


Azure SQL Database and in general the SQL Server engine allows developers to easily get only the changed data from the last time they queried the database. More precisely, there are two features that allow us to do this and much more, providing capabilities to query for changes happened from and to any point in time. The two features are named Change Tracking and Change Data Capture and depending on what kind of payload you are looking for; you may want to use one or another.
What’s the payload I’m talking about? With Change Tracking is just the information that something has changed: you’ll get the Primary Key value so that you can locate the change and then you can look up the last version of the data available in the database directly in the related table. (Here’s a sample)
If you need instead a list of all the changes that happened to the database, along with the data before and after the change, the Change Data Capture is the feature for you.
These two features, quite always, have been only used for optimizing Extract-Transform-Load processes used for BI/DWH. But they can be used to do much more than this, as the Reactive Manifesto highlights.
Many new databases support a Change Stream, which is just an easy-to-consume version of Change Data Capture
For example, both MongoDB and CosmosDB offer a cool feature called Change Stream in the first and Change Feed in the second, that are basically a simplified concept of the aforementioned Change Data Capture, with a big, important, difference: the stream is easily accessible via specialized API that follows a pub/sub pattern, allowing any application (and more than one at the same time) to be notified when something has changed so that it can react as quickly as possible to that change.
While the same behavior could be obtained with SQL Server, using Change Data Capture and Service Broker, the code is way less simple and putting all together is quite an effort that the average developer doesn’t want or just can’t sustain.
The ability to get the changes that happens in a database and send it to a message bus for near real-time consumption is becoming a base requirement.
Patterns like CQRS and Event Sourcing are becoming more and more popular (again, see the Reactive Manifesto), and microservices architecture are all the rage, the ability to get the changes that happens in a database, nicely wrapped into a JSON or AVRO message, to be sent into a message bus for near real-time consumption is becoming a base requirement.
