


Part 1 of 4 – The Multi-model Database Series
This is a four-part series about what happens when a single database engine handles relational, document, graph, vector, and analytical workloads natively – and what you stop paying for when it does.
You spin up a database, point an agent at it, and start building. The first few tables go fast – users, orders, maybe a product catalog. The agent writes your CRUD, wires up the API, and you have a working prototype by lunch.
Then the requirements come in. The product team wants semantic search. The fraud team needs to trace connections between accounts. Marketing wants real-time dashboards. Your IoT pipeline sends nested JSON that does not fit any table schema.
So you start looking. Does your database have a vector extension? Is there a graph plugin? Can it handle JSON natively, or are you storing it as a string and parsing it on every read? Each question leads to a different answer: install this extension, spin up that managed service, add a sync pipeline between them.
This is where building fast stops being fast. Not because the agent slowed down – but because you are now managing three databases, two sync jobs, and a growing list of things that can break at 2 AM. In an agentic world where the whole point is velocity, your database architecture should be the last thing holding you back.
1. The Fraud Check
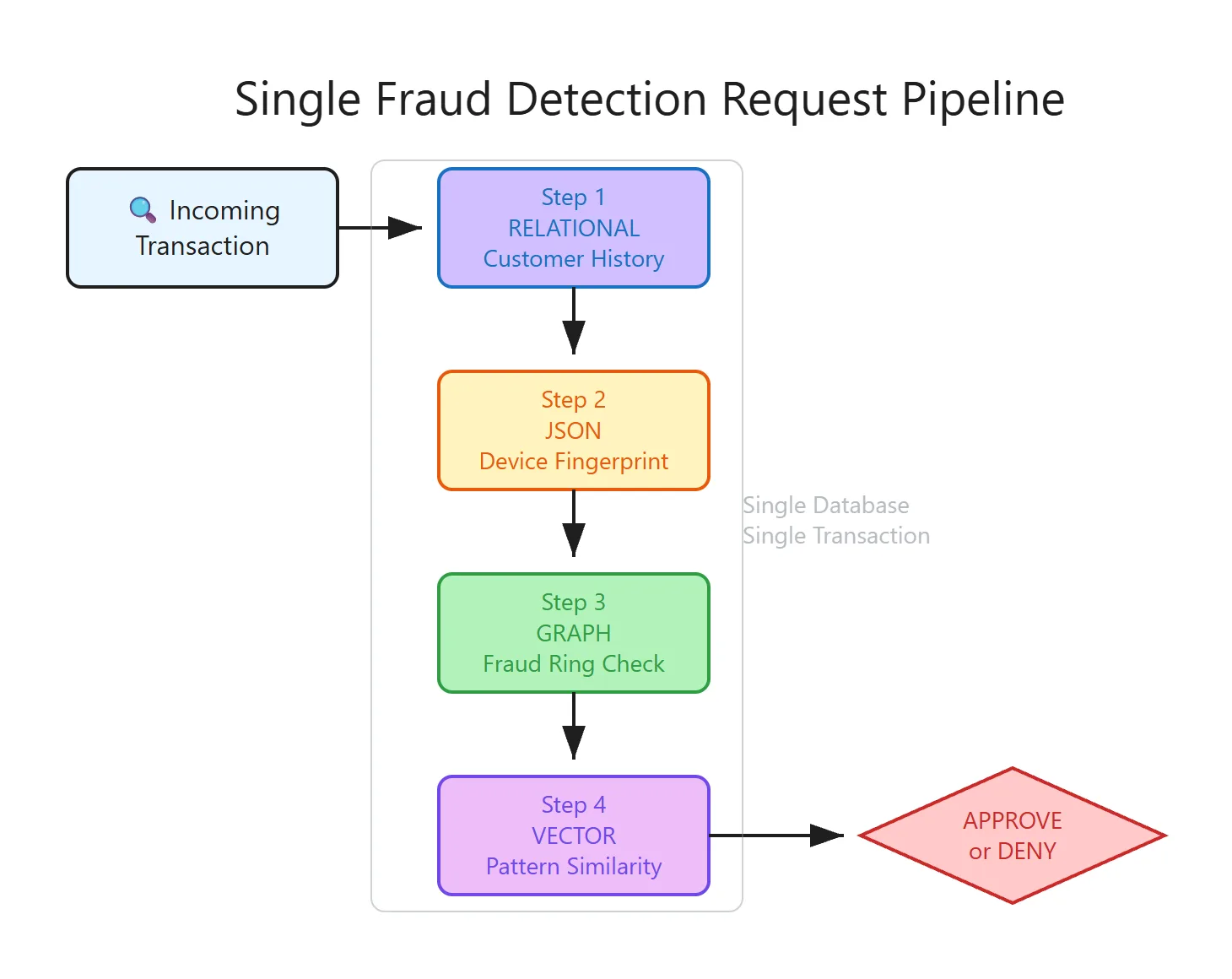
Consider a fraud detection system for an e-commerce platform. A transaction comes in. Before we approve or deny it, we need to check five things:
- The customer’s order history – relational joins across orders and line items
- The device fingerprint – a nested JSON blob (browser, geolocation, screen resolution)
- Whether this user is connected to known fraud rings – graph traversal
- Transactions that look like this one – vector similarity search
- Statistical baselines – aggregate analytics across millions of rows
That is five different data access patterns. In the polyglot persistence model, each one is often served by a different database. In practice, the first four are in the real-time hot path – the fraud decision blocks on them. Analytics provides pre-computed baselines and typically runs as a background aggregation, not an inline call. Here is what the real-time architecture looks like – four databases, four network hops, one fraud decision:
2. Counting the Cost
Concrete costs. Not hand-waving about “complexity” – actual failure modes you can measure.
2.1 Network latency
Each database hop adds network latency. Measure it yourself: a typical cross-service call within the same cloud region costs 1–5ms. If we chain four database calls sequentially (we cannot parallelize all of them – step 3 depends on the result of step 1), we are looking at 4 × 3ms = 12ms of pure network overhead. Our fraud check has a 100ms budget. We just spent 12% of it on plumbing.
But it gets worse. Each hop is also a failure mode. If any one of those five databases is slow or unreachable, the fraud check either blocks or returns incomplete data. A circuit breaker around each call helps, but you are now writing fallback logic for five external dependencies in what should be a single decision function.
