

We’re excited to announce major improvements to DiskANN in SQL Server 2025 RC1, making vector search faster, more scalable, and more storage-efficient than ever before.
⚡ Significantly Faster Index Builds
Building DiskANN indexes is now considerably faster, thanks to optimizations that better utilize all available CPU cores and improve the efficiency of vector space traversal. This means quicker index creation and faster time-to-results for your AI-powered applications.
🧠 Improved Scalability Across Processors
SQL Server 2025 RC1 brings enhanced scalability to DiskANN, allowing it to scale more efficiently across all processors. This ensures consistent performance gains as your hardware scales, making it easier to handle large datasets and high-throughput workloads.
🧮 Half-Precision Float (FP16) Support
We’re introducing support for Half-Precision (FP16) floats for the vector data type. This allows you to store the same number of dimensions using half the storage compared to traditional 32-bit floats. Most embedding models are not highly sensitive to precision loss, making FP16 a great choice for the majority of use cases. 👉 Read more here: Half-precision float support in vector data type.
These improvements make SQL Server 2025 RC1 a powerful platform for modern AI workloads, especially those leveraging vector search and embeddings. Whether you’re building intelligent search, recommendation systems, or semantic retrieval, DiskANN in SQL Server is now faster, more scalable, and more efficient.
declare @v16 vector(1536, float16);
set @v16 = ai_generate_embeddings('SQL Server 2025 RC1 rocks!' use model Ada2Embeddings)🧪 Try It Yourself
We’ve already updated the samples so you can try the new FP16 support right away! Head over to:
🔗 https://github.com/Azure-Samples/azure-sql-db-vector-search/tree/main/DiskANN
Use the script in the “Wikipedia” folder to test DiskANN and FP16 end-to-end. You’ll be able to compare vector search results using both FP16 and FP32 with the sample Wikipedia database and decide if FP16 is right for your workload.
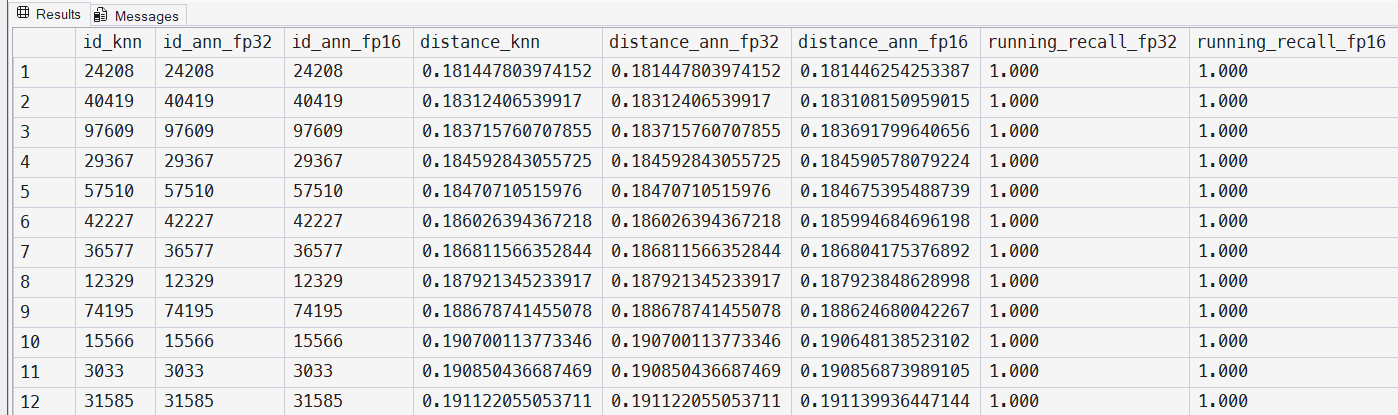
This feature is available under the new – and already well-received – preview_features scoped database configuration option.
As you’ll see in the sample using OpenAI embeddings, you can expect the same great results with just half the storage space. That’s a big win! And don’t worry: we’ve updated the FAQ to answer the question:
“How do I decide when to use single-precision (4-byte) vs half-precision (2-byte) floating-point values for vectors?”
It’s just one click away. Stay tuned for more updates—and as always, we’d love to hear your feedback!
0 comments