
Re-Simulation in Automated Driving
Abstract
Autonomous Driving is a competitive market with complex security and processing challenges. This article highlights how a Microsoft CSE dev crew approached the concerns and constraints when developing a cloud-based Autonomous Driving re-simulation solution.

Background
Once considered a dream, self-driving cars are nearing reality. Today, multiple companies compete to gain an advantage in this billion-dollar market known as Autonomous Driving. Microsoft is working with the world’s largest car manufacturers to advance Automated Driving (AD).
Over a several year period, Microsoft worked with them to create a re-simulation solution, integrated with a larger autonomous development platform.
What is Re-Simulation
Re-Simulation (Re-Sim) fundamentally is a tool which combines three things to virtually replay and evaluate a dataset recorded from a drive:
- Vehicle sensor data
- Processing Objects (POs)
- Virtual environment
Re-Sim is massively complex and has required years of development. Seeking government approval of AD raises strict requirements in areas such as safety, data privacy, data versioning, and auditing.
It can be considered an open loop test and validation system for AD functions. It processes recorded raw data from various car sensors through a graph of POs in the cloud. The produced result can then be used to validate data processing algorithms or detect regressions. The POs are a definition of what needs to be executed, provided by the suppliers of the different vehicle sensors. The OEMs combine the sensors together into a Directed acyclic graph that represents the real-world vehicle.
This article is a primer of the fundamental challenges and approaches used to create Re-Sim.
Challenges
Amount of recorded data
At the beginning of a production cycle, vast quantities of data are collected from car sensors across a fleet of multiple vehicles. One car can produce up to 40TB of data per day. As a result, transferring this amount of data could cause an I/O bottleneck, and incur significant costs. The system needs to avoid copying these enormous amounts of data between different components of the system.
Data locality
The data is recorded in a specific region, and government mandates have strict requirements on where distinct types of data must be stored or processed. For example, data must be stored and remain in the region/geography where it was collected from the test fleet’s car loggers (in this case an Azure region and geography). Any Re-Sim solution needs to have multi-region compute capabilities and must provide the ability to process the data in the region where it was originally recorded. If not following the data locality constraints, approval for Automated Driving would not pass.
Processing time
Any solution needs to consider the long-lived nature of a re-simulation job. Depending on the PO requirements, the time it takes to process 1h of recorded data is variable per PO. A complex graph with a lot of recording hours could take weeks to complete.
Additionally, it is sometimes necessary to re-process a single PO within a whole graph. In this case, the system must avoid re-processing the whole graph due to the amount of time it takes and cost it generates. It should only process the data and POs that have been changed or added.
Optimized Compute per PO
Each PO has specific compute and operating system requirements. Some POs might require a single core on a budget VM, while others require 8 cores on a high memory VM. Picking correctly sized VMs will keep the cost low, while picking the wrong sized VMs (either too small or too large) will increase costs and may be less efficient. It is key to tune the system for optimal use of the resources allocated.
Complexity of the sensor graphs
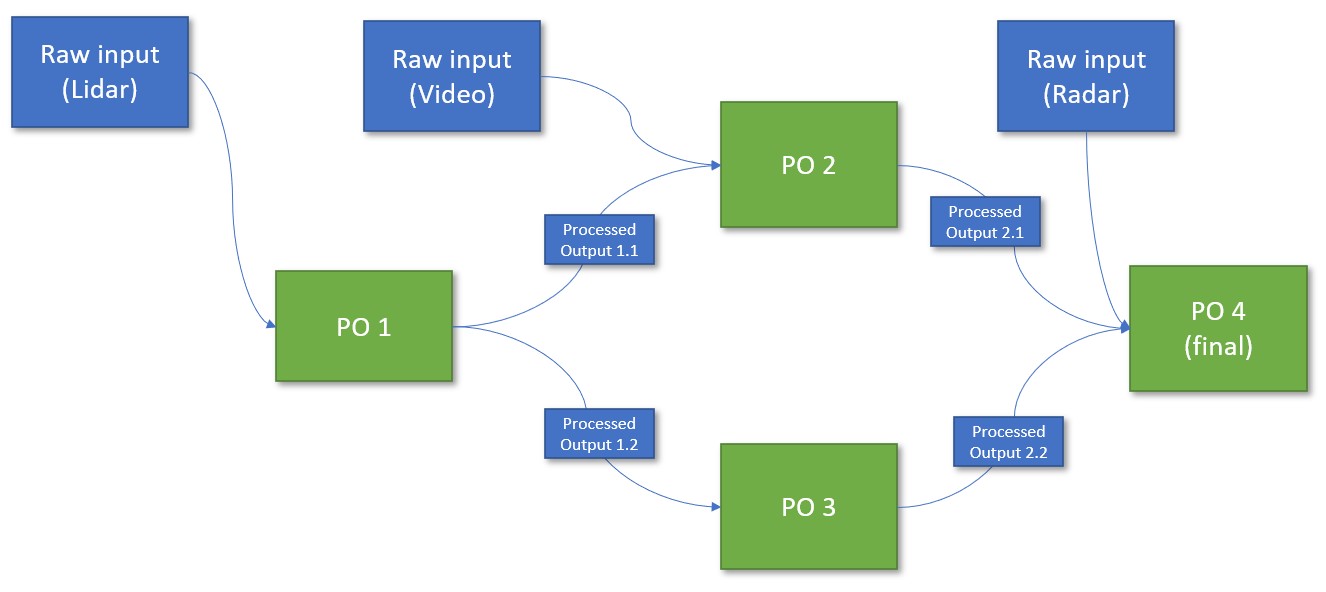 The sensor graphs within a vehicle can become quite complex. The example here displays a graph of four different POs, where each PO relies on different input, either raw or processed. In reality, the graphs can become more complex and need to be managed dynamically. A typical graph consists of 5 to 10 POs.
