
Synchronizing Azure Cosmos DB Collections for Blazing Fast Queries
App Dev Manager John Abele spotlights how materialized views and the right partition key strategy can make a huge difference in your Cosmos DB query performance.
Azure Cosmos DB is the fastest growing data service in Azure – and for good reason. The service offers global distribution in a few clicks, seamless horizontal scaling, automatic indexing, and 99.99% guarantees for availability, throughput, latency, and consistency. Enabling Cosmos DB multi-master mode provides a service-level agreement backed read and write availability of 99.999% – financially backed by Microsoft.
While Cosmos DB offloads many of the hard NoSQL scaling problems, shaping your data and choosing a logical partition key are left to you. The partition key choice is arguably the most important decision you’ll need to make – it must be determined upon creation of a collection and cannot be changed once created.
Among the best practices for choosing a partition key, it is often recommended to choose a value which appears frequently as a filter in your queries. This is because of the inherent speed and lower cost of constructing single-partition queries.
Take a look at this list which organizes query performance from fastest/most efficient to slowest/least efficient:
- GET on a single document (< 1ms)
- Single-partition query
- Cross-partition query (< 10ms)
- Scan query (query without filters)
Cosmos DB offers guaranteed <10ms read and write availability at the 99th percentile anywhere in the world – making it ideal for highly responsive and mission critical applications. That said, optimizing your partitioning strategy around single-partition queries significantly improves query performance and reduce RU/s (request unit per second) consumption. Let’s look at how to maximize read-optimization around multiple query filters while avoiding fan-out queries.
Assume we have a concert and events application which tracks tours, artists, dates, locations, ticket information, etc. For simplicity, let’s assume we are working with the following document:
{
"eventId":"1756307",
"type" : "Concert",
"performers" : [{
"performerId" : "22047",
"performerName" : "The Contosos"
},{
"performerId" : "19118",
"performerName" : "Fabrikams"
}],
"eventName" : "The Final Countdown",
"description" : "We're excited to announce the reunion of the Fabrikams and Contosos!",
"startdate":"1540320148",
"enddate":"1540320148",
"location" : {
"locationId" : "112",
"streetAddress" : "100 Main St."
"locality" : "Seattle",
"region" : "WA",
"postalCode" : "98101"
}
…
}
In order to avoid hot partitions and any future storage issues, we might partition on eventId or a location key since they have high cardinality. Doing so might cause our partitioning to look like this:
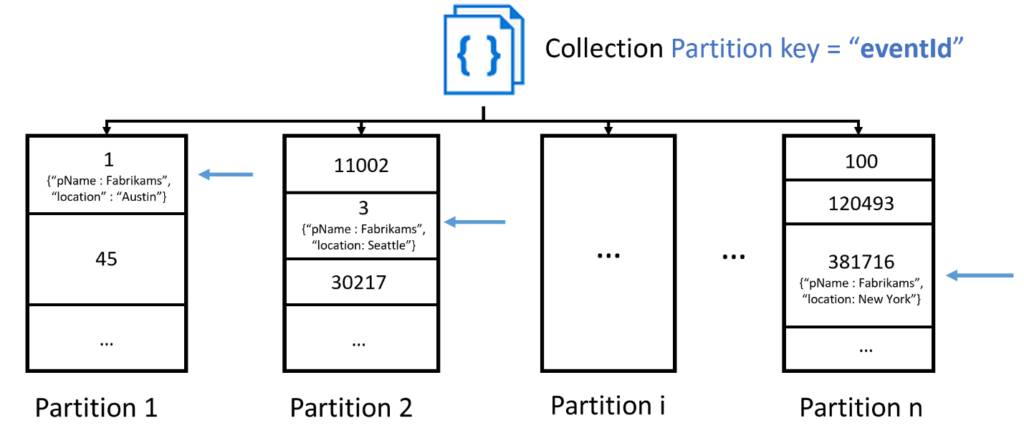
While this partition key choice checks most of the best practices boxes, we can expect users of our app to want to query by performer name, find events by city or by date – resulting in cross-partition or fan-out query. In practice, we shouldn’t expect to eliminate all fan-out queries, but if we have a read-intensive, latency sensitive workload we can optimize around multiple pivots using the Azure Cosmos DB Change Feed. The change feed supports the following scenarios:
- Triggering a notification or a call to an API, when an item is inserted or updated.
- Real-time stream processing for IoT or real-time analytics processing on operational data.
- Additional data movement by either synchronizing with a cache or a search engine or a data warehouse or archiving data to cold storage.
The Change Feed works by monitoring an Azure Cosmos DB collection for any changes (inserts and updates only). It then creates a sorted list of documents in the order in which they were modified. These changes are persisted and can be distributed across one or more consumers for parallel processing.
For our purposes, we will use the change feed and an Azure Function to implement a materialized view pattern to synchronize a secondary collection with a different partition key, such as performerName. Creating a materialized view will support efficient querying when the original data isn’t ideally formatted for additional required query operations, increasing overall performance.
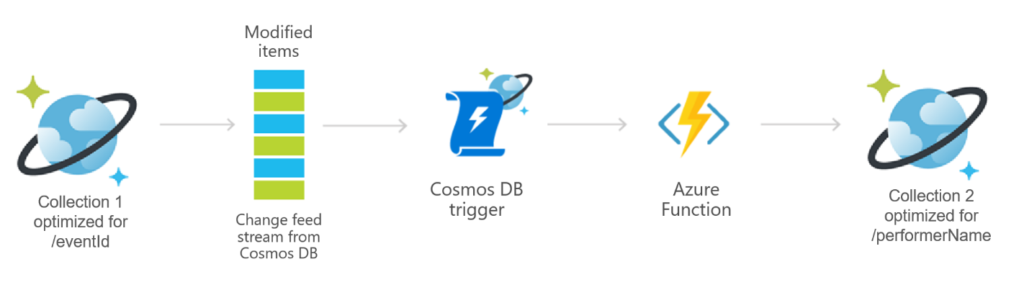
This setup very simple to configure within an Azure Function by using the Azure Cosmos DB Trigger template. Once you specify account and collection details, this will automatically run the function’s code whenever documents change in a collection.
Finally, by adding the following code to our function, we can write documents to the secondary collection:
#r "Microsoft.Azure.DocumentDB.Core"
using System;
using System.Collections.Generic;
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
//Get Account URI and Primary Key from the Keys menu inside your Cosmos Account.
static System.Uri uri = new System.Uri(Environment.GetEnvironmentVariable("CosmosDBAccountURI"));
static DocumentClient client = new DocumentClient(uri,Environment.GetEnvironmentVariable("CosmosDBAccountKey"));
public static void Run(IReadOnlyList<Document> changes, ILogger log)
{
if (changes != null && changes.Count > 0){
foreach(var doc in changes)
{
client.UpsertDocumentAsync("/dbs/SyncDatabase/colls/DestinationCollection", doc);
}
log.LogInformation("Documents added or modified: " + changes.Count);
}
}
That’s it! Once the function is created, future writes will be automatically synchronized across the collections. In addition to achieving the best possible performance with single-partition queries across multiple pivots, this configuration also allows you to manage RU/s with more granularity, since throughput is provisioned on each collection.
 Light
Light Dark
Dark
0 comments