
Extracting XML Data from HDFS Sequence Files
A partner we work with collects large quantities of diagnostic data from a wide range of devices. Periodically, each device transmits its state as an XML file. These XML files are archived on a Hadoop cluster as compressed sequence files. The goal of the project was to efficiently extract specific attributes and elements from the archive and use them for further processing, such as predictive analytics using Microsoft Azure Machine Learning. Less than 0.001% of the device data needs to be extracted from these models, making it impractical and inefficient to parse each document using XML DOM or SAX.
In this paper, you will learn how to implement a MapReduce job to efficiently extract XML data from HDFS sequence files using a custom RecordReader.
Overview of the Solution
To avoid the performance penalty of loading and parsing the complete XML document, we created a custom record reader that implements a scanner to search the raw byte stream for specific XML nodes to extract. These extracted nodes provide the input data for the map job, which then loads the XML fragment into a DOM and runs XPath expressions against it. This allows for an efficient extraction while still providing the use of XPath (the de facto standard) to select the nodes of interest.
An illustrative example is a data scientist who wants to analyze the performance of a particular control unit (e.g. the thermostat) across the last 4 years. The data scientist would define an extraction rule for all thermostats and run the job against the last 4 years of sequence files. The output of this job contains all the thermostat data including additional metadata such as timestamps, location or device identification.
Implementation
The full source code of this solution can be found on GitHub: https://github.com/cloudbeatsch/HadoopXmlExtractor
The class XmlExtractor implements the extraction job (see Figure 1) and takes the following three arguments to run:
- The input path which contains the compressed sequence files (usually one sequence file contains multiple xml files)
- The path where the extracted elements are stored
- The path to the extraction configuration file
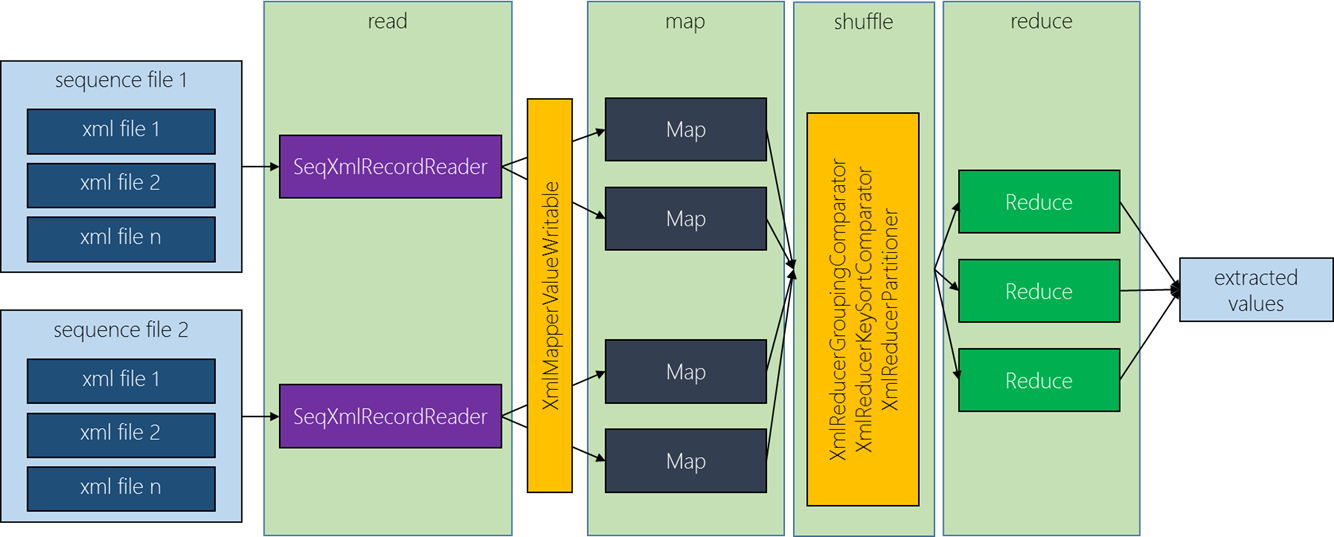
Figure 1: Anatomy of an extraction job
The extraction job reads the sequence files using a custom RecordReader called SeqXmlRecordReader. It reads each xml file as a binary stream and scans it for the requested xml elements. Once a start tag is found, it scans for the corresponding end tag and provides the containing stream (including start and end tags) as the input to the Mapper. If we’re only interested in attributes, we omit the element content and add a matching closing tag without scanning for the corresponding tag in the stream. This reader emits values of type XmlMapperValueWritable, which contains the extracted xml stream, a list of XPath expression the Mapper has to run against that stream as well as information about the current stream position and the final output column number.
