
Reproducible Data Science – Analysis of Experimental Data with Pachyderm and Azure
Inside a nondescript building in a Vancouver industrial park, General Fusion is creating something that could forever change how the world produces energy. Since its founding in 2002, the Canadian cleantech company has risen to the forefront of the race to harness fusion energy which has the potential to supply the world with almost limitless, clean, safe, and on-demand energy. General Fusion’s approach, called magnetized target fusion, involves injecting a ring of superheated hydrogen gas (plasma) into an enclosure, then quickly collapsing the enclosure. The compression of the plasma ignites a reaction that produces a large amount of energy with only helium as a byproduct.
General Fusion operates several plasma injectors which superheat hydrogen gas to millions of degrees, creating a “compact toroid plasma” — a magnetized ring of ionized gas which lasts for a few milliseconds and is the fuel for a fusion energy power plant. A single plasma injector fires hundreds of such shots in a day, each shot generating gigabytes of data from sensors measuring things like temperature, density, and magnetic field strength. Through an iterative process, plasma physicists at General Fusion analyze this data and adjust their experiments accordingly with the goal of creating the world’s first fusion power plant.
With over one hundred thousand plasma shots spanning seven years, their total data set is approaching 100TB in size. General Fusion’s existing on-premise data infrastructure was limiting their ability to effectively analyze all of this data. To ensure that full scientific use could be made of this data, they were in need of a data platform that could:
- Enable big data analytics across thousands of experiments and terabytes of data
- Reliably produce data and analysis when sensor calibrations or algorithms are updated
- Preserve different versions of results for different versions of calibrations or algorithmns
- Enable collaboration with other plasma physicists and the sharing of scientific progress
- Scale as the quantity of data increases
Engineers at General Fusion were quickly drawn to a data platform that met all their requirements: Pachyderm. Pachyderm is an open source data analytics platform that is deployed on top of Kubernetes, a container orchestration framework. We partnered with General Fusion to develop and deploy their new Pachyderm-based data infrastructure to Microsoft Azure. This post walks through General Fusion’s new data architecture and how we deployed it to Azure.
Background
Pachyderm offers a modern alternative to Hadoop and other distributed data processing platforms by using containers as its core processing primitive. In comparison to Hadoop where MapReduce jobs are specified as Java classes, Pachyderm users create containers to process the data. As a result, users can employ and combine any tools, languages, or libraries (e.g. R, Python, OpenCV, CNTK, etc.) to process their data. Pachyderm will take care of injecting data into the container and parallelizing the workload by replicating the container, giving each instance a different set of the data to process.
Pachyderm also provides provenance and version control of data, allowing users to view diffs and promote collaboration with other consumers of the data. With provenance, data is tracked through all transformations and analyses. This tracking enables data to be traced as it travels through a dataflow and allows for a dataflow to be replayed with its original inputs to each processing step.
Pachyderm itself is built on top of Kubernetes and deploys all of the data processing containers within Kubernetes. Originally developed by Google and hosted by the Cloud Native Computing Foundation, Kubernetes is an open sourced platform for managing containerized applications. Kubernetes deploys any number of container replicas across your node cluster and takes care of, among other things, replication, auto-scaling, load balancing, and service discovery.
