
Improving OpenJDK Scalar Replacement – Part 2/3
In the previous part of this blog series, we explored the foundational concepts and purpose of scalar replacement (SR) in OpenJDK, laying the groundwork for understanding how this optimization can boost the performance of Java applications. Now, in the second installment of the series, we shift our focus to the specific enhancements that we have introduced to the SR implementation, highlighting how it lifts the constraints identified in the original SR implementation in the C2 compiler.
The Improvement
Listing 1 shows a version of the CompositeChecksum method that’s slightly different from the previous one. In this version, there is a check to see if the message that we obtained from the list is null or not. If it is null, it creates a message object with the Clear string as payload; otherwise, it just creates the message object using the msg payload. This is quite a simple piece of code and a somewhat common pattern to write, however before our work to improve C2 scalar replacement, C2 would not scalar replace the Message objects in cases like this.
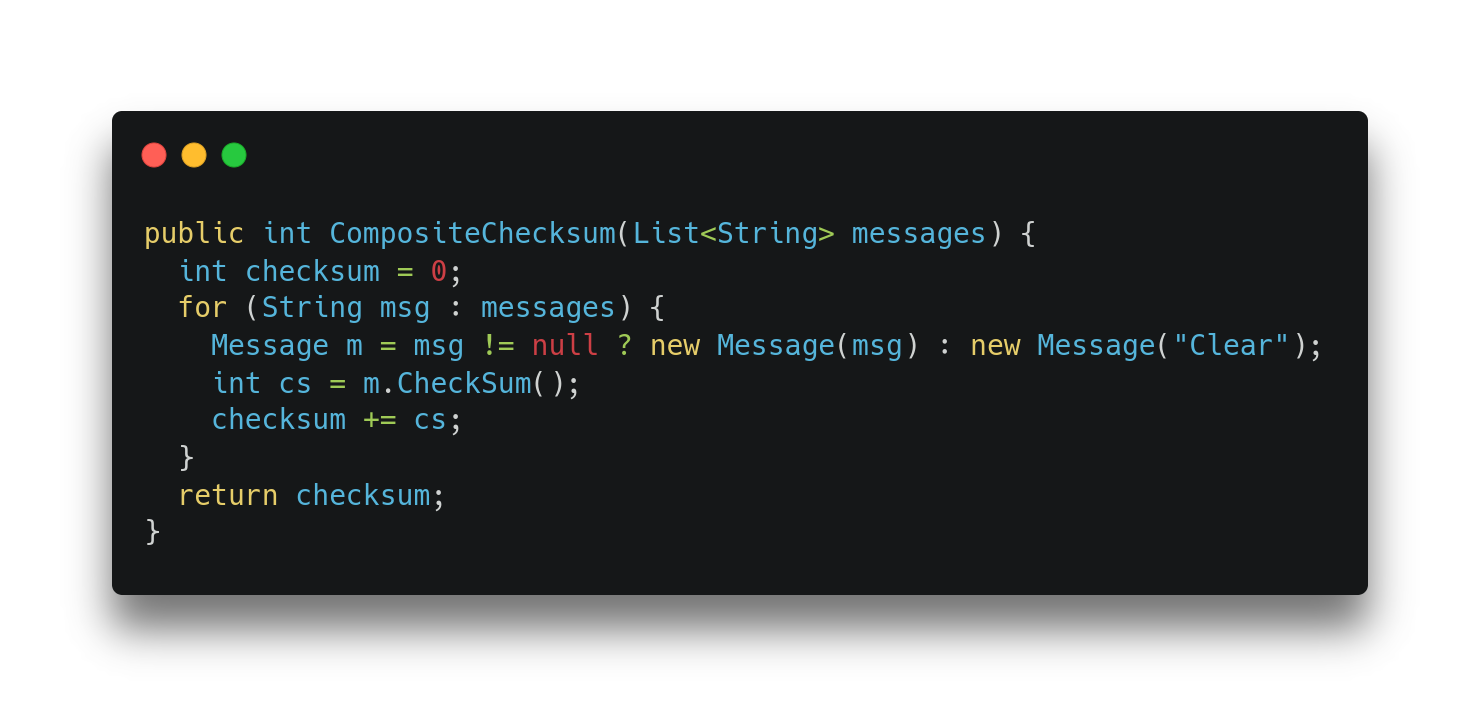
Listing 1: The CompositeChecksum control flow merge version.
