
How to skip the beginning and ending of a file by using PowerShell
Summary: Learn how to skip the beginning and ending portions of a text file by using Windows PowerShell in this article by the Microsoft Scripting Guy Ed Wilson.
This is the second post in a multi-part series of blog posts that deal with how to determine letter frequency in text files. To fully understand this post, you should read the entire series in order.
Here are the posts in the series:
- Letter frequency analysis of text by using PowerShell
- How to skip the beginning and ending of a file by using PowerShell
- Read a text file and do frequency analysis by using PowerShell
- Compare the letter frequency of two text files by using PowerShell
- Calculate percentage character frequencies from a text file by using PowerShell
- Additional resources for text analysis by using PowerShell
Good morning, Microsoft Scripting Guy Ed Wilson is here. At this very moment, the Scripting Wife (PowerShell MVP Teresa Wilson) and I are heading back to Central Florida after an absolutely incredible week in Seattle. I am not exaggerating at all. It has been one of the best weeks in my life. First of all, we got to see lots of our friends in the PowerShell community that we have not seen in a long time. Luminaries such as Richard Siddaway, Don Jones, Kirk Munroe and others. It has been a long time since I have been able to fly and as a result some of these peeps I have not seen for several years. Also, while we were out there, my good friend Microsoft PFE Ashley McGlone arranged to record an Microsoft Virtual Academy on Windows PowerShell 5.0 – that was lots of fun. And finally, but certainly, I finally got a chance to meet my Microsoft Operations Management Suite team mates (including the awesome new Scripting Manager Jeremy Winter) in person, in real life. After spending two days on campus with my team, I was bursting at the seams with excitement. These Microsoftees are incredible. So, yeah, it has been an awesome week. We are at around 35,000 feet or so, and from the window it looks like we must be flying over Kansas or something because everything looks like really flat. I am listening to Stan Kenton on my Zune (yeah, the original one … it still works). And so, life is good. Sorry for the long introduction. But Dude! Or Dudette!!
Use Get-Content to parse a file …
So probably everyone who reads the Hey Scripting Guy blog on a regular basis, knows that I can use Get-Content to read the contents of a text file. But not everyone knows that when I read a text file this way, I end up with basically an array of text strings. I can use this to help me easily remove portions of the file.
So, the other day, I was doing frequency analysis of a text file to find out which letters occurred the most often. It was just a little off because I included the standard starting stuff and license stuff from the Project Gutenberg files. Now, I need to keep these things intact for license purposes, but for textual analysis I may want a good way to remove that content in memory.
So, without getting all hairy with regular expressions, I wanted an easy way to remove the stuff. I decided to use a couple of if statements to do this. So here are my steps as an overview:
- Read the contents of the file
- Create an empty array
- Use for to walk through the text line by line
- Us if to look for certain phrases
- If I get a hit on the phrase, then I want to add the line number to my array
- Use basic array notation to get my start and stop points (line numbers)
- Then index into the array of text and pull out everything between my start and stop positions
There are quite a few steps here, but there are only 12 lines of text for my script.