2.2 Transactional guarantees
What happens if step 3 (graph insert) fails after step 2 (JSON insert) succeeds?
In a polyglot system, the answer is: you have inconsistent data. Your document store says the device fingerprint was logged. Your graph database has no edge for it. Your fraud model is now blind to that connection.
The usual fix is a saga pattern – compensating transactions, outbox tables, event sourcing with retry logic. Each of these is real engineering. And each one is a workaround for a problem that does not exist when all five operations share a single transaction log.
The issue is not that sagas are bad engineering. They are the correct solution for cross-service coordination. The issue is that we created the need for cross-service coordination by splitting data across services in the first place. That was a choice, not an inevitability.
2.3 Security surface area
Five databases means five authentication systems. In practice it usually looks like this:
| Database | Auth Mechanism | Row-Level Security | Audit Log |
|---|---|---|---|
| Relational DB | Roles + certificates | Yes | Yes |
| Document DB | SCRAM + field-level ACL | Partial | Yes |
| Graph DB | Native auth | Node-level | Partial |
| Vector DB | API keys | No | No |
| Analytics DW | Federated IAM | Yes | Yes |
When a SOC 2 auditor asks “show me a unified access log for all data access by user X over the past 90 days,” you need to pull logs from five systems, correlate timestamps, and explain five different permission models. I have watched this take an audit from two weeks to two months.
2.4 Operational overhead
Five backup schedules. Five monitoring dashboards. Five upgrade paths. Five sets of performance tuning knobs. Your DBA team does not scale linearly with database count, but the operational burden grows faster than linearly – closer to exponentially once you factor in cross-system interactions.
2.5 Developer cognitive load
Your engineers need to be conversant in five query languages, five data modeling paradigms, and five sets of operational quirks. Every new hire spends their first weeks understanding how data flows between systems before writing a single feature.
None of these costs are individually catastrophic. They compound. That is the tax.
3. What Would “Not Paying the Tax” Look Like?
If a single database engine could natively handle all five data access patterns – relational, document, graph, vector, and analytical – what exactly would we eliminate?
- The network hops between databases (latency and failure modes)
- The saga/outbox patterns for cross-model consistency (engineering effort)
- Four of the five auth systems (security surface area)
- Four of the five backup schedules, monitoring dashboards, upgrade paths (ops cost)
- The need to learn five query languages (cognitive load)
That is a significant reduction. The question is whether a single engine can actually deliver native-quality support for all five models, or whether it ends up being mediocre at everything.