To understand why this is a more complicated scenario for scalar replacing the objects, let us see how C2 represents the method shown in Listing 2, which is basically the first line of the loop in Listing 1. In the method two Message objects are allocated in different branches of an “if” but only a single field of one of the objects is later used.
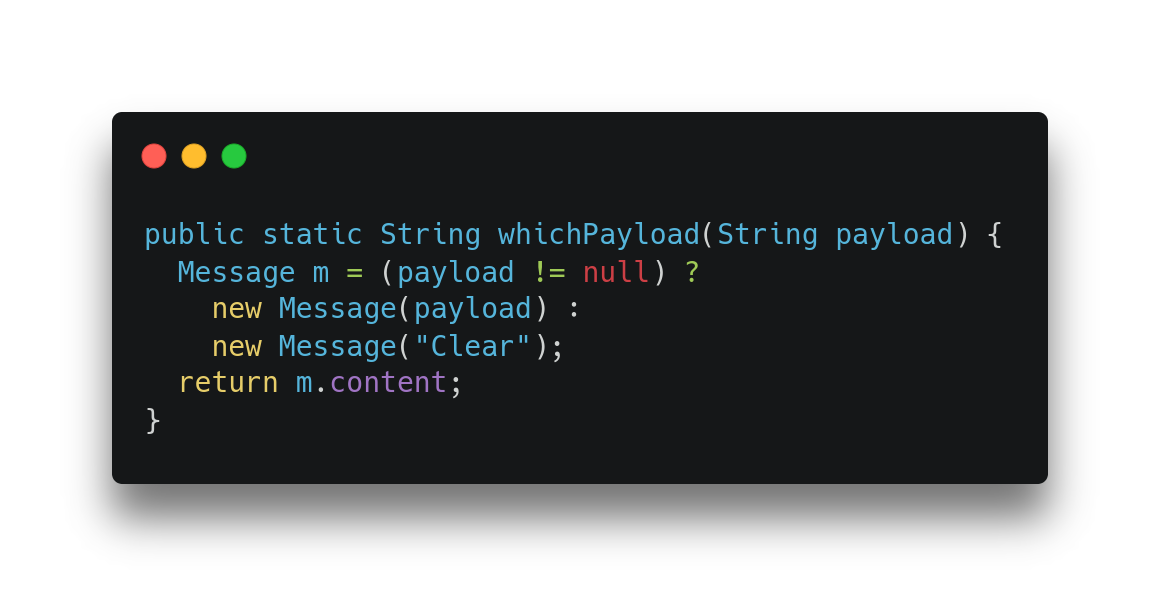
Listing 2: A simple method with an allocation merge.
From C2’s “perspective” there is more than one place (allocation site) where the object that m will eventually reference may be allocated. To be more precise, the variable m will reference the object allocated in the then block or the object allocated in the else block of the conditional. Note that this is a simple example where there are only two allocation sites; in practice, there may be many places where an object is assigned to the same reference. There are other cases where you would expect C2 to scalar replace objects, but it does not do so. However, the allocation merge issue was the most prominent at the time that we started our investigation. See this article where we discuss those cases: HotSpot Escape Analysis and Scalar Replacement Status.
A detailed explanation of why C2 was not scalar replacing objects in such a code pattern is a topic for a more technical compiler-related blog post. However, just to give an idea why this is a complicated piece of code to optimize, consider these points:
- There may be more than two allocation sites in the allocation merge.
- Some of the allocation sites may be an object being returned by another method.
- The allocation merge may be of Arrays, not of single dimensional (scalar) objects.
- An allocation site can simply be a null expression.
- Objects can also be used, including changed, by other methods before they are assigned to m.
- In more extreme cases the object may be stored in global variables and accessed by other threads before the assignment to m.
- During scalar replacement, the compiler must track the values of each field of each potential object. There may be many fields and some of these fields are other objects.
- The objects may be created from different classes.
- C2 will need to handle objects used in deoptimization points.