Message bus, today, is almost a synonym for Apache Kafka, as such technology is so common and widely adopted that any solution that contemplates sending streams of data somewhere, needs to take it into account.
Apache Kafka is used for building real-time data pipelines and streaming apps.
It’s now time to have SQL Server, Change Data Capture and Apache Kafka working together to provide a modern, easy to use, Change Data Capture experience.
The magical black-box
Thanks to an open source solution called Debezium and some — as usual, if you’ve been following me—lateral thinking, a very nice, easy to manage, simple solution is at hand. Here’s the diagram that shows how SQL Server Change Data Capture can be turned into a data stream supported by Kafka, just using Debezium:
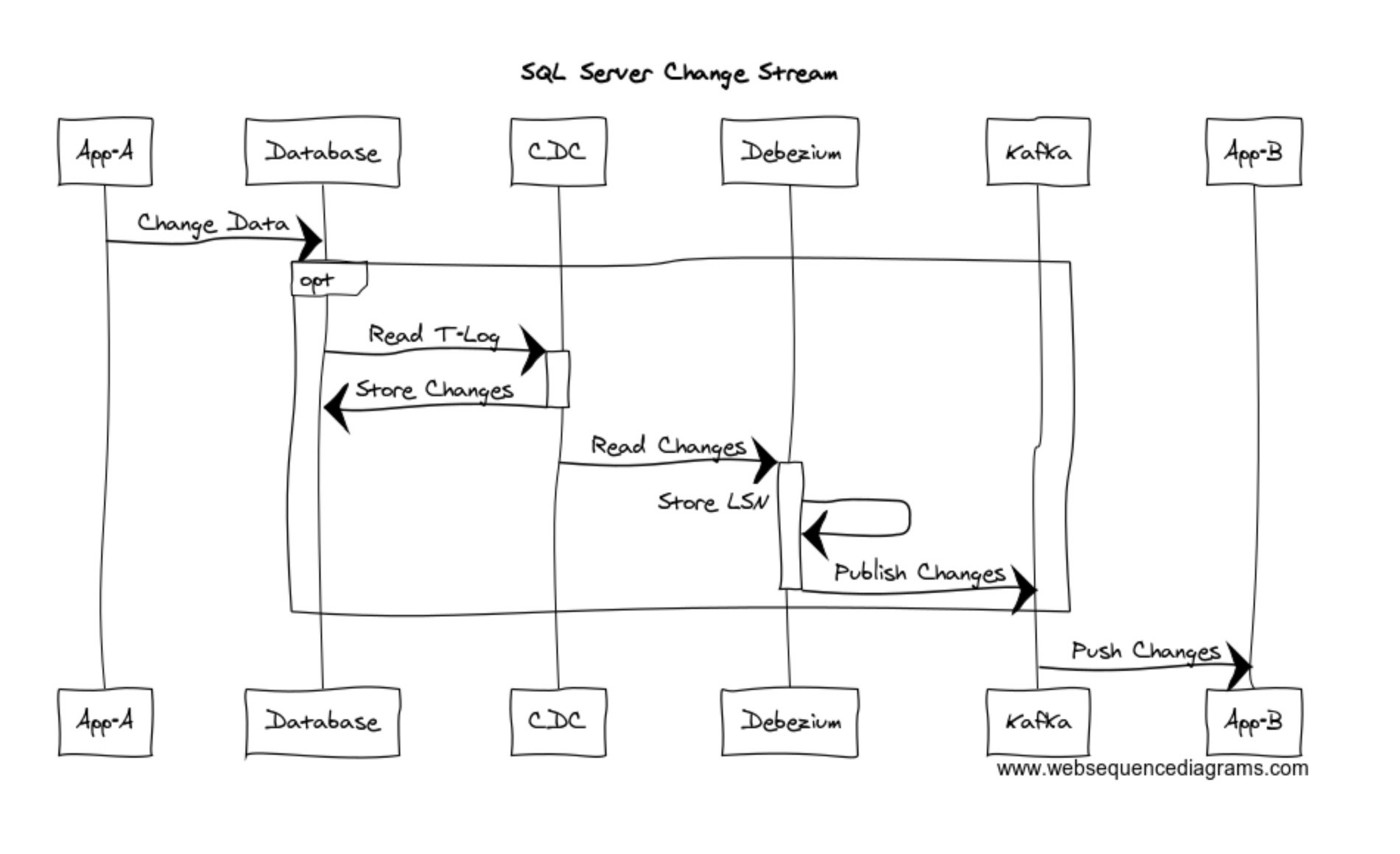
The beauty of all of this is in the “opt” — optional — box: if you don’t want to go into the nitty-gritty details, just color the box black: you’ll see that as soon as an application “A”, make some changes to the data in the database, automagically that changed data will be published as a message in your running Kafka instance, so that your super-modern application can consume it near real time. You can use Node, Python, Java, C# or any language to has support to Apache Kafka…which means almost any language available today.
On Azure, Event Hubs can be used instead of Apache Kafka, to make the solution even simpler
You’re really not an Apache Kafka person, but still like the idea of having a stream of changes and a microservices architecture? I hear you: that’s why, in the sample available on GitHub, instead of Apache Kafka I’m using Event Hubs: all the nice things without the burden of maintaining an entire Apache Kafka cluster.
https://github.com/azure-samples/azure-sql-db-change-stream-debezium/
Now, if you’re developer not really interested in database internals, you can just stop here, and try the aforementioned sample on GitHub. I’m pretty sure you’ll love it — it also uses Azure Function to consume data coming from Event Hubs Kafka endpoint — as it will allows you to realize that you can really have the best of both worlds finally: a proven, flexible, transactional database and a great developer experience.
You have the best of both worlds: a proven, flexible, transactional database and modern, reactive, event-driven developer experience
If, instead, you want to understand how everything works behind the scenes, read on.
