
Building a Low Latency Smart Conversational Client
Image: Sewer_Plant used by CC BY-SA 2.0
Background
Voice and natural language provide a level of personalization and comfort that leads to increased trust and productivity.
As part of its cognitive services, Microsoft currently offers LUIS, a natural language intent recognition service, that converts natural language text into structured intents.
The Problem
One of the largest existing barriers to natural conversation processing is the latency caused by network lookups and a dependency on being online.
We recently partnered with the R&D department of Roboteam, an innovative global robotics company, that required natural language processing capabilities for its robots. Roboteam was interested in using LUIS on Android to address this need, but required low latency and offline support to provide natural interaction to its users.
The goal of the collaboration was to support Roboteam’s need by providing an end to end open source smart conversational framework, that enables low latency voice interaction, using Microsoft’s intent recognition technologies and a local smart cache.
Overview of the Solution
We developed the “Smart Conversational Client”, a framework that enables client side caching and offline support for LUIS.
Our implementation of the Smart Conversational Client enables the following capabilities:
- Online/Offline Speech to Text
- Online/Offline Natural Text to Intent
- Local Intent Recognition for faster look up
- Knowledge Graph Integration Interface
Smart Conversational Client Architecture
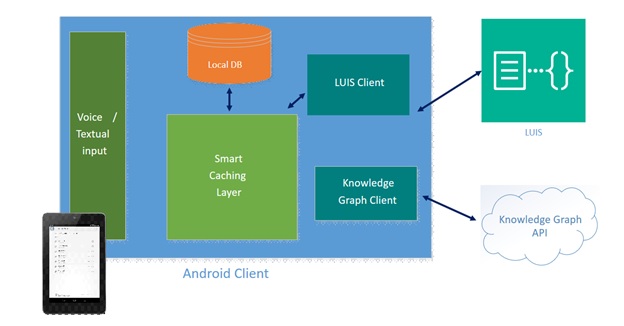
- Voice/Text InputThe speech to text mechanism in our demo application uses the Android Speech API. The API provides low latency online and offline speech to text. However, unlike the UWP offering the API does not support continuous recognition. Once a user’s speech is converted to text, the text is passed to our smart conversational controller for processing.
- Smart Caching LayerThe smart caching layer is a persistent cache that combines disk and memory for optimized lookups. When the smart cache is initialized it pulls a set number of values from disk to memory for optimized lookups and generates key rules from known values in the persistent DB layer.The smart caching logic executes the following sequential flow until a result is found:
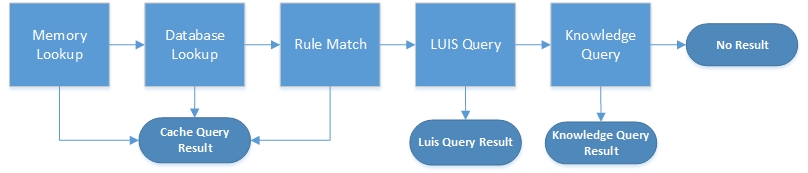
- In Memory look up– Check the in memory segment of the cache to see if the query string is a key and if so return the cached value.
- DB look up– Check the persistent DB segment of the cache to see if the query string is a key and if so return the cached value.
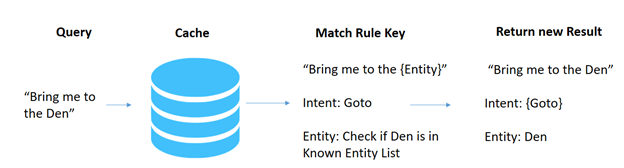
- Generalized rule look up– Check if the query string matches a key rule and if so extract the known intents and entities from the string.Rule extraction performs as follows.
- LUIS Query & Async Cache Insertion– Query LUIS endpoint, asynchronously cache the response and generate rule, then return response to user.Rule generation performs as follows:

- Knowledge Graph Query– Send the query to the associated knowledge graph and return the knowledge graph result.
- Persistent DB LayerThe smart cache sits on top of a local persistent database layer. In our implementation we used SnappyDB, an open source low latency key value database. To allow for extensibility we provide a Persistent DB interface that allows for anyone to use alternative persistent database methods such as SQLite or Realm. One requirement of the PersistentDB interface is that DBValues are serialized in JSON to provide for increased compatibility
- LUIS ClientIn order to enable intent recognition, users of the system must train a model with the Luis portal. For an introduction on how to train a Luis Model please watch the following video.Our smart conversational controller consumes this model using the LUIS Programmatic API using the performant Volley HttpClient and Jackson to parse the JSON response into android objects.
- Knowledge Graph SupportTo provide for general knowledge questions we provide integration to a KnowledgeGraph Interface. The key requirement for implementing the knowledge graph interface is to convert a Query String into a IKnowledgeQuery Result. An IKnoweldgeQuery result must contain the original query string as well as method that generates a spoken text string from which ever knowledge graph it sits upon.
Performance
When combined with a trained LUIS model our smart conversational client provides an end to end framework for integrating low-latency voice and natural language processing in applications. The project provides a large processing speed up over traditional conventional server side approaches with up to a 54x performance increase.
The table below shows the mean, median and max bound recall times on 100 runs in milliseconds
| Mean | Median | Max | Min | |
|---|---|---|---|---|
| LUIS Client | 407.38 | 479 | 4,402 | 54 |
| General Cache | 296.01 | 124.5 | 1,109 | < 1 |
| Exact Cache | 17.94 | < 1 | 123 | < 1 |
Opportunities for Reuse
This client is perfect for conversational IoT and bot based scenarios where latency has a big impact on overall user experience and some level of offline support is often required.
All the code is open sourced and can be found on github here.
 Light
Light Dark
Dark
{kind=link}
0 comments