The sensor graphs within a vehicle can become quite complex. The example here displays a graph of four different POs, where each PO relies on different input, either raw or processed. In reality, the graphs can become more complex and need to be managed dynamically. A typical graph consists of 5 to 10 POs.
Solution
At run-time, the backend uses an embarrassingly parallel architecture to efficiently feed the recorded data through each node in the Re-Sim graph. The orchestration system is built on Azure Batch and Azure Durable Functions, allowing the PO suppliers full control over the virtual machine images running their software. A reliable and resilient control loop orchestrates multiple jobs in various states and ensures that individual failures do not affect other tasks or jobs.
Key parts of the system
- Data Locality: compute is brought to the region where the data is stored, by deploying Azure Batch accounts in the required region, to ensure data never moves regions. Additionally, uploaded software packages (PO dependencies) are replicated across regions to enable faster transfer of PO executables.
- Stable and reliable: the orchestration logic is built upon Azure Durable Functions and ensures jobs can be started, canceled, aborted, and retried in a reliable way. The metadata for re-simulation jobs is stored in Azure Cosmos DB, and an optimized state cache is maintained in Azure Storage.
- No inter-node communication: the current solution uses an embarrassingly parallel execution approach with intrinsically parallel workloads. This allows greater scalability while reducing the overall system complexity. We preferred parallel execution over an alternative of tightly-coupled, overly-complicated and error-prone VM orchestration. See this article on running parallel workloads on Batch for more information about intrinsically parallel vs. tightly coupled workloads.
- Smart Storage: to avoid processing bottlenecks, Re-Sim was designed to process just the modified or impacted POs as part of evaluating the graph. The results are smartly cached and re-used, enabling huge cost savings when re-running a graph where only one sensor or a subset of the data changed.
- Secure: a specific Token Store application was developed to manage encrypted On-Behalf-Of identity tokens during long-running jobs. This application leverages Azure Active Directory as well as Azure Key Vault to ensure a secure and traceable workflow. Both the web-based user interface as well as the APIs are exposed via Azure Application Gateway, and all backend services are fully private using Azure’s Private Endpoint capabilities.