Inside the black box
Debezium is actually a Kafka Connect extension: it uses Kafka Connect API to store and manage configuration and metadata.
Debezium requires Change Data Capture to be active on the source database for the tables you want to monitor. Change Data Capture has a small performance impact, so on extremely complex databases, you may want to enable it only on certain tables. On a 1000 tables database I doubt it could make sense to enable it on all the tables (as a general rule), even because you may end up streaming changes that no-one is interested in. That would be just a waste of resources. If, instead, you really need to enable it on all tables, do it, just make sure you understand how Change Data Capture works behind the scenes (it will use some space, of course, and you don’t want to saturate your disks, right?) and how to properly manage Apache Kafka as you may have to deal with a lot of messages per second (and again, space usage may become an issue).
If you’re a Apache Kafka expert and/or already have an Apache Kafka instance running somewhere, you can just deploy Debezium as you do with any Apache Kafka connectors, otherwise you can create a proof-of-concept using the very useful Debezium container. This is what I do in the GitHub sample mentioned before.
Now, let’s dive a bit into the details: Change Data Capture is actually a SQL Server agent Job that continuously read the transaction log and every time there is transaction related to a monitored table, it extract the payload, which is the data before and after the transaction and stores it into a “CT_” table, which will then contain the history of all transaction in form of a sequence of actions ordered by LSN, log-sequence numbers. Do you want all the changes happened after the last time you took a look at the table? Give me the LSN, or the equivalent date and time, and SQL Server will tell you everything happened since then. While these tables are freely usable, there are specific system functions that allows you to easily get all the changes happened to that specific table from a point in time to another.
Here’s the detailed article that explains how it works:
Debezium is our friendly observer that will wake up every defined seconds to take a look at the monitored tables, to see if there are any changes from the last time it checked. If yes, it will read everything and send it to the defined Apache Kafka endpoint. By default, it will create a Kafka Topic per table, but you can define routes to direct the generated messages to the topic you want.
Once the read process is finished, Debezium will store the related LSN into the Kafka Connect infrastructure (a “system” Topic, usually named offsets) so that it will be used the next time as the starting point from where to get changes.
As mentioned earlier in the article, you may not want to deal with Kafka at all, as it is a quite complex beast itself. You’re in good luck, as Azure Event Hubs can almost completely replace Apache Kafka. All the details, and more, to understand at 100% how the entire solution can work, have been documented in the GitHub readme, please take a look at it if you want to create something I described so that it will work in production.
And what if you’re a Kafka enthusiast already? Would it make sense to use Azure Event Hubs instead? Well, if you already have Apache Kafka running, I would strongly recommend using something like MirrorMaker to take advantage of the deep integration of Azure Event Hubs with the rest of the Azure ecosystem, Azure Function among all. Reacting to events being set to Event Hubs with Azure Function is extremely easy and it is a pure Serverless approach, so I really really recommend it.
Where can I use this?
Honestly? Everywhere! The stream-processing (or event-based, reactive, architecture) approach is applicable everywhere and it will become more and more popular as soon as more people start to give near real-time updates and actionable insights for granted. No more batch updates.