Another complicating factor is the approach used by C2 to represent the code of the method while compiling it. C2 uses a concept called sea-of-nodes to represent methods internally. That representation has a property called Static Single-Assignment (SSA) which basically means that every piece of data (variable, object, etc.) can only be created in one specific point in the method. One way of making sure that this property is maintained is by labelling every piece of data in the method with a version number. You can imagine a version as roughly the line number of where the data is created. If the data (variable, object, etc.) can be created in more than one place it will have different versions. At some points in the method, it will be necessary to “merge” the versions of the variables and to do that a thing called a Phi function or Phi node is used. When the compiler is parsing a method, and it notes that a variable can point to more than one version of data, it will insert a Phi node that will represent all data versions that the variable can point to.
Figure 1 shows a partial illustration of how C2 will represent the method shown in Listing 2. In this illustration rectangles and squares represent instructions in the compiler internal representation, while arrows connecting these instructions means that the target of the arrow uses data created by the source of the arrow. The two Allocate nodes represent instructions used to allocate memory regions for each of the two allocation sites in the method. The CheckCastPP nodes represent instructions to cast the pointers to the allocated memory regions to pointers to actual Message objects. Note that this is how the compiler represents the method, it does not mean that both object allocations will always happen – it only means that they can happen.
In our illustration C2 inserted the Phi node to represent the fact that the variable m can point to an object allocated in one of two different allocation sites. This Phi node is what we were referring to earlier as Allocation Merge. The Phi node itself is also versioned and so the instructions after it, in this case, refer to a single version. Just for completeness, the AddP instruction computes the address of a field of an object, the Load instruction fetches data from that field, and the Return instruction represents returning some data to the caller of the method.
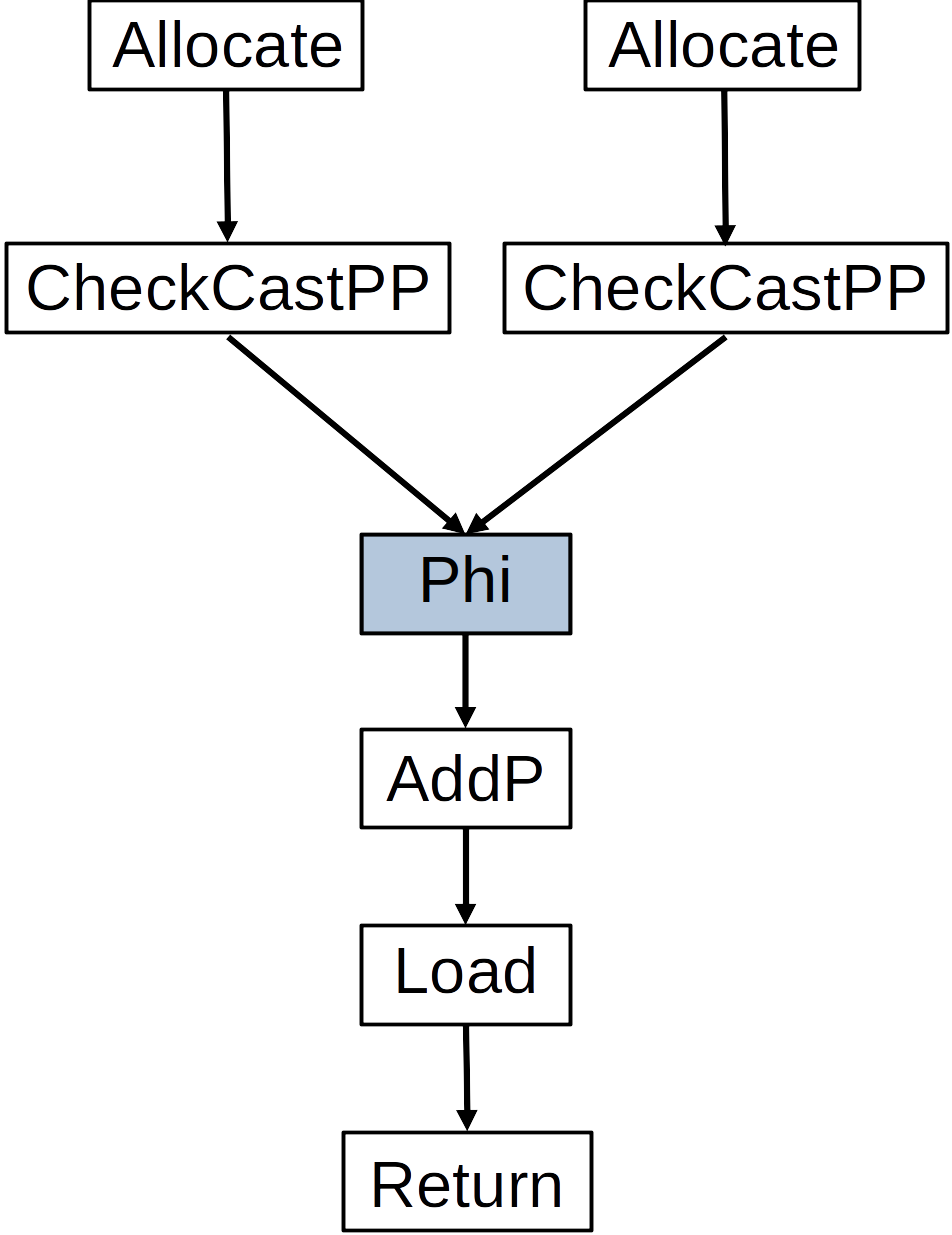
Figure 1: How C2 internally represents part of the whichPayload method.
Scalar replacement, however, needs to know exactly which object is being used at every point where it needs to patch the code. If there is ambiguity, or a Phi node is present, that involves the object that we want to scalar replace then we need to use a more complex algorithm to decide which object it should use and moreover to patch the code of the method.
