
Postmortem – Intermittent Failures for Visual Studio Team Services on 14 Dec 2017
On 14 December 2017 we began to have a series of incidents with Visual Studio Team Services (VSTS) for several days that had a serious impact on the availability of our service for many customers (incident blogs #1 #2 #3). We apologize for the disruption these incidents had on you and your team. Below we describe the cause and the actions we are taking to address the issues which caused these incidents.
Customer Impact
The issues caused intermittent failures across multiple instances of the VSTS service within certain US and Brazilian data centers. During this time, we experienced failures within our application which caused IIS restarts resulting in customer impact for various VSTS scenarios.
The incidents started on 14 December. The graph below shows periods of customer impact for the Central US (CUS) and South Brazil (SBR) scale units.
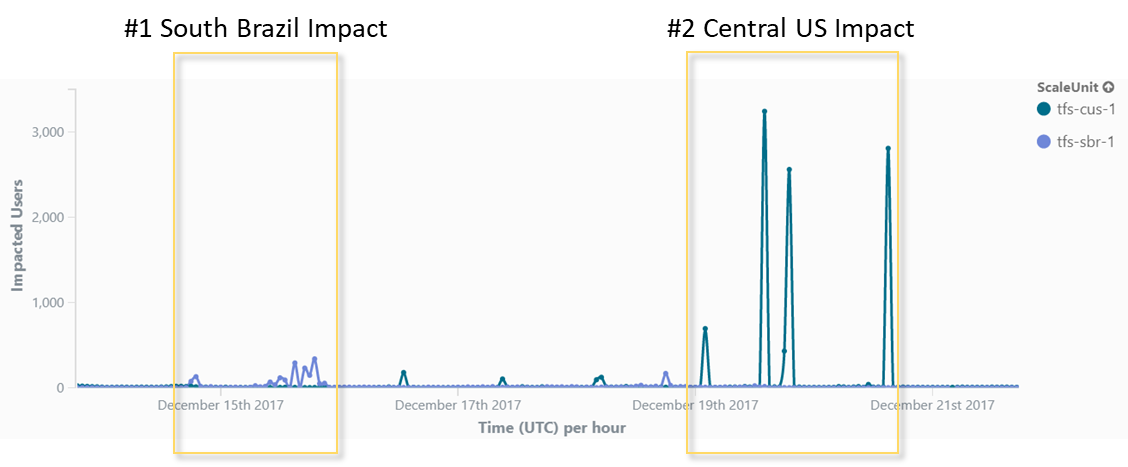
What Happened
For context VSTS uses DNS to route traffic to the correct scale unit. When accounts are created, VSTS queues a job to create a DNS record for {account}.visualstudio.com which points to the right scale unit. Because there is a delay between the DNS entry being added and it being used, we use Application Request Routing (ARR) to re-route requests to the right scale unit until the DNS update is complete. Additionally, VSTS uses web sockets to provide real time updates in the browser for pull requests and builds via SignalR.
The application pools (w3wp process) for the Brazil and Central US VSTS scale units began crashing intermittently on 14 December. IIS restarted the application pools on failure, but all existing connections were terminated. Analysis of the dumps revealed that a certain call pattern triggered the crash.
The request characteristics common to each crash were the following.
- The request was a web socket request.
- The request was proxied using ARR.
The issue took a while to track down because we suspected recent changes to the code that uses SignalR. However, the root cause was that on 14 December we released a fix to an unrelated issue which added code to use the ASP.Net PreSendRequestHeaders event. Using this event in combination with web sockets and ARR caused an AccessViolationException which terminated the process. We spoke with the ASP.Net team and they informed us that the PreSendRequestHeaders method is unreliable and we should replace it with HttpResponse.AddOnSendingHeaders instead. We have released a fix with that change.
While debugging the issue, we mitigated customer impact by redirecting ARR traffic once we realized that was the key cause.
Here is a timeline of the incident.