Requirements
In addition to the node resources given by the Kubernetes cluster, Pachyderm requires:
- Azure Blob Storage for its backing data store
- A data disk for a metadata store
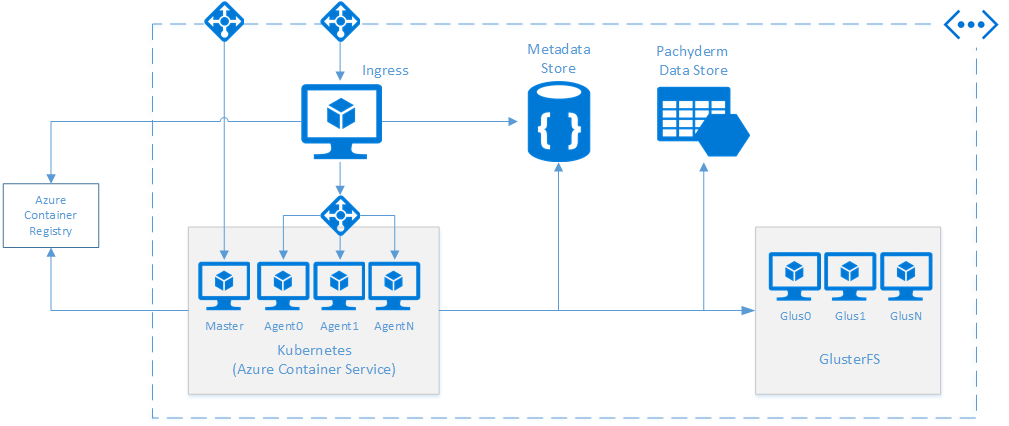
Shown below is a diagram of General Fusion’s infrastructure. In addition to the resources listed above, deployed within the same virtual network are:
- An ingress virtual machine running General Fusion’s custom applications that push plasma injector data into Pachyderm
- DocumentDB used by General Fusion’s custom application to store metadata
- Software load balancers (L4) exposing the Kubernetes master node and the ingress virtual machine to the public Internet and an internal load balancer for the Kubernetes agent nodes.
Instead of the data disk needed for Pachyderm, we have chosen to provision a GlusterFS cluster for higher availability. As a data disk can only be mounted to a single node at a time, downtime with that node would result in an outage to the metadata store until Kubernetes can move the workload to another node. For simplicity, the following blog post will explain deployment using a data disk for Pachyderm’s metadata store.
To get started with deploying Kubernetes and Pachyderm on Azure, first ensure that you have the following tools:
- Microsoft Azure subscription
- Azure CLI > 0.10.7 – command line interface for accessing Microsoft Azure
- Docker CLI > 1.12.3 – command line interface for Docker
- jq – lightweight and flexible command-line JSON processor
- pachctl – command line interface for Pachyderm
Setup and Preparation
Kubernetes
The easiest method to deploy Kubernetes on Microsoft Azure is through the Azure Container Service. As this is well covered in their documentation, we’ll leave it to you to provision a Kubernetes cluster.
Pachyderm
Azure Storage Account
Let’s start by provisioning an Azure Storage Account through the CLI:
AZURE_RESOURCE_GROUP="pachyderm-rg "
AZURE_LOCATION="westus2"
AZURE_STORAGE_NAME="pachydermstrg"
azure storage account create ${AZURE_STORAGE_NAME} --location ${AZURE_LOCATION} --resource-group ${AZURE_RESOURCE_GROUP} --sku-name LRS --kind Storage
Data Disk
Unfortunately, there is currently no capability to create an empty, unattached data disk; in the meantime, we’ll need a workaround. I’ve created a Docker image to help with creating and formatting a data disk and uploading it to Azure Storage; the entire process takes about 3 minutes for a 10GB data disk.
CONTAINER_NAME="pach"
STORAGE_NAME="pach-disk.vhd"
STORAGE_SIZE="10"
AZURE_STORAGE_KEY=`azure storage account keys list ${AZURE_STORAGE_NAME} --resource-group ${AZURE_RESOURCE_GROUP} --json | jq .[0].value -r`
docker run -it jpoon/azure-create-vhd ${AZURE_STORAGE_NAME} ${AZURE_STORAGE_KEY} disks ${STORAGE_NAME} ${STORAGE_SIZE}G`
Deploy Pachyderm
Deploying Pachyderm is a one-line command through pachctl:
pachctl deploy microsoft ${CONTAINER_NAME} ${AZURE_STORAGE_NAME} ${AZURE_STORAGE_KEY} "${STORAGE_VOLUME_URI}" "${STORAGE_SIZE}"
Altogether, here’s what the script and the output of the script looks like:
#!/bin/bash
# ----------------------
# Deploy Pachyderm on Microsoft Azure
# https://gist.github.com/jpoon/c4b781c5eeb395b9ea8452b42cb993a4
# ----------------------
# Parameters
# -------
AZURE_RESOURCE_GROUP="my-resource-group"
AZURE_LOCATION="westus2"
AZURE_STORAGE_NAME="mystrg"
CONTAINER_NAME="pach"
STORAGE_NAME="pach-disk.vhd"
STORAGE_SIZE="10"
# Helpers
# -------
exitWithMessageOnError () {
if [ ! $? -eq 0 ]; then
echo "An error has occurred during deployment."