Read the file and create an empty array
The first two lines of my script read the text file and then create an empty array. The Get-Content cmdlet reads the contents of my text file (in this case Moby Dick by Herman Melville). I store the contents into a variable just named $a. Next I create an empty array that I will use for storing the line numbers where I find the start and ending portions of my text file. The array is simply called $array. These two lines of code appear here:
$a= Get-Content ‘C:\fso\MobyDick.txt’
$array = @()
Walk through the text file and look for stuff
I want to find the line number that begins the text I want to capture. So, I looked at the text file to see if there were any indicators. I came across the following *** START. That looks like a pretty good indicator, and appears here:
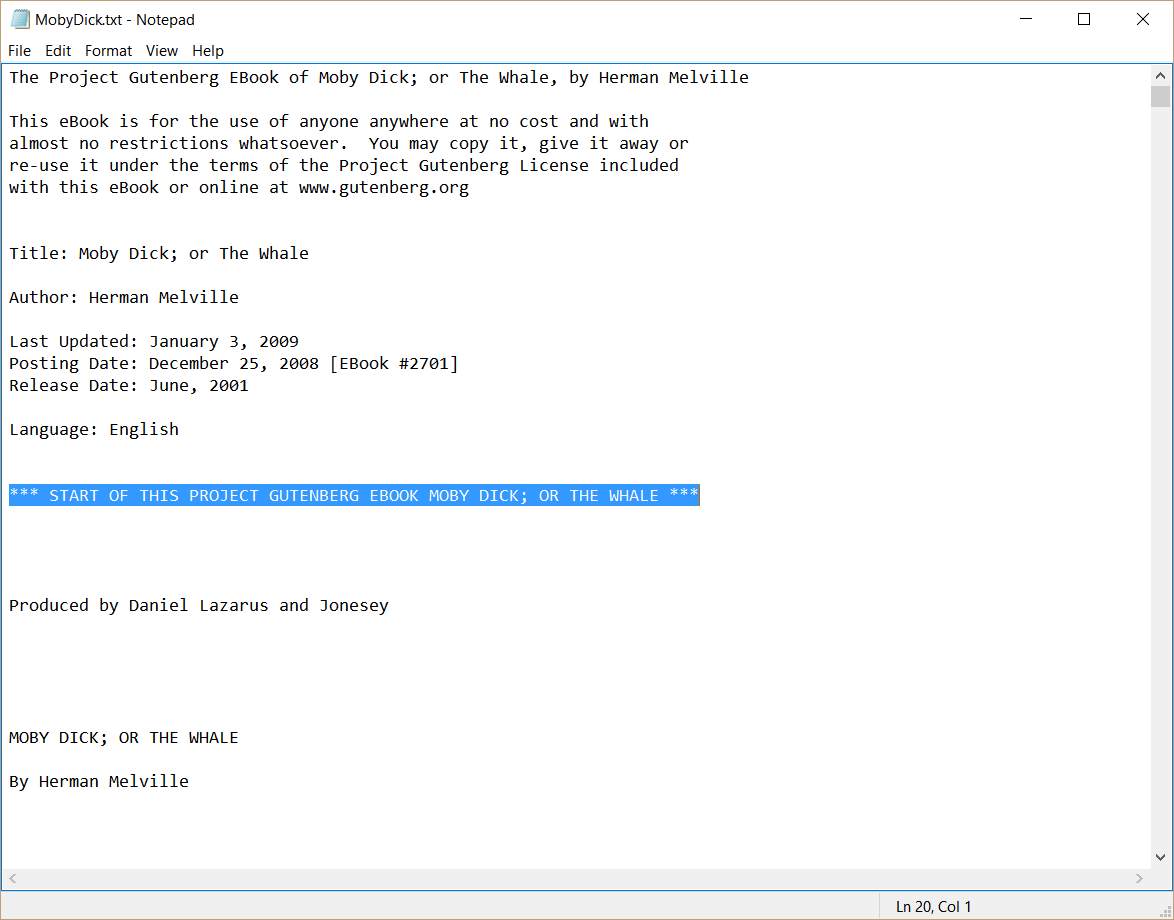
So, I begin walking through the array of text that returns when I use Get-Content. To walk through the array I use For and I begin at 0 and work my up. Inside the script block for For I use the If statement to search each line for a case sensitive match with START. If I find it, I write my current line number into the $array.
Next, I look for something that looks like “End of *Project*”. I need to use the wild cards because some file have End of the project … and others End of project … and so I wanted to capture both. Likewise I add in the line number for the matching string. That is the big decision making portion, and it appears here:
for ($i = 0; $i -lt $a.Count; $i++)
{
If ($a[$i] -cmatch ‘START’)
{$array +=$i }
If ($a[$i] -like “End of *Project*”)
{$array += $i }
}
Get my start and stop portions and grab the text
I know that the first match will be START and the second match will be End Of *project, from looking at the format of my text files. I also know there will be an additional START match, but it appears to be the third match. So, I only use the first and second elements from my array.