This is where most “multi-model” databases fall short. They bolt features onto a single-purpose engine and call it multi-model. A relational database that can parse JSON strings is not the same as a database with a native JSON type. A database that exports to a graph visualization tool is not the same as one with native graph pattern matching.
4. Three Pillars
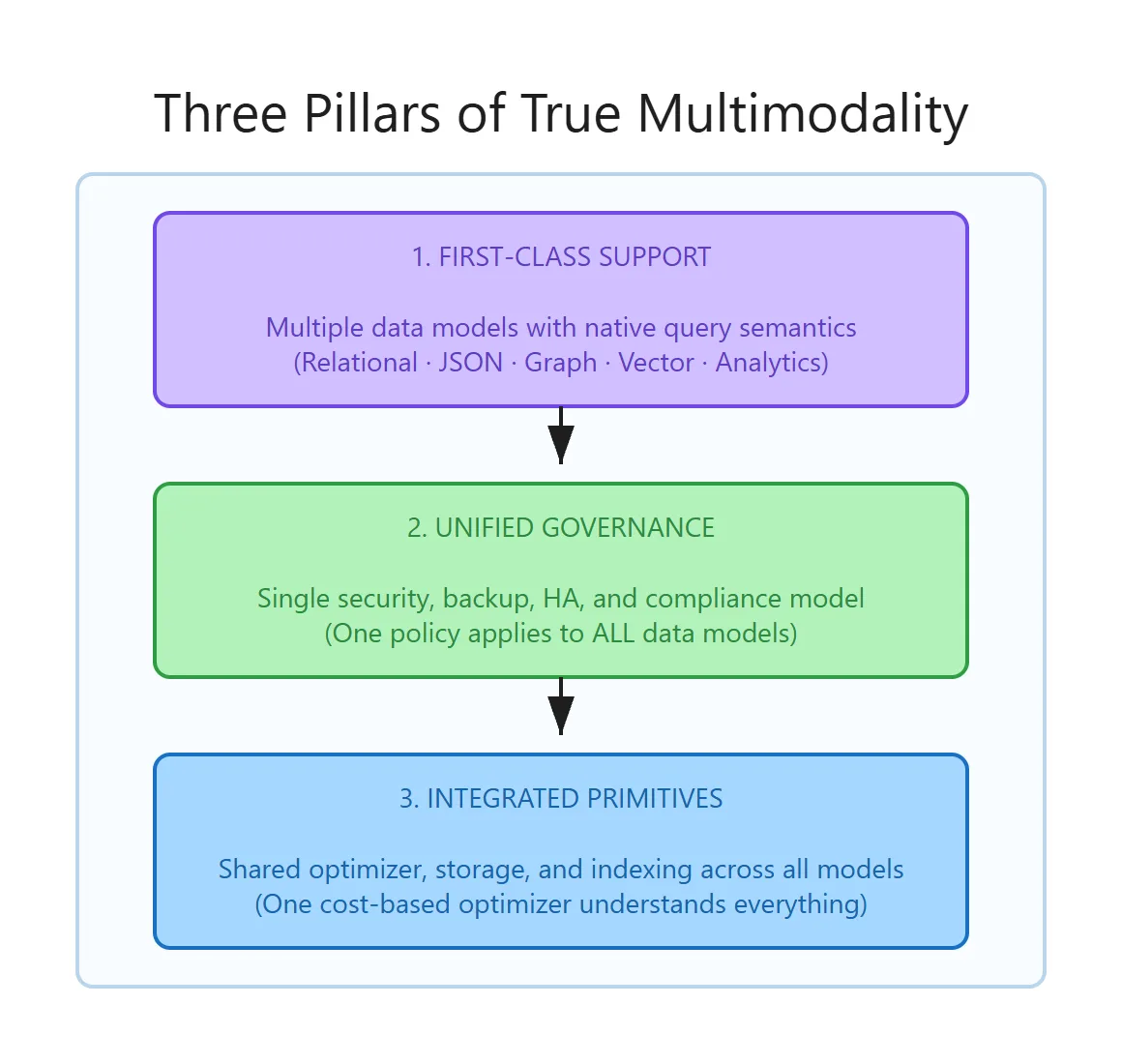
Three requirements separate genuine multi-model databases from trench-coat architectures (multiple engines hiding behind one API).