We tried different approaches but, in the end, it turns out that the most obvious solution was the easiest one to implement and the one that performed better in the benchmarks. The idea is very simple: instead of using the conditional to only decide which object we should load the field from, we replicate the field load itself inside the branches of the conditional so that every branch has a field load and then the Phi node is used to represent that we can use either of the field loads, not either of the objects.
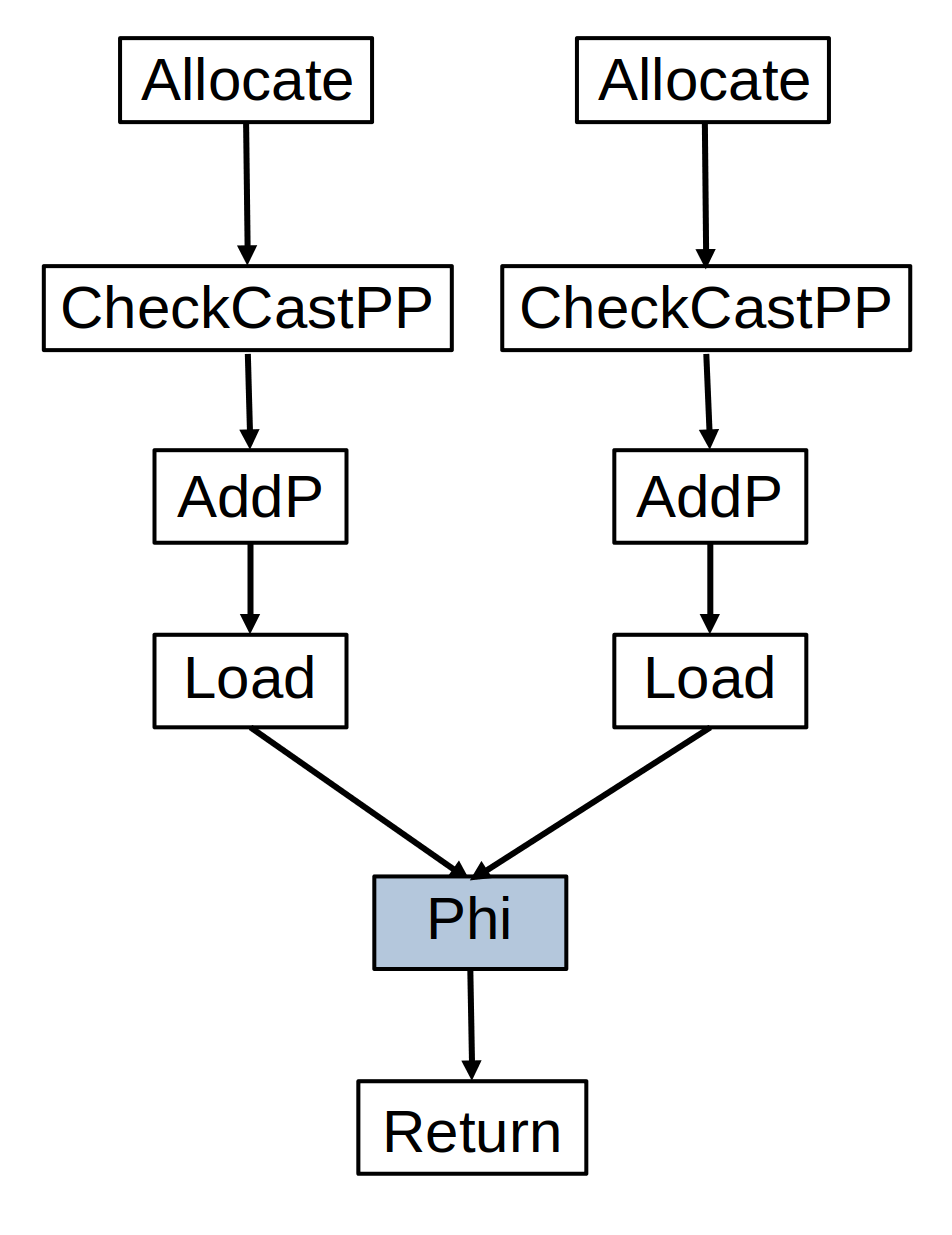
Figure 2: How we solved the allocation merge problem.
Figure 2 shows an illustration of what I am referring to and Listing 3 shows the Java version of it. Note that there are 2 field loads, one for each object, and the Phi node now uses the values loaded from each of the objects. So now what we are doing is using the Phi node to decide which of the loaded values we should return, not which of the objects we should load the field from. After that transformation, the earlier scalar replacement logic in C2 can scalar replace both objects represented at the top because the objects themselves are not used by Phi nodes. Listing 4 shows the code after scalar replacement and after other optimizations kick in to just simplify the code.
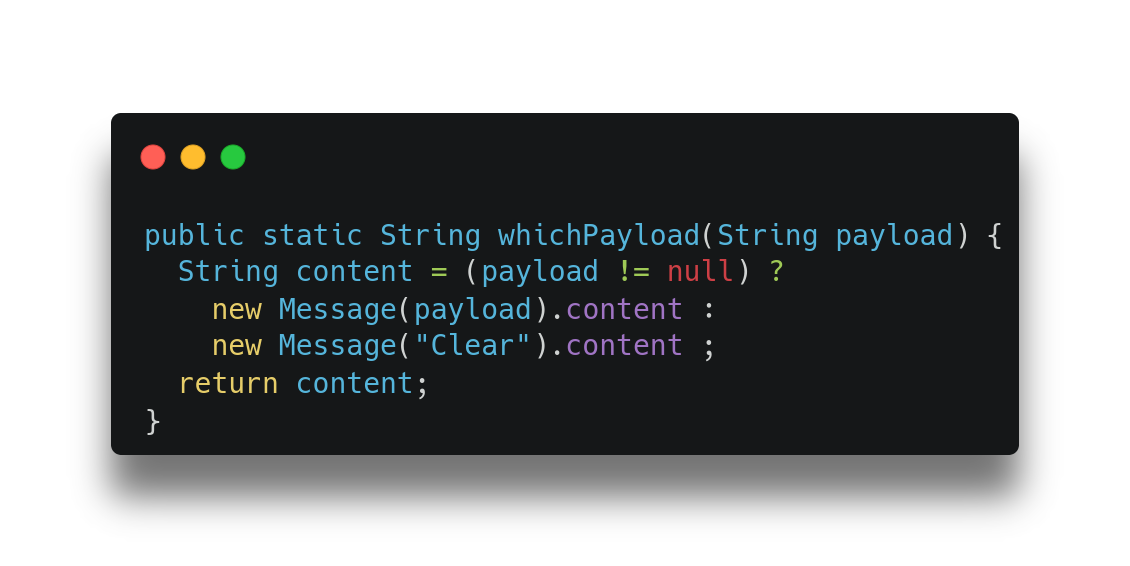
Listing 3: Merging field loads instead of objects.