The Mapper loads the stream into a DOM and runs the configured XPath expressions against it. For each expression that returns nodes, we create the Mapper output key/value pairs (which are of type XmlReducerKeyWritable and XmlReducerValueWritable respectively):
protected void map(Text key, XmlMapperValueWritable value, Mapper.Context context){
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setNamespaceAware(true);
DocumentBuilder builder = factory.newDocumentBuilder();
// converting to a string to remove trailing non-white space characters because they cause
// a "content is not allowed in trailing section" error
String docString = value.getXmlStream().toString();
Document doc = builder.parse(new ByteArrayInputStream(docString.getBytes("utf-8")));
XPathFactory xpathfactory = XPathFactory.newInstance();
XPath xpath = xpathfactory.newXPath();
// now we iterate across all the XPath expressions for this xmlStream
// and run them against the DOM
for (XPathInfoWritable info : value.getXPathExpressions()){
XPathExpression expr = xpath.compile(info.getExpression());
Object result = expr.evaluate(doc, XPathConstants.NODESET);
NodeList nodes = (NodeList) result;
// in the case we got matching nodes, we create the reducer input
if (nodes.getLength() > 0) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < nodes.getLength(); i++) {
sb.append(nodes.item(i).getNodeValue());
}
XmlReducerKeyWritable xmlKey =
new XmlReducerKeyWritable(key.toString(), value.getSequence(), info.getPos());
context.write(xmlKey, new XmlReducerValueWritable(sb.toString(), info.getPos()));
}
}
}
The output key consists of the triple of file guid, the sequence number and the column order. The output value contains the result of the XPath query and the corresponding column order.
Shuffling takes place between the Mapper output and the Reducer input:
- The custom grouping comparator
XmlReducerGroupingComparatorensures that all records containing the same guid (records from the same xml file) will be processed by the same Reducer. This allows us to correlate different query results into one final row. - The custom sort comparator
XmlReducerKeySortComparatorsorts the records by the input file, the stream position and the column number. This ensures that we assign columns in the same sequence as the files have been processed.
Using the above grouping and sorting, the Reducer can simply iterate across all values and build the output row. This works because all values with the same key are extracted from the same file and sorted in their sequence and their column order:
public void reduce(XmlReducerKeyWritable key,
Iterable<XmlReducerValueWritable> values,
Context context){
String[] theColumns = new String[nrOfColumns];
for (XmlReducerValueWritable value : values) {
theColumns[value.getOrder()] = value.getValue();
// once we got all columns, we write them - this works because
// values are sorted by sequence and then columns
if (value.getOrder() == (nrOfColumns - 1)) {
StringBuilder sb = new StringBuilder();
for (String col: theColumns) {
if ((col != null) && (!col.isEmpty())) {
sb.append(col);
}
else {
sb.append(' ');
}
// writing the column delimiter e.g. t
sb.append(outputDelim);
}
// writing the reducer output
context.write(null ,new Text (sb.toString()));
}
}
Definition of the extraction configuration file
The extraction configuration file configures the scanner, provides the XPath expression and defines the position of the output columns. Below an example configuration which extracts all XML nodes named header:
<property>
<name>headerNode</name>
<value>header;false;true; ;0#//header/onwerId/text();1#//header/specNr/text</value>
</property>
The complete description of the configuration format can be found here, together with two example configurations.
Challenges
The scanner (implemented by SeqXmlRecordReader) does not parse the XML document but only looks for string matches: It scans the document for the occurrence of the tag name (including the start bracket). The same applies for attribute values: It simply searches within the start tag for the occurrence of the specified string.
To ensure configuration simplicity, the current version loads each extracted byte stream (the Mapper input) into a DOM and runs an XPath expressions against it. While this allows users to use XPath as a familiar tool to define the extraction, it also leads to a performance penalty. Depending on the size of the extracted byte stream, the complexity of the DOM or the XPath expression, it is possible to replace this Mapper implementation with one that uses a different extraction rule (e.g. Regular expressions or a SAX based extraction).
Opportunities for Reuse
This XML extraction can be used for any project that requires efficient data extraction from XML files stored in HDFS –without the need for loading the complete files into a DOM. For performance reasons, the current version works with XML files that are compressed as Hadoop sequence files. The SeqXmlRecordReader requires a unique key for each contained file. (CreateSequenceFile is a sample application in the repo that creates a sequence from files contained in folder). It is also be possible to change SeqXmlRecordReader to work with non-compressed XML files.
 Light
Light Dark
Dark
0 comments