
Object Detection Using Microsoft CNTK
We recently collaborated with InSoundz, an audio-tracking startup, to build an object detection system using Microsoft’s open source deep learning framework, Computational Network Toolkit (CNTK).
The Problem
InSoundz captures and models 3D audio of live sports events to enhance live video feeds of these events for fans. In order to enable automatic discovery of interesting scenarios that would be relevant to their solution, InSoundz wanted to integrate object detection capabilities into their system.
Any solution needed to be as flexible as possible, and also had to support adding new object types and creating detectors for various data types with ease. Since the object detection component evaluates images from a live camera feed, the detection also had to be fast, with near real-time performance.
Object Detection vs. Object Recognition
Often when people talk about “object detection,” they actually mean a combination of object detection (e.g. where is the cat/dog in this image?) and object recognition (e.g. is this a cat or a dog?). That is, they mean that the algorithm should solve a combination of two problems: detecting both where there is an object in a given image, then recognizing what that object is. In this post, we will use this more common definition.
In practice, the task of finding where an object is translates to finding a small bounding box that surrounds the object. While the tasks of recognition and object detection are both well-studied in the domain of computer vision, up until recently they were mainly solved using “classic” approaches. These methods utilized local image features like Scale Invariant Feature Transform (SIFT) and Histogram of Oriented Gradients (HOG).
Classic algorithms for pedestrian detection, for example, scan different regions in an image using a grid-like approach. They use the HOG features of the region and a pre-trained linear classifier, like a support vector machine (SVM), and decide which region contains an image of a pedestrian.
In recent years, however, deep learning methods like convolutional neural networks (CNNs) have become the prominent tool for object recognition tasks. Due to their outstanding performance in comparison to the classical methods, deep learning methods also became a popular tool for object detection based tasks.
The Solution
One such deep learning-based method for object detection is the Fast-RCNN algorithm. Ross Girschik developed the method during his time in MSR and it is considered to be one of the top methods in the field of object detection and recognition. In our solution, we utilized the CNTK implementation of the Fast-RCNN algorithm.
The Fast-RCNN method for object detection provides the following possible capabilities:
- Train a model on arbitrary classes of objects, utilizing a transfer learning approach. This method takes advantage of existing object recognition solutions to train the neural network.
- Evaluate large numbers of proposed regions simultaneously and detect objects in those regions.
A schema describing the Fast-RCNN algorithm is illustrated in the image below:
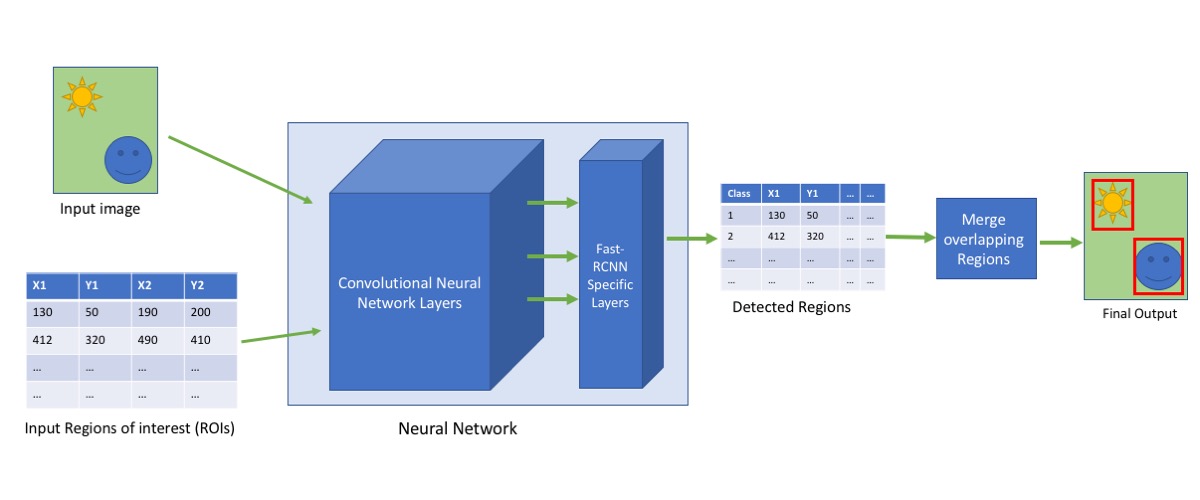
Next, we describe the two steps in building our solution: how we train the neural network model, and how we use the model for object detection.
Training the model
For the technical part of training a Fast-RCNN model with CNTK, please refer to this tutorial, which will walk you through setting up your model.