Pillar 1: First-class support for each data model. Each model gets native query semantics. Graph traversals should read like graph traversals. Vector search should use purpose-built index structures (like DiskANN), not brute-force scans. “We support JSON” should mean a native data type with validation.
Pillar 2: Unified governance. One security policy that applies across all data models. If I set row-level security on customer data, that policy filters results whether I am querying relationally, traversing the graph, or doing a vector similarity search. One backup captures all data models to a consistent point in time. One audit log records all access.
Pillar 3: Integrated performance primitives. This is the hard one. The query optimizer must understand all data models and make cost-based decisions across them. If I join a relational table with a JSON document collection and filter by a graph property, the optimizer should push predicates into all three access paths and produce a single execution plan – not three plans stitched together.
Why is Pillar 3 the hardest? Because it requires the engine to have been designed for multi-model workloads from the storage layer up. You cannot retrofit this. A query optimizer that does not understand the cost model of a DiskANN vector index cannot make intelligent decisions about when to use it versus a B-tree scan. It resorts to plan stitching – separate sub-plans for each model, glued together at a higher level. The performance difference is measurable.
5. Why Now?
We opened with the agent scenario – spin up a database, point an agent at it, build fast. Everything we have discussed since then (latency, consistency, security, cognitive load) applies to human teams too. But agents make the polyglot tax worse, because agents are bad at orchestration. Every additional tool call is an opportunity for the model to hallucinate, lose context, or retry in unexpected ways. And with MCP (Model Context Protocol) becoming the standard interface between agents and databases, the number of tool calls your architecture demands is now a first-class design constraint.
Consider the difference:
Polyglot agent workflow:
→ Call 1: RDBMS for profile (auth: service account A)
→ Call 2: Document DB for interactions (auth: API key B)
→ Call 3: Graph DB for connections (auth: token C)
→ Call 4: Vector DB for similar cases (auth: API key D)
→ Call 5: Analytics DW for trends (auth: service account E)
5 calls, 5 auth contexts, 5 failure modes, 200–500ms
Multi-model agent workflow:
→ Call 1: single stored procedure via MCP
1 call, 1 auth context, 1 failure mode, 10–50ms
Fewer tool calls means the agent is less likely to hallucinate or lose its thread. Consistent data from a single point-in-time query means no conflicting information. Sub-50ms latency means the agent feels responsive.
The database architecture you choose today determines how effective your agents can be tomorrow. We will dig into this in Part 4.
So What?
If you are running three or more databases to serve a single application, you are paying a tax. Not a one-time cost – a compounding one. Every new feature that touches multiple data models costs more to build, more to test, more to secure, and more to debug at 2 AM.
The polyglot architecture was the right answer ten years ago, when no single engine handled JSON, graph, vector, and analytical workloads at native quality. That assumption deserves re-examination.
MSSQL is not “relational with extras.” It is a multi-model engine – purpose-built storage formats, purpose-built index structures, and a single optimizer that makes cost-based decisions across all five data models. That is the claim. Over the next three posts, we prove it with real queries, real execution plans, and real performance numbers.
The question to take with you: Is your current architecture a deliberate design choice, or an inherited assumption that nobody has revisited?
What is Next
-
Part 3: Vectors, Analytics, and the End of ETL – Vector search with DiskANN, columnstore mechanics (why the 60x speedup is physics, not marketing), and HTAP queries on live data.
-
Part 4: One API, One Security Model, Zero Excuses – Row-level security across data models, Data API Builder for MCP/REST/GraphQL, a reference architecture, and how to start for free.
This is great -- very excited about the potential of SQL Server for this architecture. Like you point out, it has a lot of advantages. Some applications will still need specialized solutions for vector DBs, etc, but there are many applications that will have significantly simplified architectural and operational concerns with this approach.
Vector database conjoined with our other data in SQL Server is actually something I need to begin using in some of my applications, but vector indexes in SQL 2025 do not support data modification. When there is a vector index on a column on the table, the entire...
Hello Matthew
Happy to share that this limitation is actively being addressed, and support for data modification on tables with vector indexes is already well underway in SQL Server 2025/Azure SQL .This removes the “table lockdown” concern and enables more realistic, production‑grade workloads.
We’re currently validating this with few customers and partners, and we’re excited about how this unlocks the architecture you’re describing
If you’re interested in trying this out early or discussing your specific scenario, feel free to reach out to me directly at pookam@microsoft.com — we’d love to get your feedback.