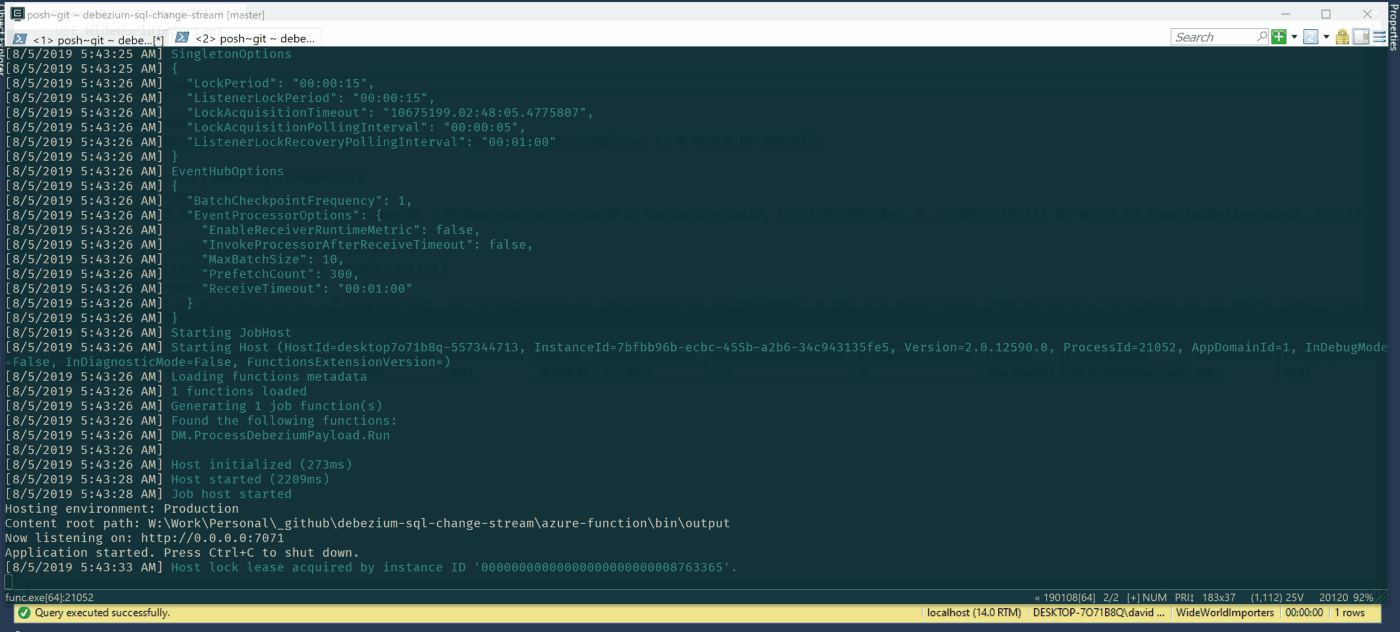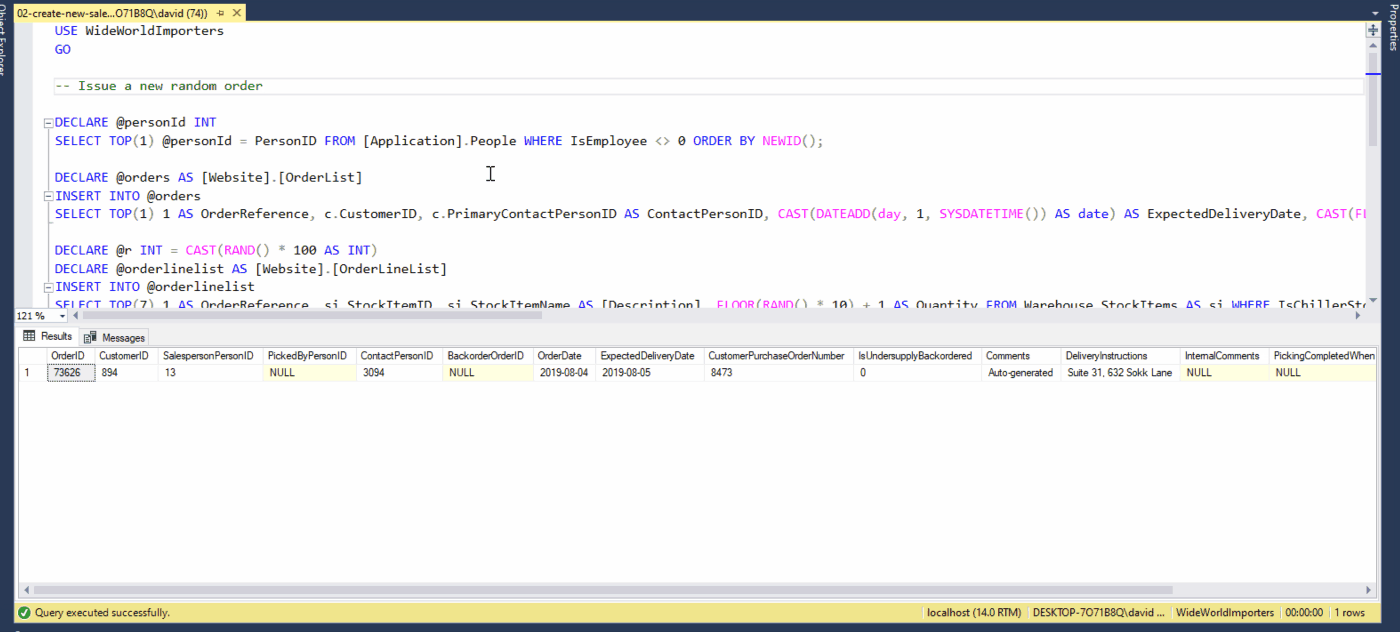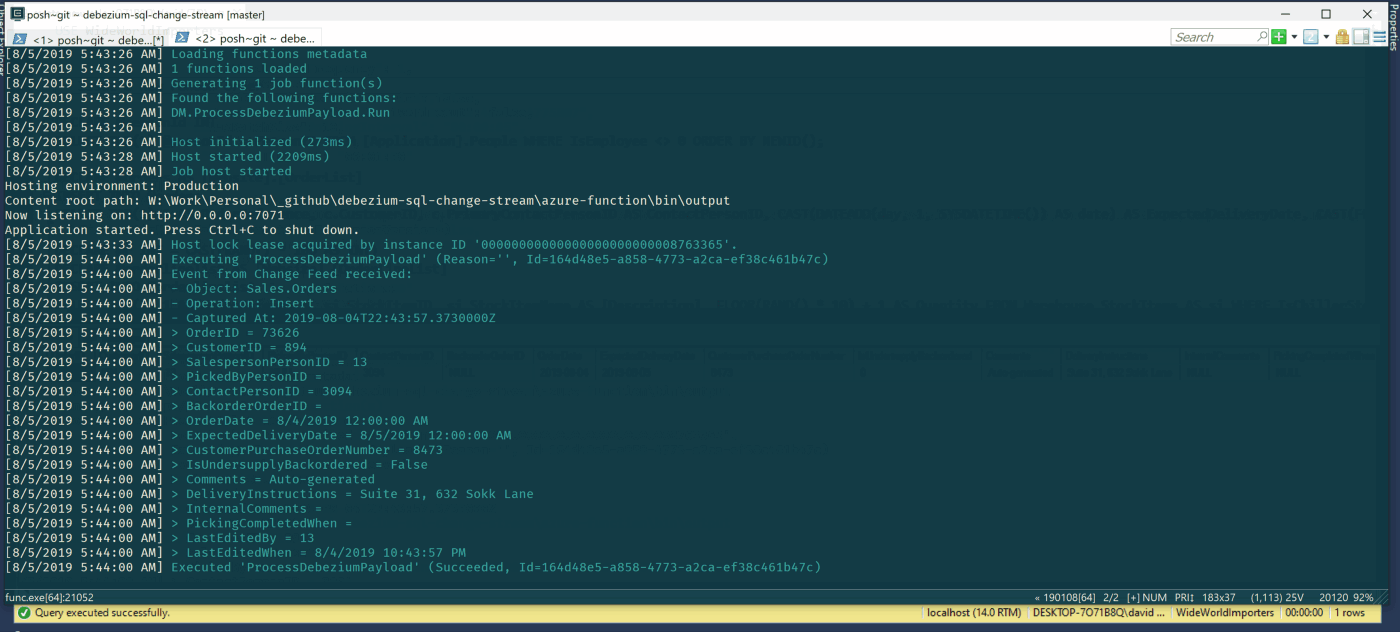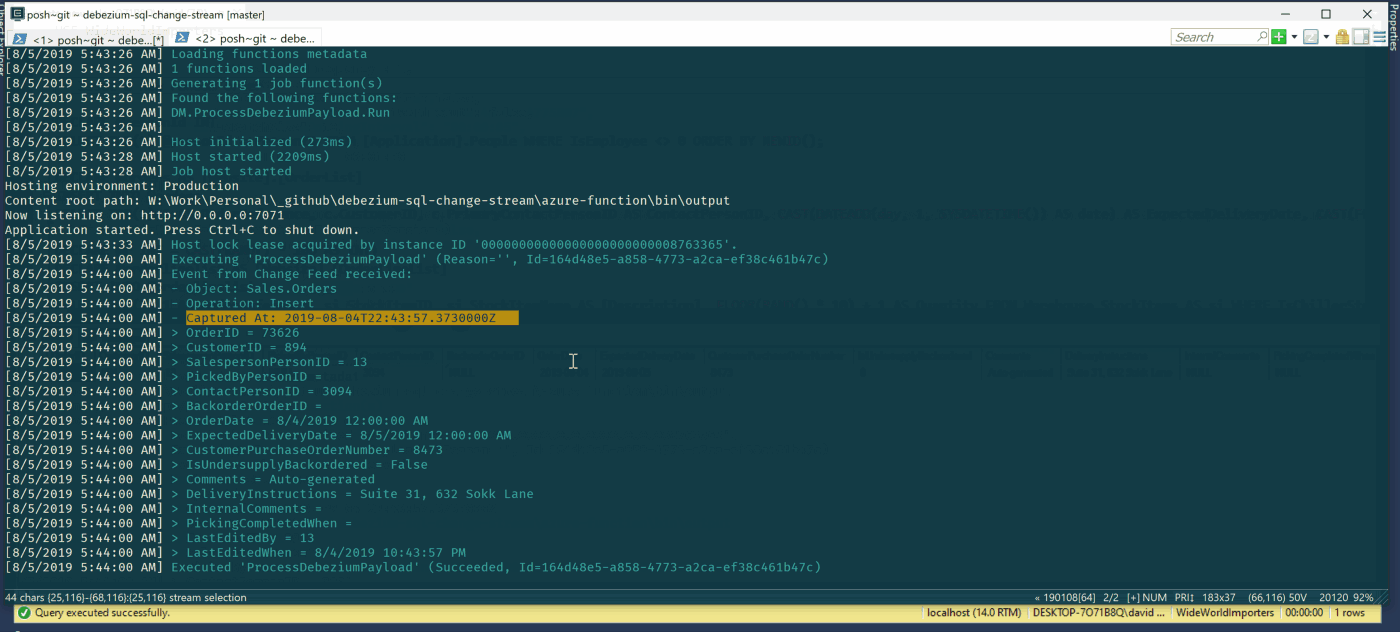
Is a new order inserted into the system? Good, we can immediately notify the physical warehouse to start to prepare the shipment if possible. In the meantime, data can be sent to the data warehouse to update sales statistics and forecasts. And at the same time, update the customer portal with transaction info and update customer fidelity points.
Or a “smart assistant” is monitoring the price something a customer has in his/her wish list and so a notification needs to be sent as soon the price meets the desired criteria.
Or you’re modernizing an existing (legacy?) application, and you want to start to introduce a microservices architecture to make sure you can leverage all the new cloud features even if your application will stay on-premises for a while.
As you can see it is easy to re-imagine well-known scenarios where batch processing is well established and that can get quite a lot of innovation by this new approach.
Now you know what to do to innovate and modernize: go and have fun!
https://github.com/azure-samples/azure-sql-db-change-stream-debezium/
0 comments