The input of the training procedure is a dataset of images, where each image has a list of bounding boxes associated with it, and each bounding box has an associated class.
For InSoundz, the input data was composed of several video files with no bounding box labels.
In order to allow InSoundz to prepare the training data with ease, we developed a video tagging tool. Our tool supports the ability to export the tagged images to the CNTK training format, as well as the ability to assess the performance of existing models. For more information about the tool, please refer to the related Real Life Code Story.
While the training process is rather straightforward, there are still a few things to consider when tuning the parameters of the model:
Number of Region of Interest (ROIs)
This setting defines the number of regions that will be considered as the potential location of objects in the input image.
While the default setting in the CNTK implementation defines 2000 ROIs for an image, this number can be tuned. A higher number can result in the model considering more regions, which increases the accuracy of detection. A larger number of regions, however, will result in longer training (and testing) times for the model. Decreasing the number of ROIs can help achieve shorter training and testing times, but can cause an overall decrease in the accuracy of the model.
In our experiments, we found that setting this value to 1500 ROIs lead to reasonable detection results.
Image Size
Since convolutional neural networks have a fixed input size, each image should be resized to a pre-defined size that the network expects. Similar to the number of ROIs, larger images can result in higher accuracy of detection but longer training and testing times. While using smaller images can result in shorter training and testing times, it can lower detection accuracy. In our tests, we used an image size of 800×800.
All of the parameters of the model can be easily set by changing the appropriate values in the file PARAMETERS.py.
Object Detection with the CNTK Model
While the CNTK training procedure also contains a built-in evaluation procedure for a given test set, the user of the model will most likely want to use the model performance object detection on new images that aren’t part of the training or test set.
To use the model on a single image, the following operations should be performed for each:
- Resize the image to the expected input size. The resizing should be performed according to one of the image’s axes to preserve the aspect ratio. Then, the resized image should be padded to fit the neural network input size.
- Calculate the candidate ROIs for detection. While a gridlike method can produce identical ROIs for different images, using other methods like Selective Search will most likely result in having different ROIs for different images.
- Run the resized image, together with the candidate ROIs, through the trained Neural Network. As a result, each ROI is assigned a predicted class (or object type), with a special “background” class in case no object was recognized.
- Finally, run the ROIs that were identified as containing an object through the Non-Maximum-Suppression algorithm, so overlapping regions are unified to produce the final bounding boxes for detected objects.
A detailed walkthrough of the above pipeline is available in a Python notebook.
In addition, a full Python implementation is available on GitHub. The code in this repository exposes an FRCNNDetector class that can be used to load a trained Fast-RCNN CNTK model and evaluate it on images.
The following code sample demonstrates how the FRCNNDetector object encapsulates the steps described above into a single call of the detect method.
import cv2
from os import path
from frcnn_detector import FRCNNDetector
cntk_scripts_path = r'C:localcntkExamplesImageDetectionFastRCNN'
model_file_path = path.join(cntk_scripts_path, r'proc/grocery_2000/cntkFiles/Output/Fast-RCNN.model')
# initialize the detector and load the model
detector = FRCNNDetector(model_file_path, cntk_scripts_path=cntk_scripts_path)
img = cv2.imread(path.join(cntk_scripts_path,'r../../DataSets/Grocery/testImages/WIN_20160803_11_28_42_Pro.jpg')
rects, labels = detector.detect(img)
# print detections
for rect, label in zip(rects, labels):
print("Bounding box: %s, label %s"%(rect, label))
In the code sample shown above, an instance of an FRCNNModel class is created and the model is called for detection on a single image. The resulting bounding boxes and their corresponding labels are then printed to the screen.
Note that the only parameters required to instantiate the FRCNNModel class are the location of the model file and the location of the CNTK Fast-RCNN Scripts.
The ROI calculation step uses a caching mechanism when using a grid method to calculate ROIs, which allows for even shorter image evaluation times. If the user of the FRCNNDetector object chooses to disable the calculation of ROIs using selective search (and only uses grids), the evaluation times become much shorter since the grid is only calculated once and then the ROIs are re-used.
In addition to the Python implementation mentioned above, we have also released a Node.js wrapper that exposes the Fast-RCNN detection capabilities for Node.js and Electron developers. For more info, please visit the node-cntk-fastrcnn code repository.
Opportunities for Reuse
In this case study, we described how we built an object detection model using the CNTK implementation of the Fast-RCNN algorithm. As demonstrated above, the algorithm is generic and can be easily trained on different datasets and various classes of objects.
We hope that this write-up, as well as the accompanying code, can benefit other developers looking to build their own object detection pipelines.
 Light
Light Dark
Dark
0 comments