Now, I want to add a few lines to get rid of the project editor that appears in some files. So I simply add 7 extra lines to the matched location. This appears here:
$start = $array[0] +7
Next, I subtract one from the End of *Project* match because I do not want that matched line in my text that I copy. This appears here:
$end = $array[1] -1
Now, I simply index into the text file I have stored in the $a variable, and I grab everything from start to end. This appears here:
$a[$start .. $end]
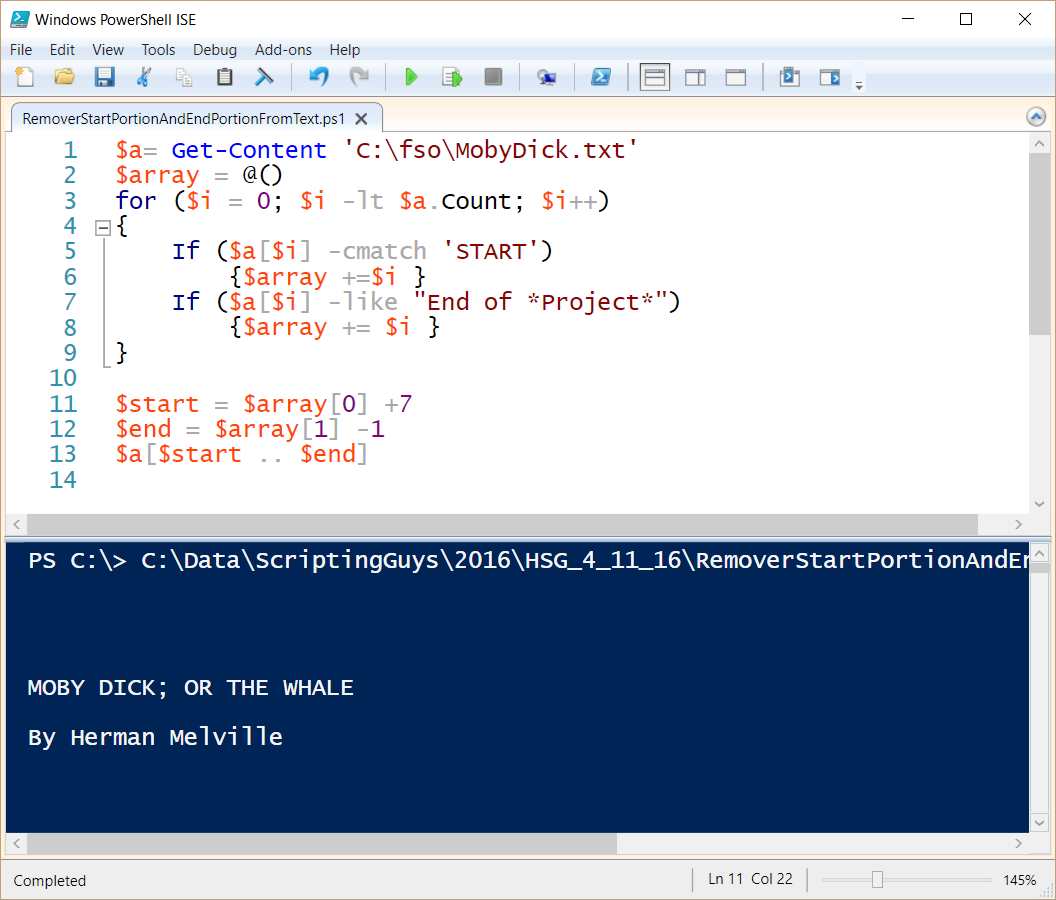
The complete script appears here:
$a= Get-Content ‘C:\fso\MobyDick.txt’
$array = @()
for ($i = 0; $i -lt $a.Count; $i++)
{
If ($a[$i] -cmatch ‘START’)
{$array +=$i }
If ($a[$i] -like “End of *Project*”)
{$array += $i }
}
$start = $array[0] +7
$end = $array[1] -1
$a[$start .. $end]
The script and output appear here:
I invite you to follow me on Twitter and Facebook. If you have any questions, send email to me at scripter@microsoft.com, or post your questions on the Official Scripting Guys Forum. Also check out my Microsoft Operations Management Suite Blog. See you tomorrow. Until then, peace.
Ed Wilson, Microsoft Scripting Guy
 Light
Light Dark
Dark
0 comments