echo $1
exit 1
fi
}
hash azure 2>/dev/null
exitWithMessageOnError "Missing azure-cli, please install azure-cli, if already installed make sure it can be reached from current environment."
hash docker 2>/dev/null
exitWithMessageOnError "Missing docker, please install docker, if already installed make sure it can be reached from current environment."
hash pachctl 2>/dev/null
exitWithMessageOnError "Missing pachctl, please install pachctl, if already installed make sure it can be reached from current environment."
# Print Versions
# -----
echo -n "Using azure-cli "
azure -v
echo -n "Using docker "
docker -v | awk '{print $3}' | sed '$s/.$//'
echo -n "Using pachctl "
pachctl version | awk 'NR==2{print $2}'
# Create Storage
# -------
echo --- Provision Microsoft Azure Storage Account
azure config mode arm
azure group create --name ${AZURE_RESOURCE_GROUP} --location ${AZURE_LOCATION}
azure storage account create ${AZURE_STORAGE_NAME} --location ${AZURE_LOCATION} --resource-group ${AZURE_RESOURCE_GROUP} --sku-name LRS --kind Storage
AZURE_STORAGE_KEY=`azure storage account keys list ${AZURE_STORAGE_NAME} --resource-group ${AZURE_RESOURCE_GROUP} --json | jq .[0].value -r`
# Create Data Disk
# -------
echo --- Create Data Disk
STORAGE_VOLUME_URI=`docker run -it jpoon/azure-create-vhd ${AZURE_STORAGE_NAME} ${AZURE_STORAGE_KEY} disks ${STORAGE_NAME} ${STORAGE_SIZE}G`
echo ${STORAGE_VOLUME_URI}
# Deploy Pachyderm
# -------
echo --- Deploy Pachyderm
pachctl deploy microsoft ${CONTAINER_NAME} ${AZURE_STORAGE_NAME} ${AZURE_STORAGE_KEY} "${STORAGE_VOLUME_URI}" "${STORAGE_SIZE}"
echo --- Done 
Azure Resource Manager (ARM) Templates
To further simplify deployment, we worked with General Fusion to build ARM templates capable of provisioning the necessary resources and deploying the required applications through a one-line command.
Using Pachyderm
When deploying a Kubernetes cluster through Azure Container Service, only the master node is exposed by default to the public internet. To access Pachyderm from your local developer machine, we will either need to set up port forwarding with pachctl portforward & or expose Pachyderm to the outside world through a public load balancer. In General Fusion’s scenario, as the ingress virtual machine rests in the same virtual network, it can communicate to Pachyderm through the internal load balancer resting on top of the Kubernetes agent nodes.
Once your newly provisioned Pachyderm cluster is accessible, you can test the connection using:
$ pachctl version COMPONENT VERSION pachctl 1.3.4 pachd 1.3.4
pachctl is the current version running of the Pachyderm CLI tool on your local machine, and pachd is the version of the Pachyderm server daemon running in the cluster.
Conclusion
Since General Fusion’s on-premise data system was reaching its limits, their move to a Pachyderm-based data platform on Microsoft Azure has accelerated their ability to process and analyze experimental data. General Fusion’s initiative demonstrates a growing importance across the industry for data provenance and versioning.
Furthermore, the use of a container-based architecture in Pachyderm and Kubernetes has allowed General Fusion to develop their scientific analysis framework agnostic of data platform. Native support of Kubernetes in Azure Container Service has simplified their deployment process, allowing General Fusion to focus on producing and analyzing experimental plasma data rather than maintaining the infrastructure. The ability to analyze their data more effectively will help General Fusion to achieve their goal of creating clean energy, everywhere, forever.
Opportunities for Reuse
General Fusion’s architecture can serve as an example of how one would deploy and use Pachyderm on Microsoft Azure. Instructions for deploying Pachyderm to Microsoft Azure are also available through Pachyderm’s documentation.
 Light
Light Dark
Dark
0 comments