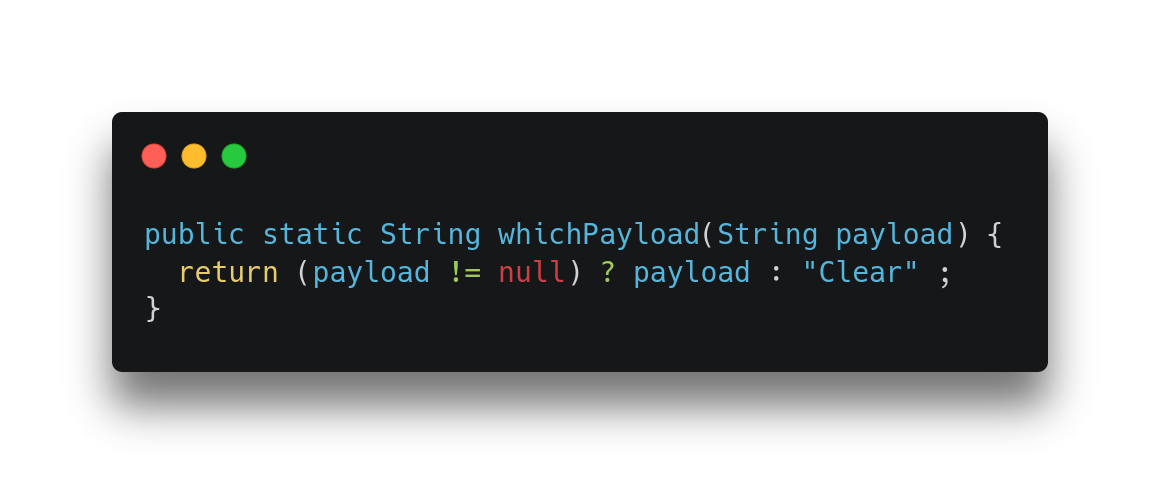 Listing 4: After scalar replacing untangled allocation merges.
Listing 4: After scalar replacing untangled allocation merges.
As I mentioned earlier, the idea was simple. However, as expected the implementation was the most difficult part. I showed just the overall idea that we used to solve the problem and the simplest cases where objects are used only to load a single field. In practice there are many more different use cases that we need to handle. The most obvious one is when you are loading several fields from the objects or storing values on these fields, as well as a mix of these operations. Other use cases, like the objects being used as a Monitor, also must be considered. Not only was the way that the objects are being used a challenge but getting the representation of the method updated correctly was particularly challenging. In practice these representations can have thousands of nodes. It is also necessary to cooperate with other optimizations that change the representation before and after scalar replacement.
Two other big challenges were the handling of the optimizations, like what happens when compiled code is executing and something happens that needs to cause the execution of the method to go to the interpreter. That was something that needed a lot of work and we had to do it before everything else that we worked on. The other major challenge was updating and/or traversing the memory graph. By that I mean which value I should use when I scalar replace an object in the example that I showed earlier – the field loads and the use of the data were very close, but in a bigger method these things can be very far apart so you need to traverse the graph and find the right node that has the correct value that you should use for the field. Of course, we should not break any of the existing code, especially not the existing scalar replacement code.
How to Give it a Try
These improvements are enabled by default in OpenJDK Tip and Microsoft Build of OpenJDK versions 11, 17 and 21. To use them, download our JDK and launch your application as you normally would! If you want to disable the optimization, let’s say for benchmarking purposes, or because you found an issue, you can do so by adding these options to the JVM launch configuration: -XX:+UnlockDiagnosticVMOptions –XX:-ReduceAllocationMerges.
Conclusion
In summary, by transforming object allocation merges into merges of object fields, we make it possible for the C2 compiler to scalar replace the objects and also perform additional optimizations to the code. These enhancements make applications run smoother and faster, using resources more effectively. In the final part of this series, we’ll share the results of our work and how these changes positively impact application performance.
 Light
Light Dark
Dark
0 comments