTOR_DISTANCE. This function essentially compares two embeddings using a mathematical operation (no AI involved here). In this case, we’re using the Cosine Distance operation. It returns a value between 0 and 2, where 0 means the two input embeddings are identical and 2 means they are different (or opposite). So, to find the best matching script for our search, we take the top result closest to 0; in other words, it’s an ordering by the result of that function.
For example, let’s generate the embeddings for the text ‘cpu performance‘ using our embed function and paste them into the script open in SSMS. It looks like the following:
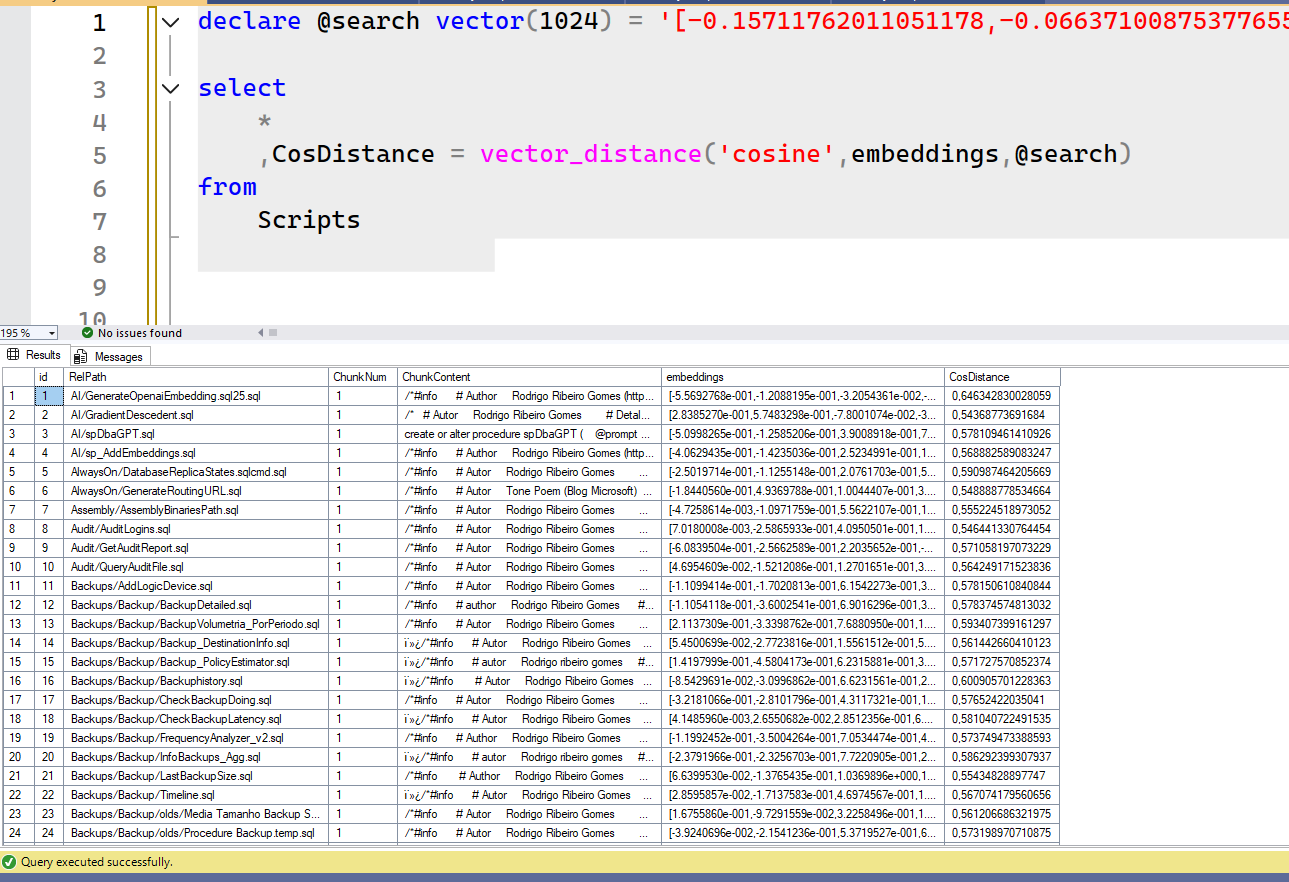
I didn’t include the order by clause for you to see the raw results of the script. Look at the CosDistance column. Some rows are closer to 0 than others. However, if we add order by, we find the best matches.