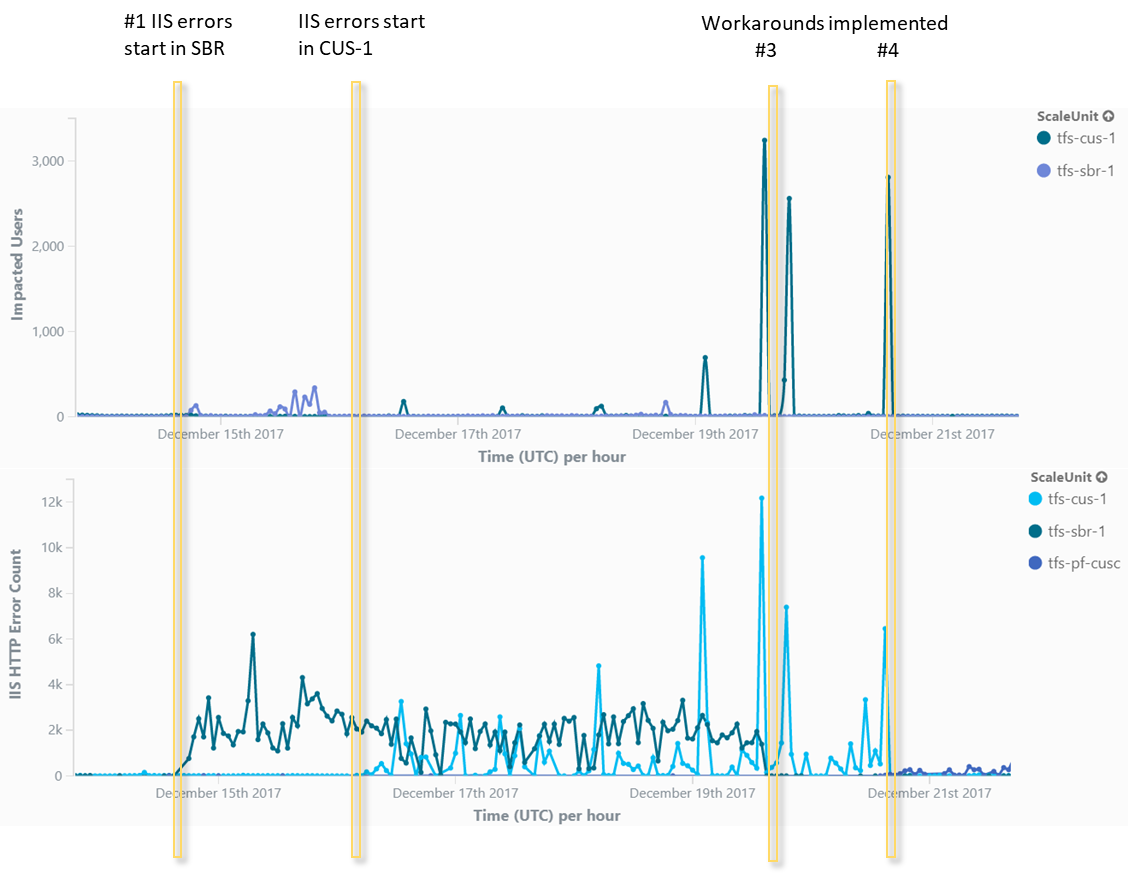
- IIS errors start in SBR (Brazil South)
- IIS errors start in CUS1 (US Central)
- Workaround – stopped ARR traffic from going to SBR.
- Workaround – Redirected *.visualstudio.com wildcard from CUS1 to pre-flight (an internal instance).
Next Steps
In order to prevent this issue in the future, we are taking the following actions.
- We have added monitoring and alerting specifically for w3wp crashes.
- We are working with the ASP.NET team to document or deprecate the PreSendRequestHeaders method. This page has been updated, and we are working to get the others updated.
- We are adding more detailed markers to our telemetry to make it easier to identify which build a given scale unit is on at any point in time to help correlate errors with the builds that introduced them.
Sincerely, Buck Hodges Director of Engineering, VSTS
 Light
Light Dark
Dark