- Supplier Controlled Environment:
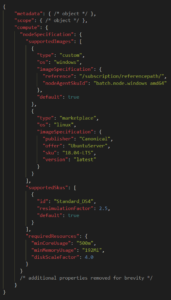
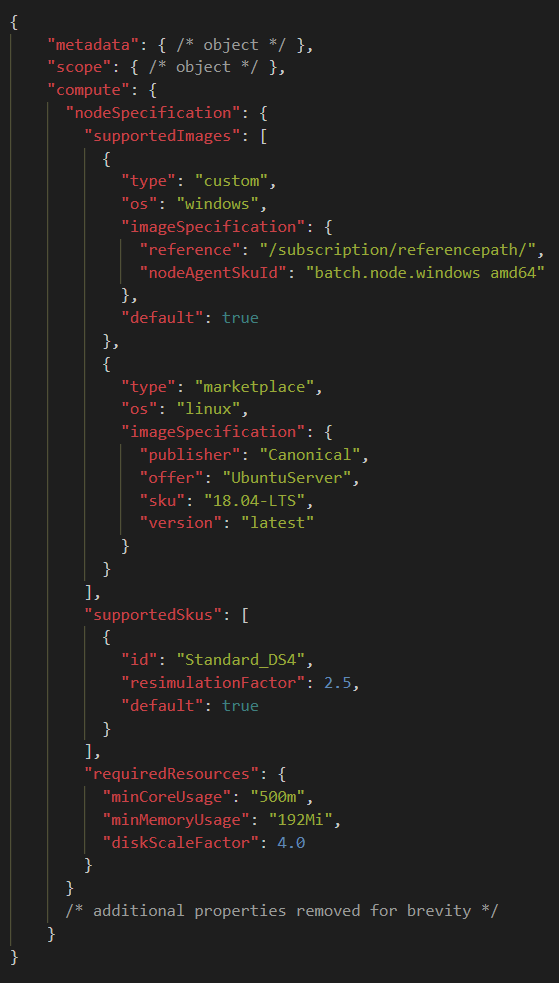
Supplier controlled: configuration via JSON file suppliers have full control over the environment, VM type, OS and SKU hosting their sensor software. Individual configurations for each PO can be provided in the form of a JSON document. It is possible to use marketplace or custom VM images, and the configuration allows constraints for SKUs and CPU, Disk, and Memory usage. Because of this, the execution platform is OS independent and can run both Windows and Linux machines.
- Automatable Environment: the configuration also allows the engineers to provide a list of dependencies and software packages that are used by a PO. The system will ensure those packages are available to the PO at runtime in a predefined location. The POs and their accompanying software packages can be managed and uploaded via a CLI and an Azure Function endpoint, protecting the backend storage by not exposing it publicly.
- Technology agnostic: there are very few technology constraints, as POs can be written in any language such as .NET, Java, Python, shell script, or other options. The VMs images can be configured to support any required technology stack or framework.
- Arbitrary Re-Sim Graphs: users can use the web portal to create large and complex graphs. The web-portal allows the user to manage POs, connect them together via their input and output pins, and split and join the data streams across the POs. All metadata for POs and Graphs is stored in a dedicated Azure Cosmos DB instance.
- Traceable and Secure: re-sim runs are auditable and traceable end-to-end. The original user identity token is encrypted and managed for the lifetime of the Re-Sim job in a safe and secure way by leveraging Azure Key Vault.
- Integrated: input, output, and intermediate data are stored in a specialized data lake, which handles the large volumes of data. The system provides a set of APIs that allow the POs to query specific sets of sensor data in a consistent way.
- Scalable: a compute cluster is created on demand and is automatically deleted once finished. In general, Re-Sim uses an input-based scaling approach to achieve the embarrassingly parallel execution. This means the solution scales data input files across nodes, but the solution does not distribute work of one large input across nodes.
- Optimized Streaming: the solution supports ADTF3, which supports a data chunk streaming protocol. Compute services can start immediately when the first bytes of data arrive rather than waiting for large I/O jobs to finish. The data is read in chunks, which limits the amount of bandwidth required and time it takes to retrieve data from the specialized data lake. This ensures that the assigned hardware resources (network, disk, CPU, and memory) can be utilized to the max while performing several tasks in parallel. This is an important differentiator to competing Re-Sim solutions.
- Observable: the system was implemented with state-of-the-art observability patterns and dashboards using Application Insights/Azure Monitor, and job data and KPIs are exposed in accessible Azure Workbooks dashboards. Each Re-Sim job can be monitored end-to-end. For example, the PO engineers are alerted when a PO is malfunctioning and can see the full stack of traces to identify problem areas. The observability features were built side-by-side with the customer to ensure the right data is exposed at the right times.