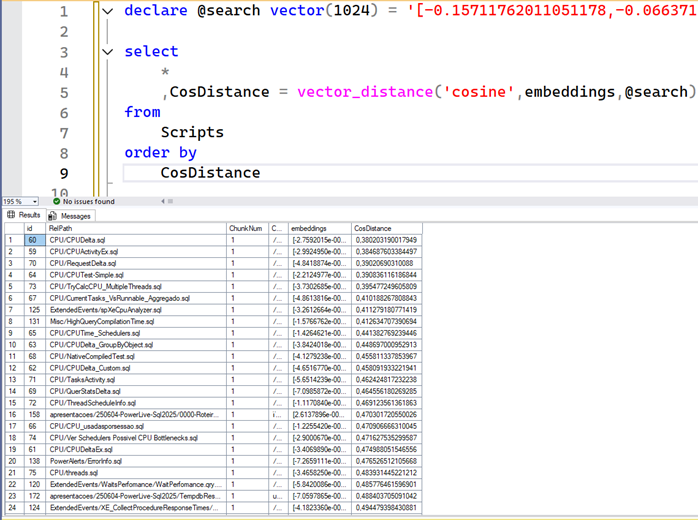
Now, row 1 contains the closest result to 0, which is a script called CPU/CPUDelta.sql… If you look at previous results and compare them with the sorted results, you will see that the latter will bring more results related to our cpu performance text.
Finding the best possible matches
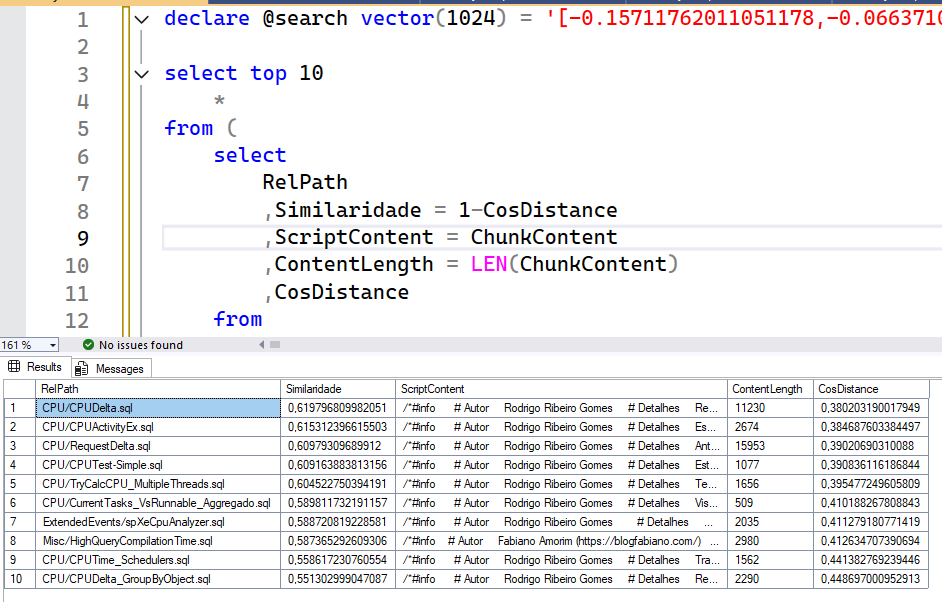
Looking back at the original query, you’ll notice that the order by is actually in the outermost script. I’ve kept it there for readability, and the innermost script is used only to generate the CosDistance column, which I used to calculate the Similaridade column (similarity in pt-BR), which is simply the cosine distance in the range of -1 to 1, where -1 means opposite and 1 means equal. I also added other columns that I return to Python, such as the path and the script content.