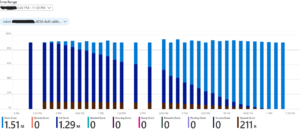
Azure Workbook: task status over time – this graph shows the status of ±90000 tasks running over a period of 6 hours
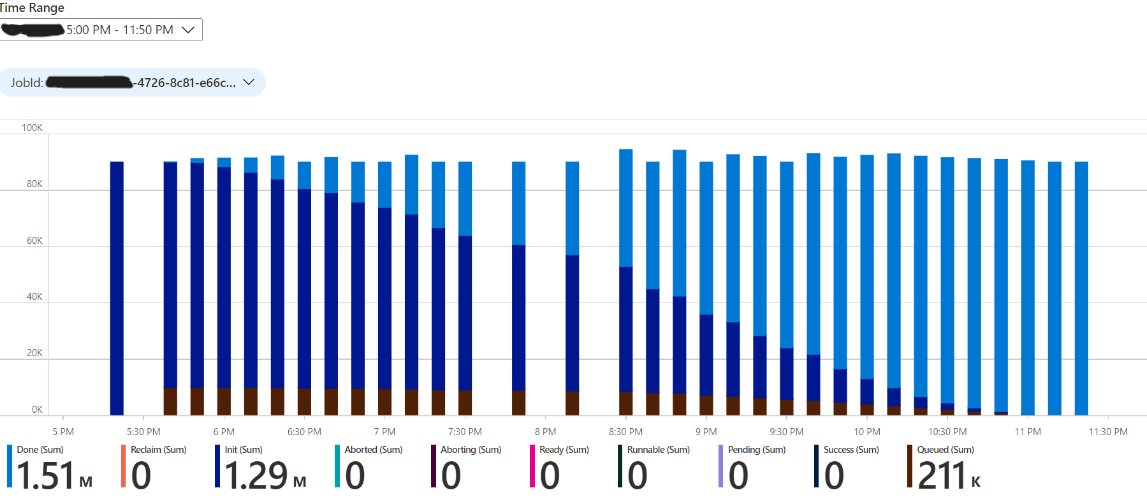
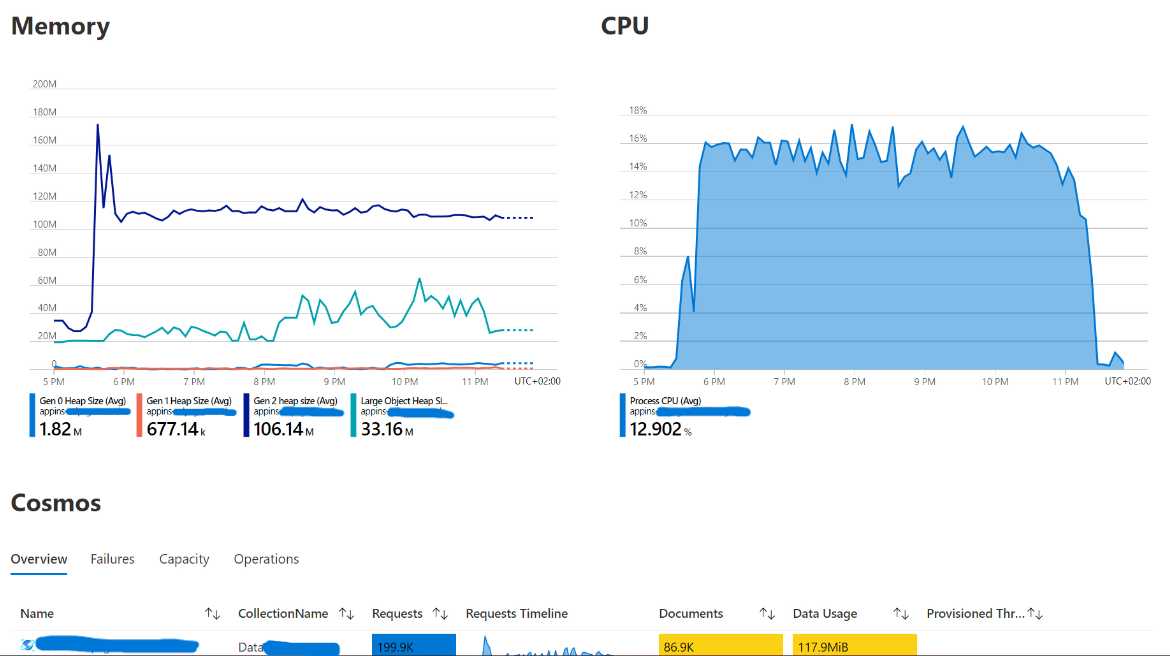
Conclusion
When “Full Self Driving” cars will be a reality is unclear, but the progress being made by various companies on Automated Driving is promising. However, it is clear that a lot of effort and money need to be spent on infrastructure and computing systems to support these functionalities. This article only shows a glimpse of the current and future challenges of the car manufacturers, but it is a step in the right direction. The solution presented here is an additional step on that path.
Further reading
- Wikipedia
- Azure
- ADTF 3 – Automotive Data and Time-Triggered Framework
Acknowledgements
Contributors to the solution from the Microsoft team listed in alphabetical order by last name: Atif Aziz, Bastian Burger, Roel Fauconnier, Alexandre Gattiker, Spyros Giannakakis, Marc Gomez, Oliver Lintner, Daniele Antonio Maggio, Maggie Salak and Patrick Schuler.
Thanks to Patrick Schuler and Tito Martinez for the in-depth reviews of this article.
 Light
Light Dark
Dark