Here is a complete sample of what our SQL function would return if the search text was cpu performance:
Vector Index
Experienced readers can note that this query can be very inefficient for tables with millions or billions of rows, and, in fact, it is.Using an ORDER BY with the result of a function can lead to a table scan, causing high memory usage, tempdb pressure, high CPU, and high I/O, especially if this query is run by multiple sessions at the same time. It is a performance killer. For those cases, SQL Server 2025 also brings vector indexes, which can help find the best match in a much more efficient way. In my case, because I will have only a few rows and this is a simple test, I don’t worry about using it for now. But it’s definitely a cool feature you should know about! Your business will thank you!
This result is converted to JSON by Python, and before asking Google Gemini to use it to generate an answer, we perform a process called ReRank, which is carried out by another AI model using the SentenceTransformer library.
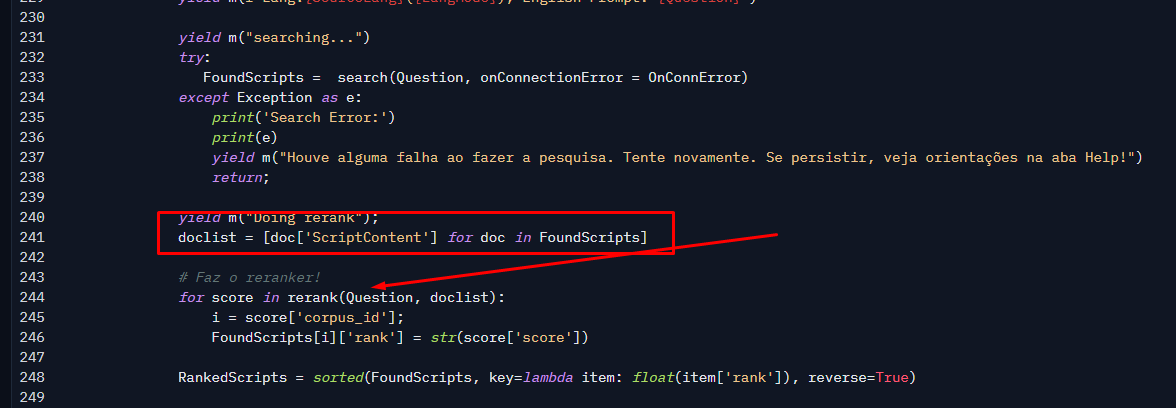
ReRank only retrieves matching results from the query and reorders them, reclassifying them according to the input text. Essentially, we’re asking the AI model: “Given these matches I found in my SQL Server, can you generate a score for how each relates to CPU performance?” The ReRanker AI model is slower than embeddings, which is why we don’t rerank all scripts at once, only a subset. We’re combining the powerful capabilities of embeddings to find good matches with a better model to relate them, making our search very efficient and highly likely to recommend better queries for use. I could filter the top 10 down to the top 3, 5, etc., after reranking, but I’ve simply chosen to keep all results returned by SQL and let Google Gemini decide which to include, as I’ve included the reranked results in the prompt for it to generate an answer.
So, embeddings are not a perfect system or match. They are good for filtering many data points to find better matches. Combined with reranking models, we can produce powerful results.
Conclusions
This was a small example of how SQL Server 2025 and Azure SQL Database can play a key role in AI solutions, and thanks to the vector data type and VECTOR_DISTANCE, we can easily add AI support to our T-SQL solutions and efficiently find good matches for a given text. I hope that provides some examples and clarity.
Thanks for reading this far, and remember that all the code is completely public, so you can try it yourself using those links:
0 comments